







一、引言
在数据分析和机器学习的领域中,聚类分析是一种重要的无监督学习方法。聚类算法的目标是将相似的数据点划分为同一类别,而不同类别之间的数据点则尽可能不同。K均值(K-means)算法作为聚类分析中的一种基础且广泛使用的技术,具有简单、高效的特点。本文将详细介绍K均值算法的原理、步骤以及在实际应用中的使用方法。
依据算法原理,聚类算法可以分为基于划分的聚类算法(比如 K-means)、基于密度的聚类算法(比如DBSCAN)、基于层次的聚类算法(比如HC)和基于模型的聚类算法(比如HMM)HMM隐马尔可夫模型的例子、原理、计算和应用 - 知乎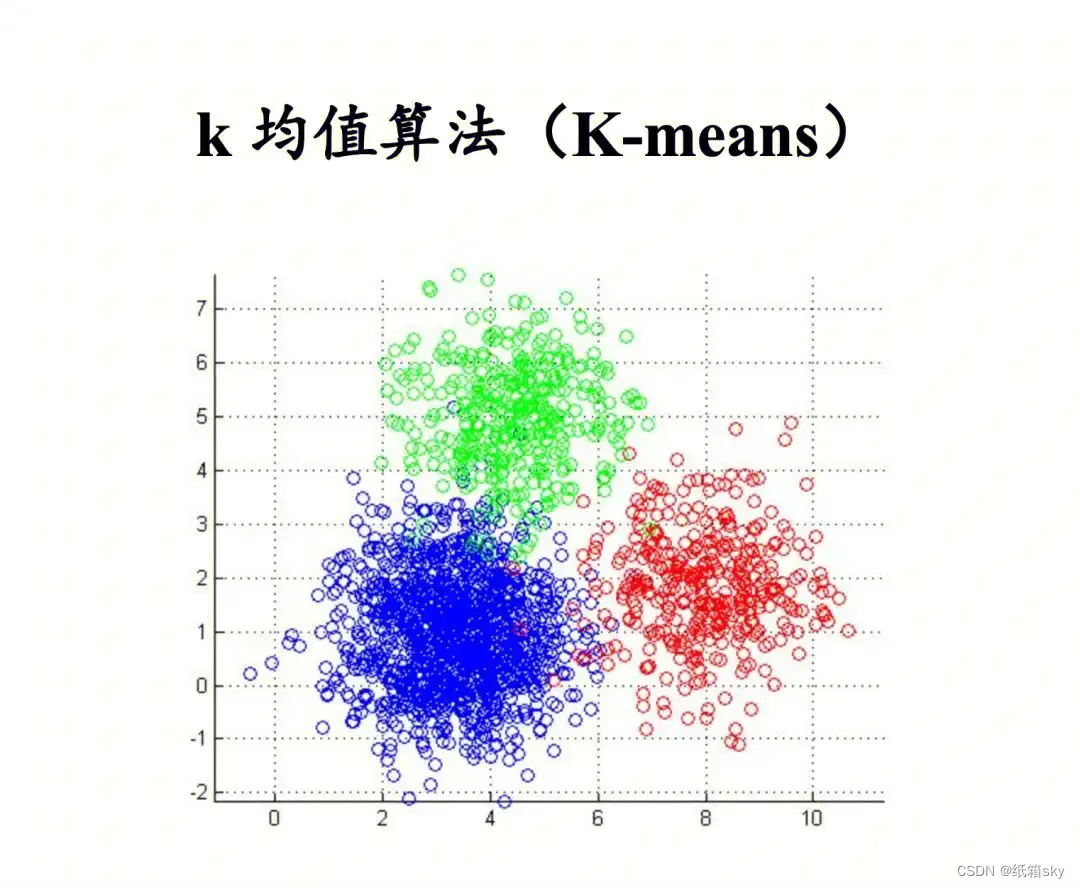
k均值算法是一种常用的聚类方法,它将数据集分成k个不重叠的簇,每个簇的中心点即为该簇中所有数据点的平均值。k均值算法的步骤如下:
-
随机选择k个样本点作为初始的聚类中心。
-
将数据集中的每个样本点分配到距离最近的聚类中心。
-
根据分配结果,重新计算每个簇的中心点。
-
重复步骤2和步骤3,直到簇的中心点不再发生变化或者达到设定的迭代次数。
-
返回聚类结果。

在k均值算法中,需要事先确定簇的数量k,这可以通过试验和经验来确定。一般来说,可以通过绘制不同k值对应的聚类误差(样本点到中心点的距离之和)图来选择合适的k值。
二、K均值算法原理
K均值算法是一种迭代求解的聚类分析算法,其目标是将数据划分为K个簇,并使得每个簇内的数据点尽可能接近簇的质心(即簇内所有数据点的均值)。
算法的步骤如下:
- 初始化:从数据集中随机选择K个数据点作为初始的簇质心。
- 分配:对于数据集中的每个数据点,计算其与K个簇质心的距离,并将其分配给距离最近的簇。
- 更新:对于每个簇,计算其内部所有数据点的均值,并将该均值作为新的簇质心。
- 迭代:重复步骤2和步骤3,直到簇质心的位置不再发生显著变化(即算法收敛)或达到预设的迭代次数。
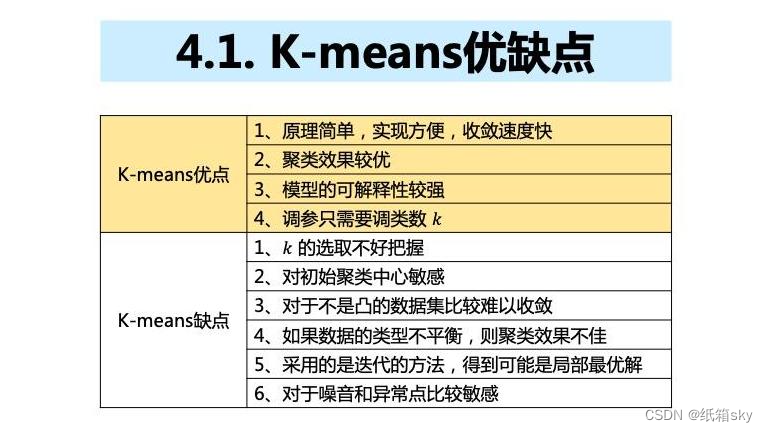
三、K均值算法的优点与缺点
优点:
- 原理简单,易于理解和实现。
- 算法复杂度低,计算效率高。
- 对大规模数据集具有较好的适用性。
缺点:
- 需要预先设定簇的数量K,这在实际应用中可能是一个挑战。
- 对初始质心的选择敏感,不同的初始质心可能导致不同的聚类结果。
- 对噪声和异常值较为敏感,可能导致聚类结果不准确。
四、K均值算法的应用
K-means的Python实现
# -*- coding:utf-8 -*- import numpy as np from matplotlib import pyplot class K_Means(object): # k是分组数;tolerance‘中心点误差’;max_iter是迭代次数 def __init__(self, k=2, tolerance=0.0001, max_iter=300): self.k_ = k self.tolerance_ = tolerance self.max_iter_ = max_iter def fit(self, data): self.centers_ = {} for i in range(self.k_): self.centers_[i] = data[i] for i in range(self.max_iter_): self.clf_ = {} for i in range(self.k_): self.clf_[i] = [] # print("质点:",self.centers_) for feature in data: # distances = [np.linalg.norm(feature-self.centers[center]) for center in self.centers] distances = [] for center in self.centers_: # 欧拉距离 # np.sqrt(np.sum((features-self.centers_[center])**2)) distances.append(np.linalg.norm(feature - self.centers_[center])) classification = distances.index(min(distances)) self.clf_[classification].append(feature) # print("分组情况:",self.clf_) prev_centers = dict(self.centers_) for c in self.clf_: self.centers_[c] = np.average(self.clf_[c], axis=0) # '中心点'是否在误差范围 optimized = True for center in self.centers_: org_centers = prev_centers[center] cur_centers = self.centers_[center] if np.sum((cur_centers - org_centers) / org_centers * 100.0) > self.tolerance_: optimized = False if optimized: break def predict(self, p_data): distances = [np.linalg.norm(p_data - self.centers_[center]) for center in self.centers_] index = distances.index(min(distances)) return index if __name__ == '__main__': x = np.array([[1, 2], [1.5, 1.8], [5, 8], [8, 8], [1, 0.6], [9, 11]]) k_means = K_Means(k=2) k_means.fit(x) print(k_means.centers_) for center in k_means.centers_: pyplot.scatter(k_means.centers_[center][0], k_means.centers_[center][1], marker='*', s=150) for cat in k_means.clf_: for point in k_means.clf_[cat]: pyplot.scatter(point[0], point[1], c=('r' if cat == 0 else 'b')) predict = [[2, 1], [6, 9]] for feature in predict: cat = k_means.predict(predict) pyplot.scatter(feature[0], feature[1], c=('r' if cat == 0 else 'b'), marker='x') pyplot.show()
执行结果如下:
{0: array([1.16666667, 1.46666667]), 1: array([7.33333333, 9. ])}
K-means的Sklearn实现
# 把上面数据点分为两组(非监督学习) clf = KMeans(n_clusters=2) clf.fit(x) # 分组 centers = clf.cluster_centers_ # 两组数据点的中心点 labels = clf.labels_ # 每个数据点所属分组 print(centers) print(labels) for i in range(len(labels)): pyplot.scatter(x[i][0], x[i][1], c=('r' if labels[i] == 0 else 'b')) pyplot.scatter(centers[:,0],centers[:,1],marker='*', s=100) # 预测 predict = [[2,1], [6,9]] label = clf.predict(predict) for i in range(len(label)): pyplot.scatter(predict[i][0], predict[i][1], c=('r' if label[i] == 0 else 'b'), marker='x') pyplot.show()
执行结果如下:
[[7.33333333 9. ][1.16666667 1.46666667]]
[1 1 0 0 1 0]
用户聚类分群
数据集:titanic.xls(泰坦尼克号遇难者与幸存者名单)
titanic.xls的数据集获取地址:ML_tutorial/dataset/titanic.xls at master · PinkWink/ML_tutorial · GitHub
# -*- coding:utf-8 -*- import numpy as np from sklearn.cluster import KMeans from sklearn import preprocessing import pandas as pd # 加载数据 df = pd.read_excel('titanic.xls') df.drop(['body', 'name', 'ticket'], 1, inplace=True) df.fillna(0, inplace=True) # 把NaN替换为0 # 把字符串映射为数字,例如{female:1, male:0} df_map = {} cols = df.columns.values for col in cols: if df[col].dtype != np.int64 and df[col].dtype != np.float64: temp = {} x = 0 for ele in set(df[col].values.tolist()): if ele not in temp: temp[ele] = x x += 1 df_map[df[col].name] = temp df[col] = list(map(lambda val: temp[val], df[col])) # 将每一列特征标准化为标准正太分布 x = np.array(df.drop(['survived'], 1).astype(float)) x = preprocessing.scale(x) clf = KMeans(n_clusters=2) clf.fit(x) # 计算分组准确率 y = np.array(df['survived']) correct = 0 for i in range(len(x)): predict_data = np.array(x[i].astype(float)) predict_data = predict_data.reshape(-1, len(predict_data)) predict = clf.predict(predict_data) if predict[0] == y[i]: correct += 1 print(correct * 1.0 / len(x))
运行结果
第一次执行:0.6974789915966386
第二次执行:0.3017570664629488
K均值算法在实际应用中具有广泛的应用场景,包括但不限于:
- 客户细分:根据客户的消费习惯、偏好等信息,利用K均值算法将客户划分为不同的细分市场,以便制定更加精准的营销策略。
- 文本聚类:对于大量的文本数据,可以使用K均值算法进行聚类,以便发现文本之间的主题关联和相似性。
- 图像分割:在图像处理领域,K均值算法可以用于图像分割,将图像划分为不同的区域或对象。
- 社交网络分析:在社交网络数据中,K均值算法可以帮助我们发现具有相似兴趣和行为的用户群体。
参考:K-means聚类算法原理及python实现_python kmeans-CSDN博客
五、结论
k均值算法的优点是简单、易于实现,并且对大规模数据集的处理速度较快,作为一种简单、高效的聚类分析技术,K均值算法在数据分析和机器学习的领域中发挥着重要作用。但是它也有一些缺点,例如对初始聚类中心的选择敏感,容易陷入局部最优解,以及对噪声和异常值比较敏感等。在实际应用中,可以结合其他预处理方法或者改进的算法来提高聚类效果,通过理解和掌握K均值算法的原理、步骤以及优缺点,我们可以更好地将其应用于实际问题中,实现数据的有效聚类和分析。同时,我们也需要认识到K均值算法的一些局限性,并在实际应用中结合其他技术和方法进行改进和优化。
决策树的原理可参考:决策树(ID3、C4.5、CART)的原理、Python实现、Sklearn可视化和应用 - 知乎
逻辑回归的原理可参考:















 892
892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









