







案例介绍
通过Kettle工具抽取HTML网页的数据,并保存至数据库extract中的数据表html中。
案例实现
1.打开Kettle工具,创建转换
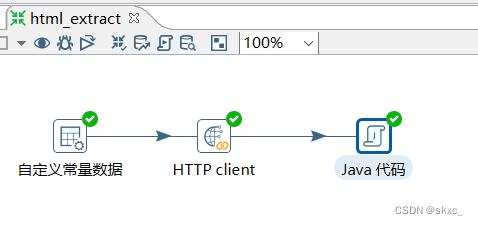
通过使用Kettle工具,创建一个转换转换html_extract,并添加“自定义常量数据”输入控件、“HTTP client”查询控件和“Java代码”脚本控件,,具体如图所示。
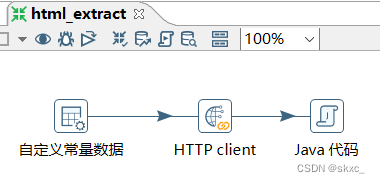
2.配置自定义常量数据控件
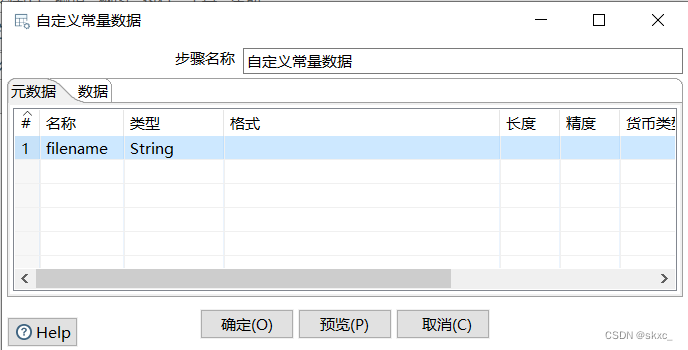
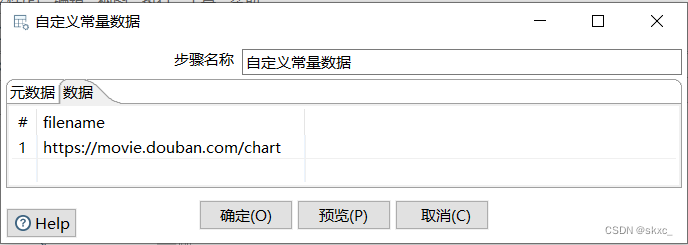
双击“自定义常量数据”控件,进入“自定义常量数据”界面。单击“元数据”选项卡,定义一个字段常量filename并指定数据类型String;单击“数据”选项卡,添加html形式数据所在的URL,即https://movie.douban.com/chart。
3.配置HTTP client控件
双击“HTTP client”控件,进入“HTTP web service”界面。
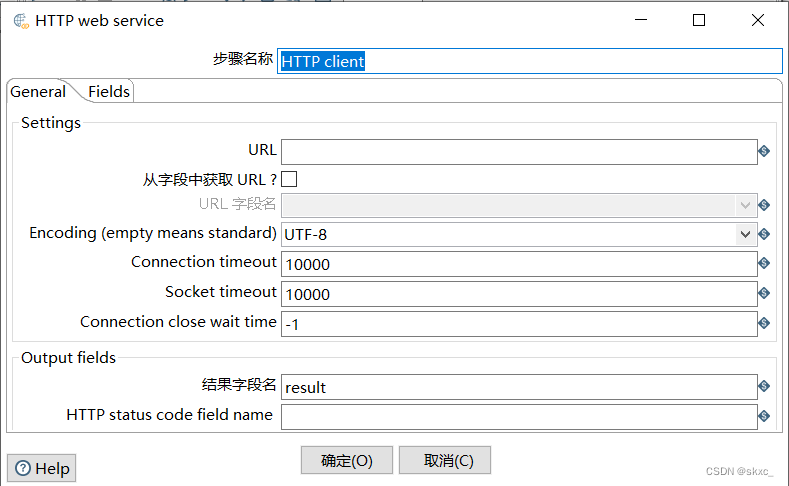
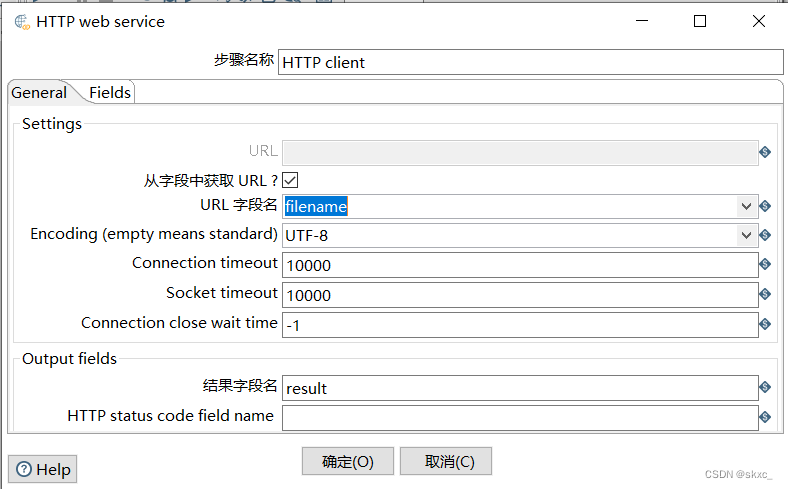
勾选图4-40的“从字段中获取URL?”的复选框;在“URL字段名”处的下拉框中选择URL字段名,即filename;在“结果字段名”处指定结果字段名称,这里选择默认的结果字段result。“HTTP client”控件配置的效果如图所示。
4.配置Java代码控件
双击“Java”控件,进入“Java代码”界面。
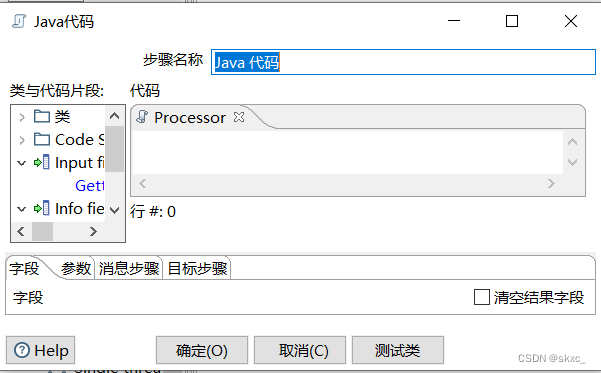
双击“Code Snippits”→ “Common use”→ “Main”,添加Java脚本代码的主方法,即程序入口。
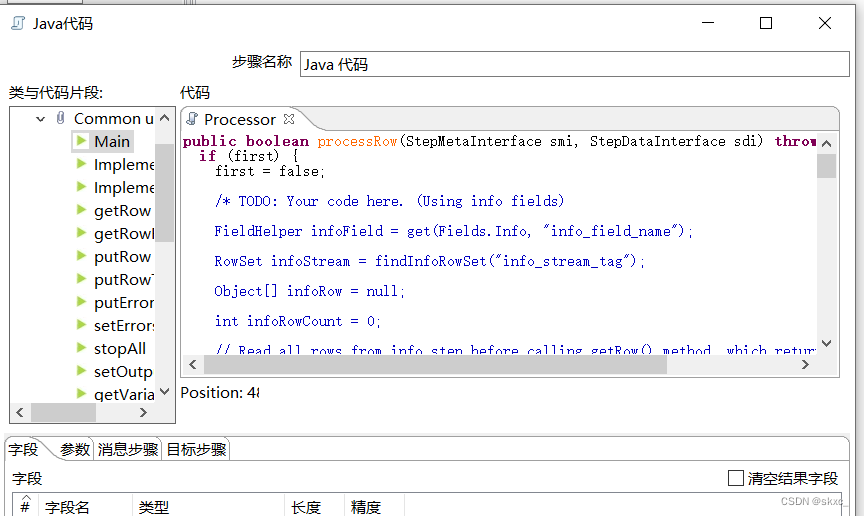
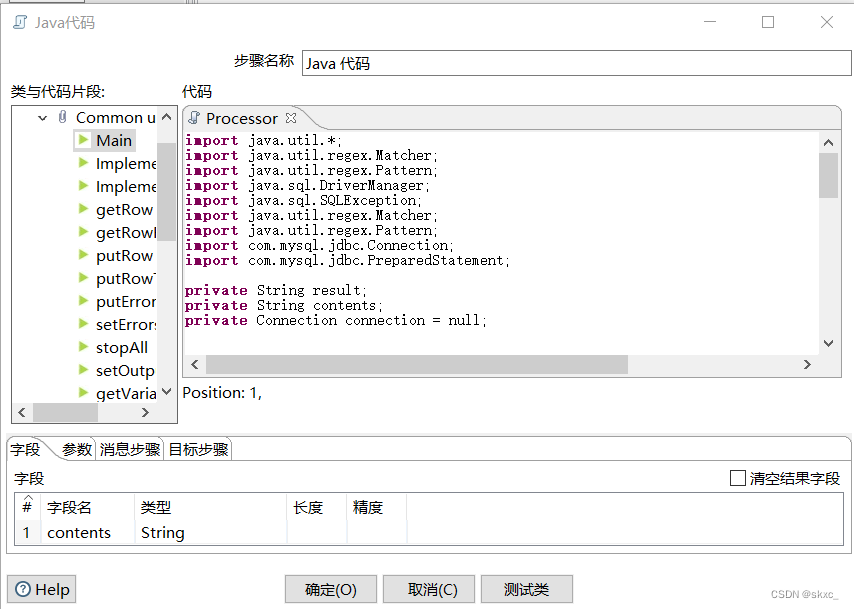
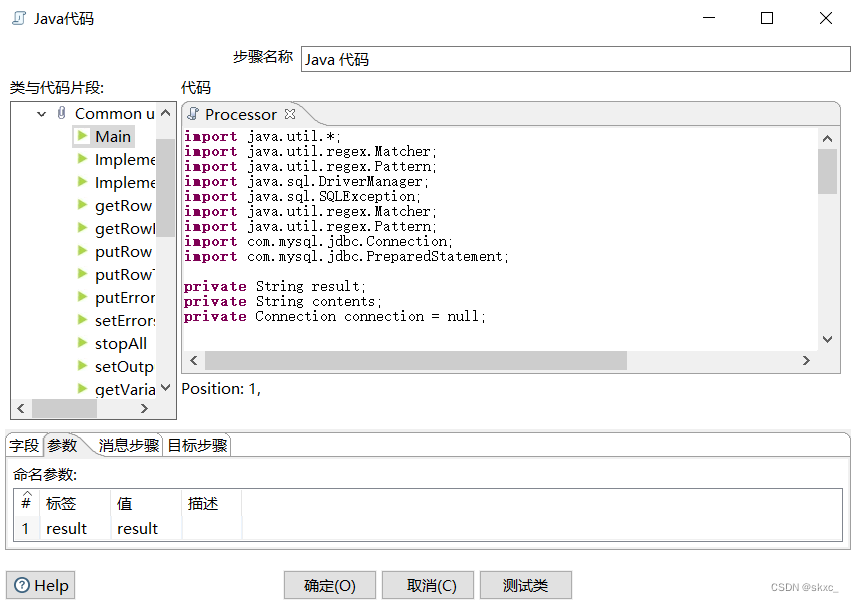
在“Java代码”控件中的代码框编写抽取HTML网页数据的Java脚本代码。单击“Java代码”控件中的“字段”选项卡,用于添加新生成的字段;单击“参数”选项卡,用于传入参数。“字段”选项卡界面和“参数”选项卡界面具体如图所示。
5.运行转换html_extract
单击转换工作区顶部的![]() 按钮,运行创建的html_extract转换。
按钮,运行创建的html_extract转换。
6.查看html数据表中的数据
通过SQLyog工具,查看数据表html是否已成功插入66行数据。















 3646
3646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









