







今天开始跟着“丁奇”大佬重新认识MySQL,为了马上开始的秋招可以愉快的和面试官击剑O(∩_∩)O哈哈~
文章引自:
https://time.geekbang.org/column/article/68319
以下是个人的笔记以及总结,首先给一张图解释Mysq的查询语句执行过程:
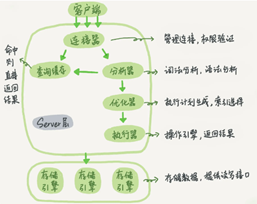
大体来说,MySQL 可以分为 Server 层和存储引擎层(MySQL自带引擎为MyISAM,InnoDB是另一个公司以插件形式引入的)两部分。
按查询操作的顺序分别介绍如下几点:
- 连接器:
1)在完成经典的 TCP 握手后,连接器就要通过账号密码开始认证你的身份;
2)客户端如果太长时间没动静,连接器就会自动将它断开。这个时间是由参数 wait_timeout控制的,默认值是 8 小时;
3)长连接是指连接成功后,如果客户端持续有请求,则一直使用同一个连接。短连接则是指每次执行完很少的几次查询就断开连接,下次查询再重新建立一个(建立连接过程资源开销大,尽量用长连接);
4)长连接时MySQL 占用内存涨得特别快,会导致OOM,解决方法是:执行过一个占用内存的大查询后,断开连接,之后要查询再重连。 - 查询缓存:(一旦表更新,缓存就会被清空)
1)执行过的sql语句结果会被放到缓存中,之后可以从缓存中得到数据,但是缓存查询功能弊大于利;
2)实际中数据表往往更新频繁,所以缓存总是被清空,查询操作命中缓存概率低,那么开启缓存查询功能只会白白消耗系统资源;
3)MySQL8.0之后删除了缓存查询功能。 - 分析器:
1)词法分析:把字符串“T”识别成“表名 T”,把字符串“ID”识别成“列 ID”;(对一条sql语句先在此处分析语句中的表和字段是否存在,不存在就不继续执行后续操作);
2)语法分析:判断sql语句是否符合MySQL规范。 - 优化器:
1)在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联(join)的时候,决定各个表的连接顺序;(加速sql执行速度,提高性能)
如下语句
mysql> select * from t1 join t2 using(ID) where t1.c=10 and t2.d=20;
既可以先从表 t1 里面取出 c=10 的记录的 ID 值,再根据 ID 值关联到表 t2,再判断 t2 里面 d 的值是否等于 20。
也可以先从表 t2 里面取出 d=20 的记录的 ID 值,再根据 ID 值关联到 t1,再判断 t1 里面 c 的值是否等于 10
- 执行器:
1)开始执行的时候,要先判断一下你对这个表 T 有没有执行查询的权限;
2)如果有权限,就打开表继续执行。















 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









