







MySQL索引中包含有三种常见、也比较简单的数据结构,它们分别是哈希表、有序数组和搜索树。
这里补充记录一下自己对Hash的重新认识:
hash是为了将任意长度的一个输入转化成固定长度(比如用一个短的长度为3的hash字符串来表示一个由10000字节的文本,这样只需要比较两个hash字符串就可以判断两份上万字节的文本是否一样了),一般都是用较短的输出去表示较长的输入,是一种压缩算法,也因此HashMap支持快速查找,但增删没有LinkedList快。
以上hash字符串就是hashcode,再对该hashcode进行进一步运算(所有操作都是为了尽可能分散每个key在数组中的分布)就是HashMap里的key值,其对应的value就是这个文本文件。
hash碰撞:本来文本文件有10000个字节,只要有一个字节不一样,就可以判断两份文件不同,但是现在所有文本文件都被压缩成了长度为3的字符串,排列组合一下只有少数key值可用,也就是说不同的文本文件会被映射到一个相同的hash字符串,这就是碰撞了。
hash算法的核心就是尽量减少碰撞,尽量分散放置每一个key。不是按顺序加入数组中是因为可以加快插入元素的速度,不然要在已有的元素中间插入某个元素,需要移动后面所有的元素,而且本身hash得到的key值也是无序的。
回到MySQL的索引机制
- 采用HashMap只支持等值查询,不支持顺序查询(上面解释了每次生成的key值不是依次递增的)。
- 有序数组作为索引,能快速查询且支持范围查询,但是插入元素时可能要移动大量元素位置,很慢(适用于已有数据不会改变的存储)。
- B-树索引:应用的就是M叉树搜索与插入数据的特性。
对回表的重新理解(采用InnoDB的B+树索引)
建立一个主键列为 ID 的表,表中有字段 k,并且在 k 上有索引(非主键索引)
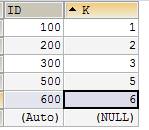
两棵索引树的示例示意图如下

其中主键索引中节点上存储的是R,也就是每一行的数据,非主键索引中节点上存储的是主键ID的值,所以如果你通过主键索引查询的话,可以直接得到整行数据R,而如果通过非主键索引只能得到主键的某个ID,比如是ID=300,然后再到主键索引树中根据主键值找到行记录R(回表)。
大多数情况下用自增主键更好,只需要在B+树最后一个节点后面加入一个节点就行,随机索引的话会在B+树中间某个节点插入新节点,为了保持树的性质要进行节点调整(索引本身是以文件形式存储在磁盘中的,文件中间数据发生变动其内存地址也要变,就会造成分页和合页的情况)
少数情况下可以使用非自增索引,比如一张表只记录了身份证号和姓名,那么可以直接用身份证号作为唯一索引,只有两个字段可以不用回表操作。
再来理解一下MySQL查询数据的真实过程
执行sql:select * from T where k between 3 and 5,需要查几次表?
本来认为三次,首先第一次根据索引k查到ID=300以及ID=500两个ID值,然后根据主键索引查两次表分别查找ID=300和ID=500的数据行。真实情况不然,如下所示:
- 在 k 索引树上找到 k=3 的记录,取得 ID = 300;
- 再到 ID 索引树查到 ID=300 对应的 R3;
- 在 k 索引树取下一个值 k=5,取得 ID=500;
- 再回到 ID 索引树查到 ID=500 对应的 R4;
- 在 k 索引树取下一个值 k=6,不满足条件,循环结束。
也就是说非主键查询的时候只能在两张表之间反复横跳(回表),不能一次性在非主键索引上查到所有主键值,再到主键索引树上找到所有数据行。
索引下推:
MySQL5.6开始已经改善了—引入索引下推机制,如果查询条件where语句中的字段上建立了索引,那么不需要反复在两张表之间跳跃比较是否数据行满足两个或者多个查询条件,对于一个查询条件得到所有数据,MySQL会直接筛选出同时符合其余有索引的筛选条件的数据行,再去主键索引树中获取整行数据,减少回表次数,但是where语句中没有建立索引的字段仍然要去主键索引树中做回表,执行如下sql
select * from tuser where name like '张%' and age=10 and ismale=1;
简单用图片形象化一下:第一张图只有name有索引,回表操作明显多于第二张图,因为第二张图name和age上都有索引,所以第一次查询直接查出所有符合name和age要求的主键值。


联合索引
就是在多个字段上建立索引,并且按照一定的顺序排列(a1,a2,a3,a4),排在最左边的索引优先使用(最左前缀原理)。但是在一条sql语句中不一定都会使用到以上索引,必须满足从左到右的顺序,比如
select * from T where a1 = 1 and a2 = 2 and a4 = 4;
这里只会使用a1和a2两个索引,因为按照顺序a2后只能使用a3。
select * from T where a2 = 2;
这句中不会使用任何索引,因为最左边的索引是a1。如果单独查询a2的情况很多,就要建立两个索引(a1,a2,a3,a4)以及(a2)。
参考文章:
https://time.geekbang.org/column/article/69636















 3506
3506











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









