







目录
一、前言
Python是一种高级编程语言,已经成为数据科学和数据分析领域中的首选语言之一。它有许多数据分析库和工具,可以轻松地进行数据处理、分析和可视化。
关于Python的基础介绍:http://t.csdnimg.cn/PMI3X
二、数据分析介绍

以下是Python数据分析的几个关键点:
1.数据清洗和预处理
在数据分析中,数据清洗和预处理是非常重要的步骤。这包括删除或填充缺失数据、去除重复项、处理异常值和标准化数据等。Python中的Pandas和NumPy是两个常用的库,可以帮助你轻松地进行这些操作。
以下是一个简单的Python代码示例,用于数据清理和预处理:
import pandas as pd import numpy as np # 读取数据文件 data = pd.read_csv('data.csv') # 删除重复行 data.drop_duplicates(inplace=True) # 删除空值行 data.dropna(inplace=True) # 将日期列转换为datetime类型 data['date'] = pd.to_datetime(data['date']) # 将字符串列转换为数值类型 data['price'] = pd.to_numeric(data['price']) # 填充缺失值 data.fillna(0, inplace=True) # 重置索引 data.reset_index(drop=True, inplace=True) # 缩放数据 from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() data[['price', 'volume']] = scaler.fit_transform(data[['price', 'volume']]) # 去除异常值 data = data[(data['price'] > 0) & (data['price'] < 50)] # 增加新特征 data['price_change'] = data['price'].diff() # 保存数据文件 data.to_csv('cleaned_data.csv', index=False)在这个例子中,我们使用pandas和numpy库来读取、处理和清理数据。我们使用了pandas的drop_duplicates()和dropna()方法来删除重复行和空值行。我们还使用了pandas的to_datetime()和to_numeric()方法来转换日期和字符串列为datetime和数值类型。我们使用了fillna()方法来填充缺失值,并使用reset_index()方法来重置索引。我们还使用了sklearn库中的MinMaxScaler()类来缩放数据。我们使用了Python的布尔值运算符来去除价格异常值,并使用了pandas的diff()方法来计算价格变化。最后,我们使用to_csv()方法将清理后的数据保存到文件中。
2.数据分析和可视化
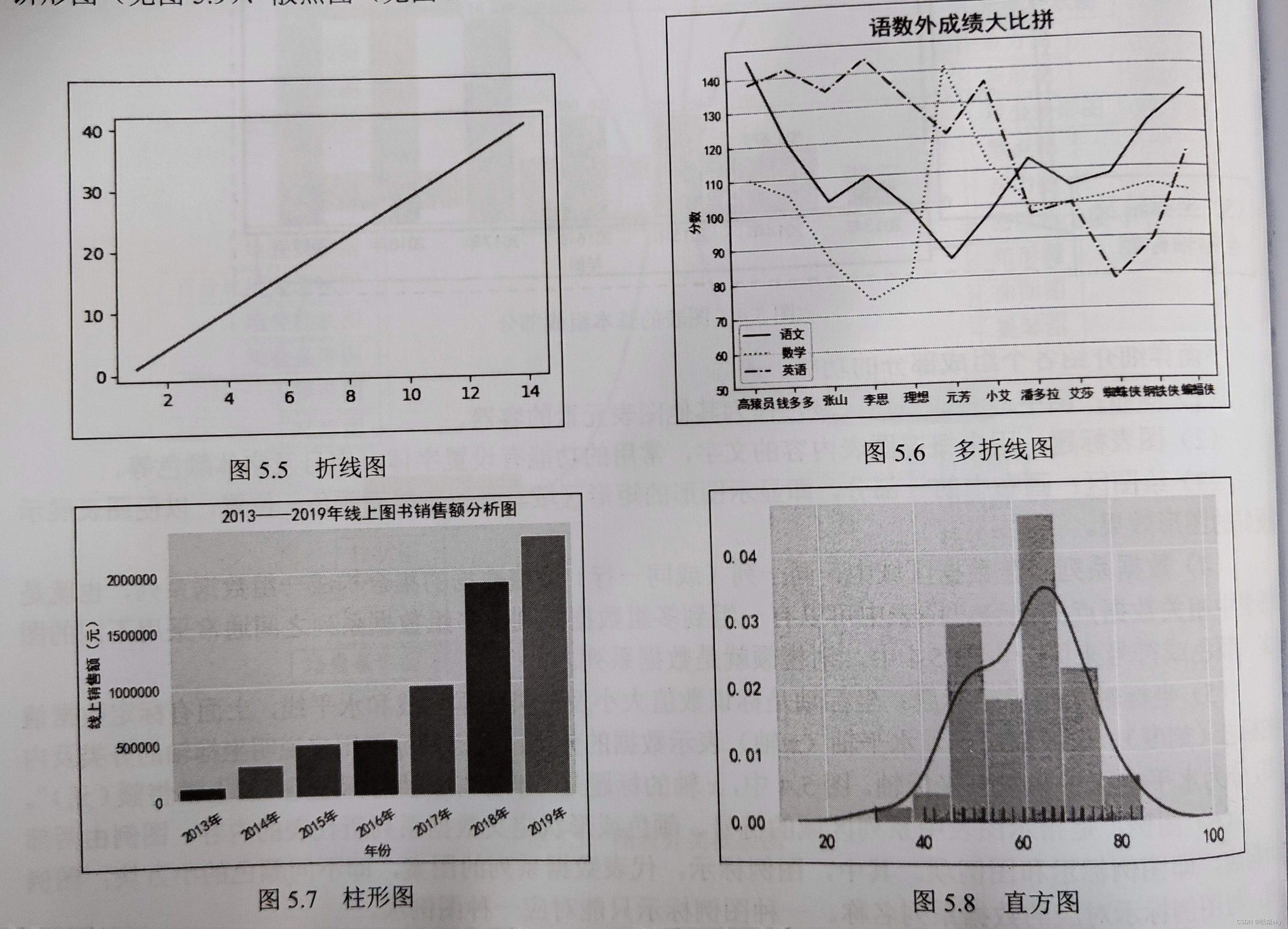
一旦您清洗和预处理数据,就可以开始对其进行分析和可视化。Python中的Matplotlib和Seaborn库是常用的数据可视化工具,可以帮助我们创建各种图表,如折线图、散点图、直方图等。
以下是一个简单的数据分析和可视化示例,以分析一家餐厅的营业额和利润。
首先,收集餐厅的销售数据,包括每天的总销售额和成本。
日期 总销售额 成本 1月1日 1000元 500元 1月2日 1200元 600元 1月3日 900元 450元 1月4日 1500元 750元 1月5日 800元 400元 1月6日 1300元 650元 1月7日 1100元 550元 根据这些数据,计算每天的净收入:
日期 净收入 1月1日 500元 1月2日 600元 1月3日 450元 1月4日 750元 1月5日 400元 1月6日 650元 1月7日 550元 接下来,我们可以使用Python的matplotlib库创建一个简单的折线图,展示餐厅每天的净收入。
import matplotlib.pyplot as plt # 出现中文显示问题时,可添加下面两行代码 from pylab import mpl mpl.rcParams['font.sans-serif'] = ['SimHei'] mpl.rcParams['axes.unicode_minus'] = False # 数据 dates = ['1月1日', '1月2日', '1月3日', '1月4日', '1月5日', '1月6日', '1月7日'] net_incomes = [500, 600, 450, 750, 400, 650, 550] # 创建折线图 plt.plot(dates, net_incomes) # 添加标题和标签 plt.title('餐厅每天的净收入') plt.xlabel('日期') plt.ylabel('净收入(元)') # 显示图形 plt.show()以上代码将绘制一个折线图,显示餐厅每天的净收入。
接下来,我们可以计算餐厅的总营业额和总利润,并使用一个简单的数据表格来展示它们。
总营业额:6500元
总利润:3350元
最后,我们可以使用一个简单的饼图来展示餐厅总利润的构成部分。
# 数据 profits = [0.5, 0.2, 0.1, 0.2] labels = ['员工工资', '房租', '材料成本', '其他成本'] # 创建饼图 plt.pie(profits, labels=labels) # 添加标题 plt.title('餐厅总利润的构成部分') # 显示图形 plt.show()
以上代码将绘制一个饼图,展示餐厅总利润的构成部分。
3.机器学习
机器学习是数据分析中的一个重要领域,Python中有许多流行的机器学习库,如Scikit-learn、TensorFlow和PyTorch。这些库可以帮助我们构建各种机器学习模型和算法,如回归、决策树、神经网络等。
以下是一个简单的机器学习代码示例,用于预测一个人是否喜欢冰淇淋:
import pandas as pd from sklearn.model_selection import train_test_split from sklearn.tree import DecisionTreeClassifier # 读取数据 data = pd.read_csv('icecream.csv') # 分离特征和标签 X = data.drop('likes_icecream', axis=1) y = data['likes_icecream'] # 将数据分为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 训练决策树模型 model = DecisionTreeClassifier() model.fit(X_train, y_train) # 测试模型 score = model.score(X_test, y_test) print("模型准确率:", score) # 预测新数据 new_data = pd.DataFrame({'age': [25], 'gender': ['male'], 'income': [50000]}) prediction = model.predict(new_data) print("预测结果:", prediction)
在这个例子中,我们使用了一个决策树分类器来预测一个人是否喜欢冰淇淋。我们首先读取数据,并将其拆分为特征和标签。然后,我们将数据分为训练集和测试集,并使用训练集来训练决策树模型。最后,我们使用测试集来测试模型的准确性,并使用模型来预测新的数据。
4.大数据处理
Python中的Dask和PySpark是常用的大数据处理工具。它们可以帮助我们有效地处理大规模数据集,从而加快我们的数据分析工作流程。
Python用于大数据处理的一些常用工具和技术:
-
NumPy:NumPy是Python中的一个重要的包,为科学数据分析提供了一个强大的环境,它支持大量的数值操作和矩阵计算。
-
Pandas:Pandas是Python中的另一个流行的数据处理模块,它提供了一个高效的数据结构,如DataFrame和Series,以及用于数据探索,清理,转换和分析的数据操作函数。
-
SciPy:SciPy是一个广泛使用的科学计算库,用于处理大量数据,包括统计分析,优化,插值,信号处理和图像处理等。
-
Matplotlib:Matplotlib是一个Python用于可视化的强大工具,能够绘制2D和3D图形,如散点图,直方图和等高线图等。
-
Spark:Spark是一个分布式计算框架,可以处理大规模数据,支持Python API,并支持实时和批处理的大规模数据操作。
-
Dask:Dask是一个灵活和可扩展的分布式计算库,可以处理Python中大规模的数据集。
以下是一个简单示例,演示如何使用Python处理大数据集:
import pandas as pd import numpy as np # 读取大型csv文件 data = pd.read_csv("large_dataset.csv") # 查看数据集的前5行 print(data.head()) # 查看数据集的大小 print(data.shape) # 查看数据的描述性统计信息 print(data.describe()) # 选择特定列进行数据分析 subset = data[["column1", "column2", "column3"]] # 通过添加限制条件来过滤数据 subset_filtered = subset[(subset["column1"] > 0) & (subset["column2"] < 100)] # 对过滤后的数据进行分组和聚合操作 grouped_data = subset_filtered.groupby("column3").agg({"column1": np.sum, "column2": np.mean}) # 查看聚合结果 print(grouped_data) # 将处理结果保存到新的csv文件中 grouped_data.to_csv("output.csv", index=False)
三、数据分析绘图库
Python数据分析绘图包括常用的Matplotlib、Seaborn、Plotly、Bokeh和ggplot等,以下是每个包的简介及示例:
1.Matplotlib
是Python数据可视化的基础库,可以用于绘制多种类型的图表,包括线图、散点图、柱状图等。示例代码如下:
import matplotlib.pyplot as plt
import numpy as np
# 创建数据
x = np.arange(4)
y1 = [10, 15, 20, 25]
y2 = [5, 10, 15, 20]
y3 = [12, 18, 24, 30]
y4 = [8, 12, 16, 20]
# 绘制柱形图
plt.bar(x, y1, width=0.2, color='r', label='Series 1')
plt.bar(x+0.2, y2, width=0.2, color='g', label='Series 2')
plt.bar(x+0.4, y3, width=0.2, color='b', label='Series 3')
plt.bar(x+0.6, y4, width=0.2, color='y', label='Series 4')
# 添加标签和标题
plt.xlabel('X Label')
plt.ylabel('Y Label')
plt.title('Four Rows Bar Chart')
# 添加图例
plt.legend()
# 显示图形
plt.show()
2.Seaborn(需要先安装seaborn)
是一个基于Matplotlib的高级数据可视化库,可以用于绘制各种类型的统计图表,包括热力图、分布图、条形图等。示例代码如下:
import seaborn as sns
import pandas as pd
# 导入数据
tips = pd.read_csv('tips.csv')
# 绘制柱状图
sns.barplot(x='day', y='total_bill', data=tips)
# 添加标题和标签
plt.title('Total Bill by Day')
plt.xlabel('Day of the Week')
plt.ylabel('Total Bill')
# 显示图形
plt.show()
3.Plotly

是一个交互式可视化库,可以用于绘制各种类型的图表,包括折线图、散点图、柱状图等。示例代码如下:
import plotly.graph_objs as go
import numpy as np
# 生成数据
x = np.linspace(0, 10, 100)
y = np.sin(x)
# 绘制折线图
trace = go.Scatter(x=x, y=y)
# 添加标题和标签
layout = go.Layout(title='Sine Wave', xaxis=dict(title='X-axis'), yaxis=dict(title='Y-axis'))
# 绘制图形
fig = go.Figure(data=[trace], layout=layout)
fig.show()
4.Bokeh

也是一个交互式可视化库,可以用于绘制各种类型的图表,包括散点图、柱状图等。示例代码如下:
from bokeh.plotting import figure, show
from bokeh.io import output_notebook
import numpy as np
# 生成数据
x = np.linspace(0, 10, 100)
y = np.sin(x)
# 绘制散点图
p = figure(title='Sine Wave', x_axis_label='X-axis', y_axis_label='Y-axis')
p.scatter(x, y)
# 显示图形
output_notebook()
show(p)
5.ggplot

是一个基于R语言ggplot2的可视化库,可以用于绘制各种类型的统计图表。示例代码如下:
from ggplot import diamonds, aes
import pandas as pd
# 导入数据
df = diamonds.head(100)
# 绘制散点图
ggplot(df, aes(x='carat', y='price', color='cut')) + geom_point()
# 添加标题和标签
ggtitle('Diamonds by Carat and Price') + xlab('Carat') + ylab('Price')
以上是Python数据分析绘图包的简介和示例,可以根据自身需求选择适合的库进行数据可视化。
在数据分析中,收集、整理、清洗、分析和可视化是不可或缺的步骤。通过数据分析,我们可以更好地理解和发现问题,并采取相应的措施来解决这些问题。在现代社会中,数据分析已经成为各个领域的核心工具之一,对于企业、政府、学术研究等方面都有很大的价值。希望本文的内容可以为您提供一些有用的参考。















 9458
9458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









