







有个业务需要大量存取增删非重复数据,原实现逻辑是使用set的数据结构。set结构本质上是用erlang实现的,对数据哈希后结合tuple和list的一层包装,set出生在erlang还没有maps结构时的早期版本,用以比单独的list结构更高效的解决集合问题。maps结构出现后,能否高效的替代掉set呢?下面做一些对比:
增操作:

时间消耗差了一个数量级
查操作:

删操作:

耗时方面,maps全面碾压set。但maps也有缺点,在空间占用上:

maps方式占用空间略大的原因是多存储了null这个值
我们从sets:add_element的实现着手看看其慢的原因:
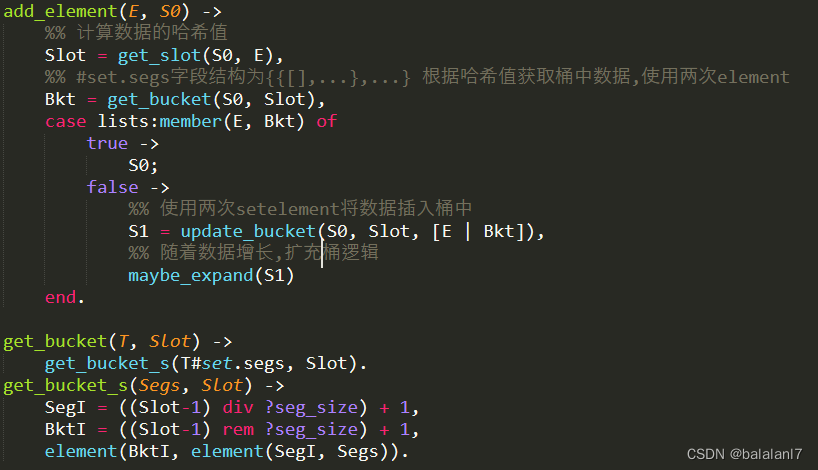

从上面的代码解析可以看出,插入操作主要耗时在扩充桶时的rehash处理,会取出某一个桶中的数据全部重新插入一次。
那么触发rehash的频率高么?
从逻辑中可以看出, 每当size字段达到expsize时便会触发rehash,触发后n字段增加1, expsize修改为5*(n+1)。
size初始值为0,expsize初始值为80,n初始值16
当size增长为81触发增长时,可以计算出下次触发增长的 expsize 为 (16+1)*5 = 85,n+=1 为 17。
也就是再插入5个新数据,就需要触发增长。
当size增长为86触发增长时,可以计算出下次触发增长的 expsize 为 (17+1)*5 = 90,n+=1 为 18。
也就是再插入5个新数据,就又需要触发增长。
总结规律我们可以得出:
每插入5个数据就需要触发一次增长逻辑,对某一个桶的所有值重新进行rehash。
前面的测试数据量为600*1200=720000,大约会触发 720000/5 = 144000 次增长逻辑,这大概就是sets耗时长的原因了。
我们稍微调整一下增长的频率,
方案一,源码逻辑,每插入五项新数据,触发增长逻辑
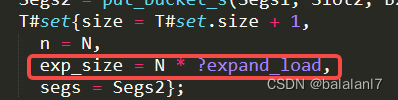
测试结果:

方案二,每插入当前激活桶数项新数据,触发增长逻辑
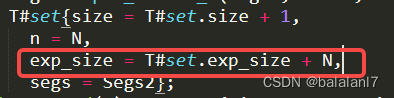

耗时更长,因为虽然增长频率降低了,但是单次增长需要处理的rehash数据量变多了。
如当前测试用例,72w项数据时,激活的桶数为1200,平均每个桶中存放了600项数据,是方案一平均每个桶中5项数据的120倍。
除了使用sets和maps外,还有别的可替换方案么?来试试ets

耗时稍优于maps的实现;
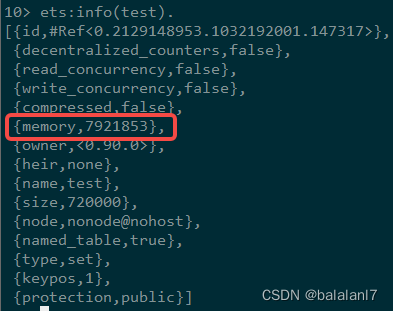
但是内存占用逊色于maps的实现















 1511
1511











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









