







前言
机器学习第二个基础的算法。跟上一篇博客类似这一遍博客会深入讨论线性回归的细节问题。
线性回归算法
线性回归算法主要解决回归问题(废话),但是使用线性回归一定要假装认为数据一定呈线性。其思想简单,实现容易。并且其思路就是大名鼎鼎神经网络的基础。也是很多非线性模型的基础。不像knn,其结果有很好的解释性。
思路
就是从一堆看起来没有联系的样本点中找到一个直线方程,能让数据尽可能拟合这条直线,从而对未知数据进行预测。
简单线性回归
从简单线性回归入手学习线性回归是一个老套路,简单线性回归和真的线性回归其实区别并不大。只不过简单线性回归的特征只有一个,那么就跟x,y坐标一样,可以做二维的显示我们更好的去理解这个思路过程。

如图:我们认为x是数据的一个特征,而y是数据的标签。那么每一个特征对应一个标签,从而构成如图所示的二维坐标图。我们线性回归的目的是在这个坐标中画一条直线,让这些点尽量拟合这条直线。

那么问题来了,什么叫尽量拟合?。出现这样的量词就肯定有个标准吧。
损失函数
那么损失函数这个名词就出来了,损失函数不是线性回归所特有的。很多算法模型中有这种概念。这里简单解释一下就是,我们这条线y=ax+b 对于每一个样本点都会有一个预测值。我们模型希望能让这个预测值和真实的标签值的差距尽可能的小。
又来了!尽可能小是怎么回事,什么叫尽可能小呢?
我们脑袋第一个出来的公式应该是

其中y-hat(就是那个有个帽子的y)是我们的预测值。我们只需要算出这个差值不就完了。但是…这值有正有负不太好判断啊。

加个绝对值不就好了。看起来很有道理。但是紧接着问题就来了,既然要求极值那不是要求导么?(高数告诉我的)。那么这个绝对值的函数不是处处可导的(基本知识)。那么什么样一个函数能保证这个函数的值一直是正数并且处处可导呢?答案就是

加个平方就好了。那么我们的目标变了。我们要让这个 函数尽可能的小。(就是找极值点)

这个就是我们的损失函数。我们要这个值足够小,就要求极值点的时候a,b的值。(注意,这里的x,y 不再是未知数,未知数是a,b .x,y是已知的)。
找极值点
这里找极值点有几种方法,第一种方法就是硬算(高数中怎么算的,我们这里就怎么算)。第二种方法就是梯度下降。先看第一种
最小二乘法
按照高数中学习的,一个函数的极值点的导数为0。那么我们这里姑且认为导数为0的点就是极值点。那么首先看loss函数。

极值点:

就是偏导数等于0的点。
把式子展开

根据求导法则肯定是b好求(因为b前面系数是常数嘛)。
那么

链式求导法则,很容易。

麻烦的是求偏a(后面化简的脑洞真大)

把上面求的b带进去。

其实这里就够了,但是为了方便计算还有在基础上化简的。这个脑洞就比较大。
看看就可以了。这个化简是

根据这个式子来的。

这个东西可以来回变成了几个等式。根据这个等式去化简原式子。

就是上面+上一个东西和减去一个东西。下面+一个东西减去一个东西。这是为了更好的化简。

为什么要这样做呢?其实就是为了更好的做向量化运算(就是不想代码中一堆for,能用矩阵的运算方法解决的就用矩阵的运算方法解决)。
看代码:
import numpy as np
import matplotlib.pyplot as plt
# 造了一批数字
x=np.array([1,2,3,4,5.0])
y=np.array([1,3,2,3,5.0])
x_mean=np.mean(x)
y_mean=np.mean(y)
# 求a
num=0.0
d=0.0
for x_i ,y_i in zip(x,y):
num += (x_i - x_mean) * (y_i - y_mean)
d += (x_i - x_mean) **2
a=num/d
#向量化 a = (x - x_mean).dot(y - y_mean) / (x - x_mean).dot(x - x_mean)
#求b
b=y_mean-a*x_mean效果是

就直观来看拟合的还算不错。
梯度下降
梯度下降是一个非常经典的算法,这个在之前的博客中也说到过,就简单线性规划来看,如果损失函数是一个凸函数。那么 我们每一次都可以让函数往极值点滚动。其实就是一个找碗底的过程。
想要搞定找碗底的问题,先看看一维凸函数是怎么回事。
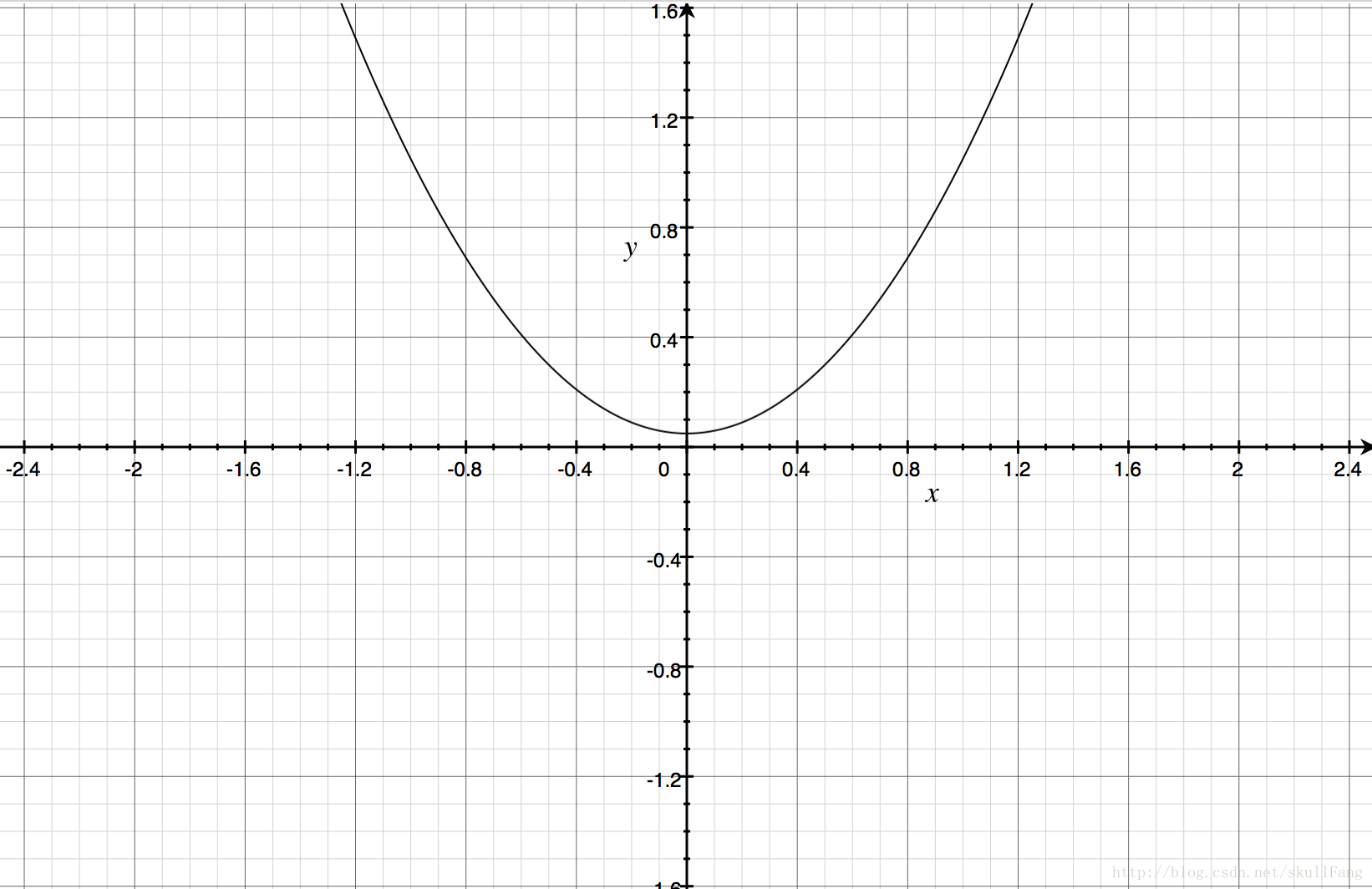
由图像可以看出,凸吧!!!(凸个鬼,不应该是凹的么)。whatever。只是看这个图像的角度不一样吧。
怎么求极值呢?
这个简单,就是求导取导数等于0的点咯。。(说好不用这种方法)
那么我们的方法:
1、随便取一个点。
2、比较一下左右两边。
3、往小的那个方向滚动。
这个方法叫“挪动比较法”(自己编得名字)。
这个方法看似很靠谱,其实不靠谱。如果维度很高的话,每个维度需要比较两次(不同的方向),这对计算机来说计算量也有点大。
所以就造出来一个公式。
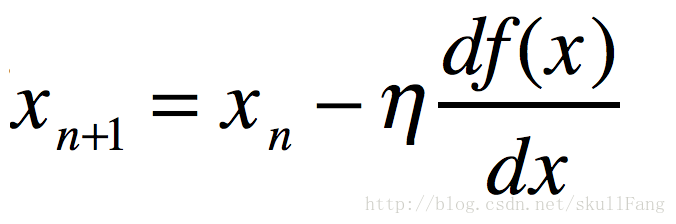
也就是说x的挪动方向直接跟自己的导数有关系。观察那个一元凸函数,我们稍微琢磨一下就可以知道。如果在x轴的正半轴上,那么导数肯定是是一个正书,我们减去这个正数。那么下一个x应该在往左边挪动。同样的如果在x轴的负半轴上,根据这个公式会往右边挪。慢慢挪就到了极值点了。神奇吧。这个的n是学习率(这个参数是手动调的)。就是每次挪动的步伐有多大。
看梯度下降可视化 的简单代码
import numpy as np
import matplotlib.pyplot as plt
plot_x=np.linspace(-1,6,141)
plt.plot(plot_x,plot_y)
plt.show()
def dJ(theta):
"""
求导数
"""
return 2*(theta-2.5)def J(theta):
"""
损失函数
"""
return (theta-2.5) ** 2 -1theta =0.0
epsilon=1e-8
eta=0.1
while True:
gradient = dJ(theta) #求出倒数
last_theta = theta
theta = theta- eta * gradient
if(abs(J(theta)-J(last_theta))<epsilon):
break
print(theta)
print(J(theta))结果是
2.499891109642585
-0.99999998814289我们肉眼看一下大概就是我们的极值点。我们可视化一下。
theta =6.0
theta_history=[theta]
while True:
gradient = dJ(theta) #求出倒数
last_theta = theta
theta = theta- eta * gradient
theta_history.append(theta)
if(abs(J(theta)-J(last_theta))<epsilon): #防止死循环
break
plt.plot(plot_x,J(plot_x))
plt.plot(np.array(theta_history),J(np.array(theta_history)),color='r',marker='*')
plt.show()
因为梯度下降的方法有通用性,怎么去使用涉及到多元线性回归的知识。等在后续多元线性回归的文章中说。

















 1818
1818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









