







storm有两种操作模式: 本地模式和远程模式。
本地模式:你可以在你的本地机器上开发测试你的topology, 一切都在你的本地机器上模拟出来;
远端模式:你提交的topology会在一个集群的机器上执行。
本文以Twitter Storm官方Wiki为基础,详细描述如何快速搭建一个Storm集群,其中,项目实践中遇到的问题及经验总结,在相应章节以“注意事项”的形式给出。
1. Strom集群组件
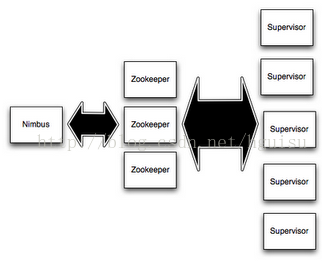
Storm集群中包含两类节点:主控节点(Master Node)和工作节点(Work Node)。其分别对应的角色如下:
1. 主控节点(Master Node)上运行一个被称为Nimbus的后台程序,它负责在Storm集群内分发代码,分配任务给工作机器,并且负责监控集群运行状态。Nimbus的作用类似于Hadoop中JobTracker的角色。
2. 每个工作节点(Work Node)上运行一个被称为Supervisor的后台程序。Supervisor负责监听从Nimbus分配给它执行的任务,据此启动或停止执行任务的工作进程。每一个工作进程执行一个Topology的子集;一个运行中的Topology由分布在不同工作节点上的多个工作进程组成。
Storm集群组件
Nimbus和Supervisor节点之间所有的协调工作是通过Zookeeper集群来实现的。此外,Nimbus和Supervisor进程都是快速失败(fail-fast)和无状态(stateless)的;Storm集群所有的状态要么在Zookeeper集群中,要么存储在本地磁盘上。这意味着你可以用kill -9来杀死Nimbus和Supervisor进程,它们在重启后可以继续工作。这个设计使得Storm集群拥有不可思议的稳定性。
2. Strom集群安装
这一章节将详细描述如何搭建一个Storm集群。下面是接下来需要依次完成的安装步骤:
1. 搭建Zookeeper集群;
2. 安装Storm依赖库;
3. 下载并解压Storm发布版本;
4. 修改storm.yaml配置文件;
5. 启动Storm各个后台进程。
2.1 安装java
安装java:
一、安装
创建安装目录,在/usr/java下建立安装路径,并将文件考到该路径下:
# mkdir /usr/java
1、 jdk-6u13-linux-i586.bin 这个是自解压的文件,在linux上安装如下:
# chmod 755 jdk-6u13-linux-i586.bin
# ./ jdk-6u13-linux-i586.bin (注意,这个步骤一定要在 jdk-6u13-linux-i586.bin所在目录下)
在按提示输入yes后,jdk被解压。
出现一行字:Do you aggree to the above license terms? [yes or no]
安装程序在问您是否愿意遵守刚才看过的许可协议。当然要同意了,输入"y" 或 "yes" 回车。
二、配置
#vi /etc/profile
在里面添加如下内容
export JAVA_HOME=/usr/java/jdk1.6.0_13
export JAVA_BIN=/usr/java/jdk1.6.0_13/bin
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export JAVA_HOME JAVA_BIN PATH CLASSPATH
让/etc/profile文件修改后立即生效 ,可以使用如下命令:
# . /etc/profile
注意: . 和 /etc/profile 有空格.
重启测试
java -version
屏幕输出:
java version "jdk1.6.0_02"
Java(TM) 2 Runtime Environment, Standard Edition (build jdk1.6.0_02)
Java HotSpot(TM) Client VM (build jdk1.6.0_02, mixed mode)
问题:
1)安装jdk,而不是jre啊,jre没有javac
如果使用yum install java 安装,没有安装javac的。
Exception in thread "main" java.lang.UnsupportedClassVersionError
2.1 搭建Zookeeper集群
Storm使用Zookeeper协调集群,由于Zookeeper并不用于消息传递,所以Storm给Zookeeper带来的压力相当低。大多数情况下,单个节点的Zookeeper集群足够胜任,不过为了确保故障恢复或者部署大规模Storm集群,可能需要更大规模节点的Zookeeper集群(对于Zookeeper集群的话,官方推荐的最小节点数为3个)。在Zookeeper集群的每台机器上完成以下安装部署步骤:
1. 根据Zookeeper集群的负载情况,合理设置Java堆大小,尽可能避免发生swap,导致Zookeeper性能下降。保守起见,4GB内存的机器可以为Zookeeper分配3GB最大堆空间。
2. 下载后解压安装Zookeeper包,官方下载链接为http://hadoop.apache.org/zookeeper/releases.html。
3. 根据Zookeeper集群节点情况,在conf目录下创建Zookeeper配置文件zoo.cfg:
| tickTime=2000 dataDir=/var/zookeeper/ clientPort=2181 initLimit=5 syncLimit=2 server.1=zoo1:2888:3888 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888 |
其中,dataDir指定Zookeeper的数据文件目录;其中server.id=host:port:port,id是为每个Zookeeper节点的编号,保存在dataDir目录下的myid文件中,zoo1~zoo3表示各个Zookeeper节点的hostname,第一个port是用于连接leader的端口,第二个port是用于leader选举的端口。
4. 在dataDir目录下创建myid文件,文件中只包含一行,且内容为该节点对应的server.id中的id编号。
5. 启动Zookeeper服务:
| java -cp zookeeper.jar:lib/log4j-1.2.15.jar:conf \ org.apache.zookeeper.server.quorum.QuorumPeerMain zoo.cfg |
或者
| bin/zkServer.sh start |
6. 通过Zookeeper客户端测试服务是否可用:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3087
3087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









