







敏感词过滤
更多内容请访问我的个人站点博客。
最近在做一个项目的过程中正好遇到了敏感词过滤这一功能,由于这个功能应用广泛,就记录下来以便日后复习。
设计敏感词过滤可以通过Trie树来实现,即我们所说的前缀树/字典树。
Trie树
Trie树也称为前缀树、字典树,最大的特点就是共享字符串的公共前缀来达到节省空间的目的了。
Trie树的根节点不存任何数据,每整个个分支代表一个完整的字符串。
Trie 树的本质,就是利用字符串之间的公共前缀,将重复的前缀合并在一起。
举个简单的例子来说明一下。
我们有 6 个字符串,它们分别是:how,hi,her,hello,so,see。我们希望在里面多次查找某个字符串是否存在。如果每次查找,都是拿要查找的字符串跟这 6 个字符串依次进行字符串匹配,那效率就比较低,有没有更高效的方法呢?
这个时候,我们就可以先对这 6 个字符串做一下预处理,组织成 Trie 树的结构,之后每次查找,都是在 Trie 树中进行匹配查找。最后构造出来的就是下面这个图中的样子。
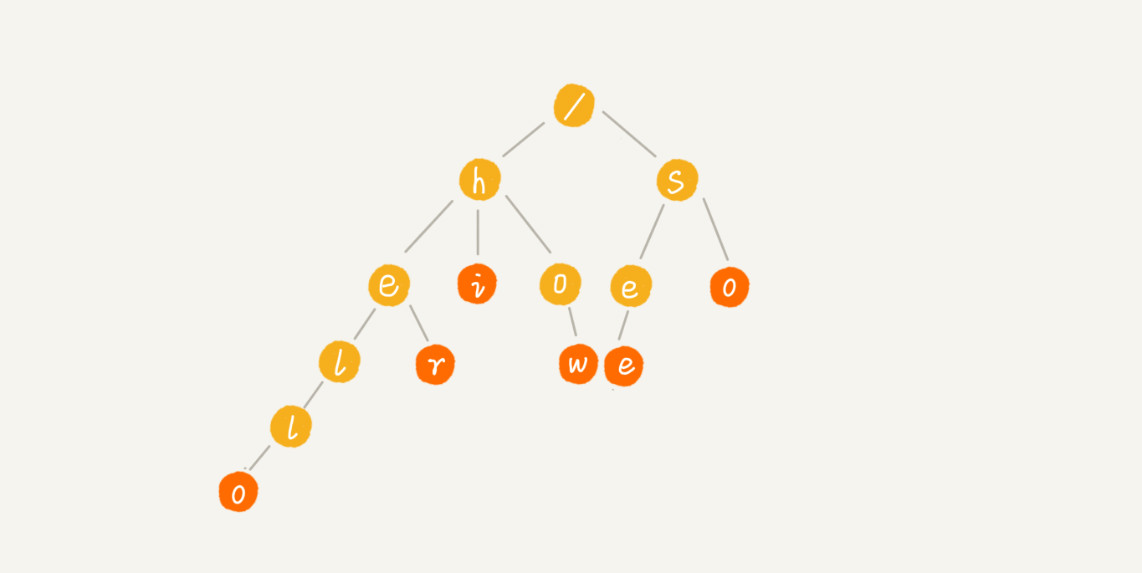
Trie树的应用
Trie树最大的特点就是利用了字符串的公共前缀,当我们在搜索框输入关键词时,搜索框会自动帮我们列举出相关结果:
在设计敏感词过滤的过程中,我们可以这样定义Trie树:
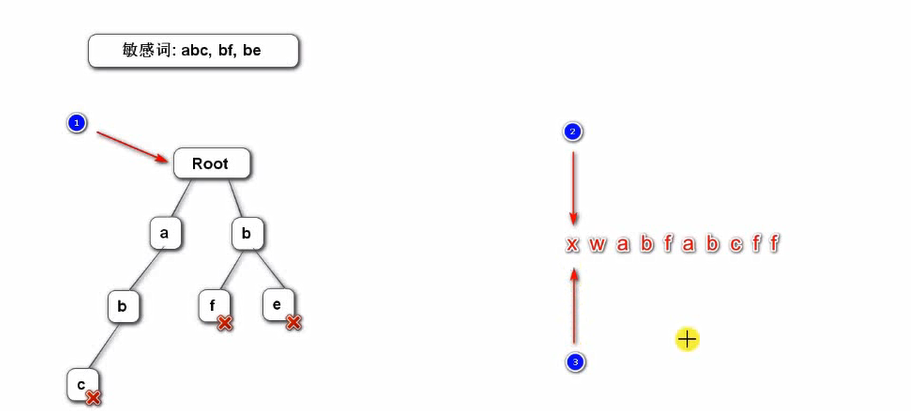
图中的红叉表示标记到这个字符,从root到此字符所经过的字符串是敏感词。
把所有敏感词存入Trie树中,设置三个指针:p1、p2、p3。
其中:p1指向Trie树的根节点,p2和p3指向待过滤的字符数组。
过滤过程
过滤过程为:
-
p1找root下一层有没有与p2指向相同的字符,若没有,p2和p3都向后移动;若有,p1指向那个字符对应的节点,p2不动,p3向后移动,然后重复上述过程。
-
如果p1指向了带标记的节点,那么将p2到p3中间的字符串统一用过滤词如
***代替并存入结果数组中,p2和p3都移动到 p3 + 1的位置;如果没有指向带标记的节点,p2++,p3 == p2。当p3 == 数组长度时,将剩余字符加入结果数组中。
复杂度分析
如果敏感词的长度为 m,则每个敏感词的查找时间复杂度是 O(m),字符串的长度为 n,我们需要遍历 n 遍,所以敏感词查找这个过程的时间复杂度是 O(n * m)。
如果有 t 个敏感词的话,构建 trie 树的时间复杂度是 O(t * m)。
代码实现
这里构建Trie树我们使用HashMap实现,因为一个节点的字节点个数未知,采用 HashMap 可以动态拓展,而且可以在 O(1) 复杂度内判断某个子节点是否存在。
@Component
public class SensitiveFilter {
private static final Logger logger = LoggerFactory.getLogger(SensitiveFilter.class);
private static final String REPLACEMENT = "***";
private TrieNode rootNode = new TrieNode();
private class TrieNode {
// 关键词结束标识
private boolean isKeywordEnd = false;
private Map<Character, TrieNode> subNodes = new HashMap<>();
public boolean isKeywordEnd() {
return isKeywordEnd;
}
public void setKeywordEnd(boolean keywordEnd) {
isKeywordEnd = keywordEnd;
}
// 添加子节点
public void addSubNode(Character c, TrieNode node) {
subNodes.put(c, node);
}
// 获取子节点
public TrieNode getSubNode(Character c) {
return subNodes.get(c);
}
}
@PostConstruct
public void init() {
try (
InputStream is = this.getClass().getClassLoader().getResourceAsStream("sensitive-words.txt");
BufferedReader reader = new BufferedReader(new InputStreamReader(is));
) {
String keyword;
while ((keyword = reader.readLine()) != null) {
// 添加到前缀树
this.addKeyword(keyword);
}
} catch (IOException e) {
logger.error("加载敏感词文件失败: " + e.getMessage());
}
}
private void addKeyword(String keyword) {
TrieNode tmp = rootNode;
for(int i = 0; i < keyword.length(); i++) {
char c = keyword.charAt(i);
TrieNode subNode = tmp.getSubNode(c);
if(subNode == null) {
subNode = new TrieNode();
tmp.addSubNode(c, subNode);
}
tmp = subNode;
if(i == keyword.length() - 1) {
tmp.setKeywordEnd(true);
}
}
}
/**
* 返回过滤后的文本
* */
public String filter(String text) {
if(StringUtils.isBlank(text)) {
return null;
}
TrieNode tmp = rootNode;
int begin = 0;
int position = 0;
StringBuilder sb = new StringBuilder();
while(position < text.length()) {
char c = text.charAt(position);
// 忽略特殊符号
if(isSymbol(c)) {
if(tmp == rootNode) {
sb.append(c);
begin++;
}
position++;
continue;
}
tmp = tmp.getSubNode(c);
if(tmp == null) {
// 以begin开头的字符串不是敏感词
sb.append(text.charAt(begin));
begin++;
position = begin;
tmp = rootNode;
} else if (tmp.isKeywordEnd()) {
sb.append(REPLACEMENT);
position++;
begin = position;
} else {
position++;
}
}
// 将剩下的字符串加入结果中
sb.append(text.substring(begin));
return sb.toString();
}
// 判断是否为符号
// 0x2E80 ~ 0x9FFF 是东亚文字范围
private boolean isSymbol(Character c) {
return !CharUtils.isAsciiAlphanumeric(c) && (c < 0x2E80 || c > 0x9FFF);
}
}















 637
637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









