







 本文详细介绍了MySQL中JOIN操作的执行流程,重点讲解了BlockNested-LoopJoin(BNL)算法的工作原理,以及在被驱动表无法使用索引时如何通过创建临时表优化查询。同时,解释了小表的概念,并阐述了MySQL如何选择驱动表以减少扫描行数。此外,文章还探讨了MySQL的MRR(Multi-Range Read)算法如何应用于JOIN优化,以提高查询效率。
本文详细介绍了MySQL中JOIN操作的执行流程,重点讲解了BlockNested-LoopJoin(BNL)算法的工作原理,以及在被驱动表无法使用索引时如何通过创建临时表优化查询。同时,解释了小表的概念,并阐述了MySQL如何选择驱动表以减少扫描行数。此外,文章还探讨了MySQL的MRR(Multi-Range Read)算法如何应用于JOIN优化,以提高查询效率。
先放上三点结论:
- 如果可以使用被驱动表的索引,就使用join(MySQL当前不支持hash索引);
- 如果被驱动表的索引无法使用,MySQL就只能使用Block Nested-Loop Join算法,就不建议使用join(如果一定要使用join的话可以建立一个临时表复制原本的被驱动表,然后在临时表上建立该字段的索引,也就是BLA算法);
- 使用join时,用小表作为驱动表(MySQL优化器会自动选择驱动表与被驱动表),因为被驱动表可以走索引,这样可以少扫描几行数据。
接下来介绍以下概念:
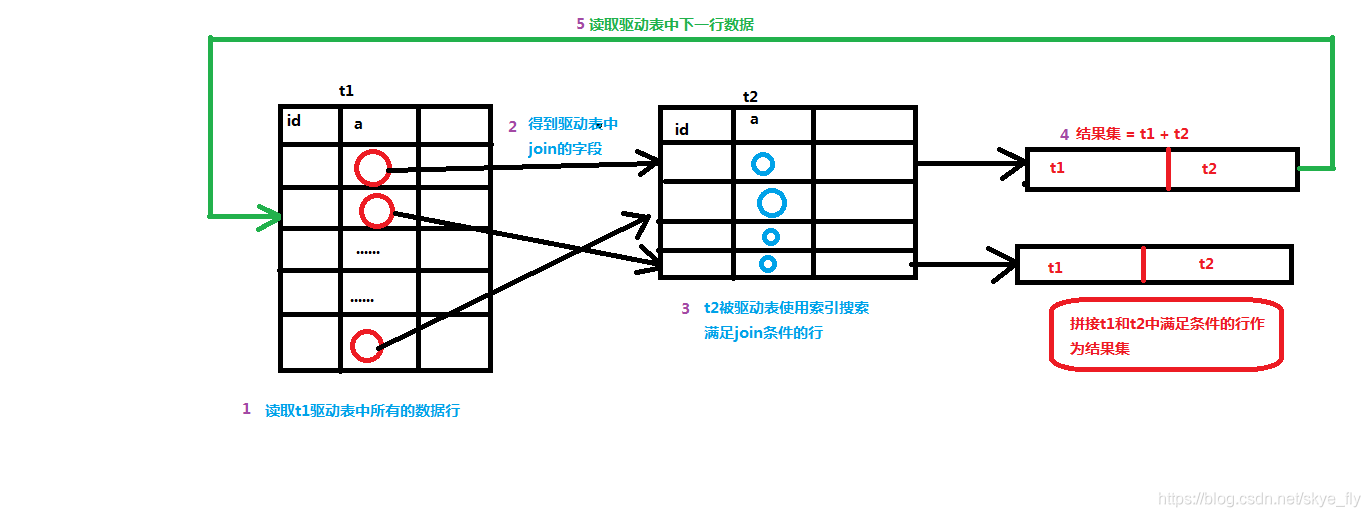
1. 两张表的join过程
考虑以下sql语句:
select * from t1 straight_join t2 on (t1.a=t2.a); // 此处t1是驱动表,t2是被驱动表
其执行流程如下:
首先按行取出驱动表的每一行数据,读取join字段a -----根据被驱动表t2上的索引找到满足join条件的数据行 ----- 将t1与t2中满足join条件的数据行拼接在一起作为结果集中的一行数据 ----- 接着读取驱动表中的下一行数据进行判断(不能一次性读取驱动表中的每一行数据),可以结合下图。
2. 什么是Block Nested-Loop Join算法:
当被驱动表不能使用索引时,将驱动表放入内存中(内存中读数据不需要扫描行,加快了速度,如果内存放不下,就将驱动表拆分后在放入内存中),然后依次按行读取被驱动表中的每一行数据再扫描内存中驱动表的每一行进行join条件比较。由于两张表都没有索引,所以扫描的行数以及比较次数会很大,此时不建议使用join。(可以使用explain来查看MySQL有没有使用Block Nested-Loop Join算法)
3. 什么是小表:
就是参与join的字段总数更少的那个表。(表的总行数更少,select的字段更少)
MySQL对join语句的优化:
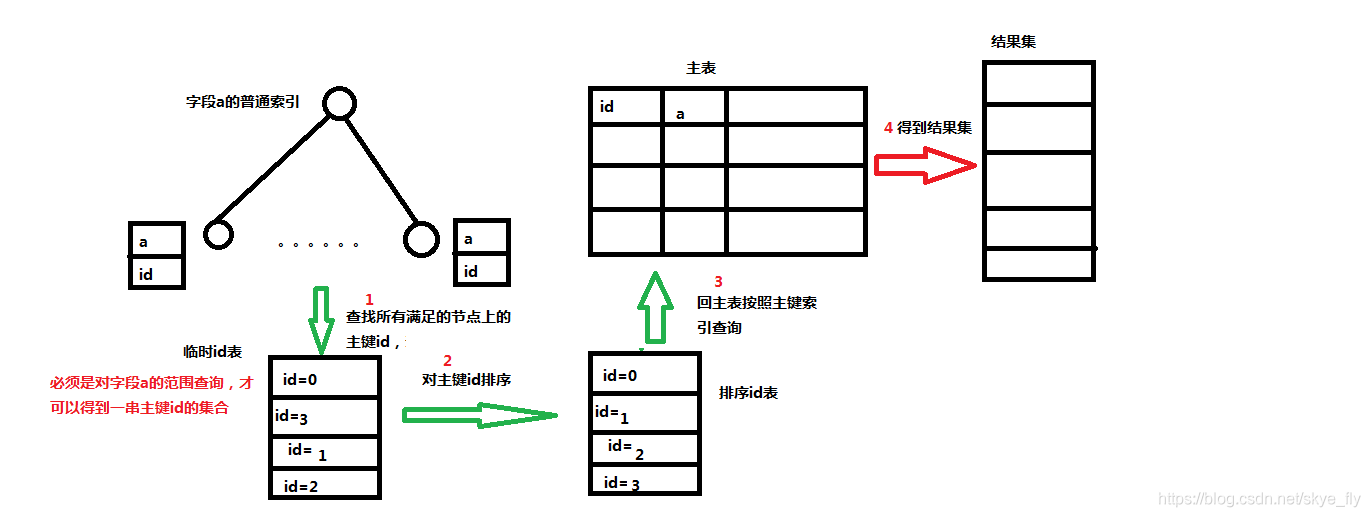
1. 先介绍一下MySQL对普通查询语句的优化(MRR算法)
对于一条查询语句:
select * from t where a>1 and a< 100;
没有优化之前MySQL是先查询索引a,根据索引树找到(1<a<100)中的任意一行数据行的主键id,然后再回表查询主键id对应的数据行的其他字段值,接着再返回查询下一个满足的a字段值(所以每次找到的a是乱序的,对应的id值也是乱序的)。.
MRR优化就是将id乱序回表查询变为顺序回表查询,会在主键索引的基础上进一步提升查询的速度。具体就是查出每一个满足索引a条件的节点上的主键id后,先不进行回表查询主键id对应的数据行,而是查找下一行满足索引a条件的节点的id值(因为a是范围查询,不是等值查询,所以存在满足条件的多个主键id),当查出所有的id值后对所有id值进行升序排序,最后拿着排完序的id列表根据主键索引依次回表查询所有要select的字段值。
.
注:MRR前提是对索引字段进行范围查询
2. 利用MRR算法对join语句进行优化
因为join语句是从t1表中得到一个字段值就去走t2表的索引(t2表中就只有一个主键id,所以不能使用MRR优化),那么为了t2表中可以有多个id值,所以我们先把t1表中查到的字段存到一块临时的内存中,之后再一次性的到t2表中进行匹配,那么就可以得到多个id字段,再使用MRR进行优化。
参考文章:
https://time.geekbang.org/column/article/80147

















 1269
1269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









