






作者:好名字学长
转载地址:https://bbs.huaweicloud.com/forum/thread-163799-1-1.html

经过长达一个月的复现,终于成功利用MindSpore复现了SwinTransformer在imagenet上的分类精度,中间踩过很多的坑,这个帖子就作为复现SwinTransformer的记录贴,希望能对大家复现2021年这种充满训练Trick的论文有所帮助。
复现着复现着突然Swin就拿了最佳论文了,当时感觉也非常有意思,突然就在复现ICCV2021的最佳论文了,模型的效果的确很炸裂。
博客所有的相关代码已经上传到我的码云
修改完成后代码将会合入MindSpore的model的models主仓,有需要的同学可以自取。
数据篇——数据增强
由于SwinTransformer源码是基于PyTorch和timm完成的,其中的AutoAugment虽然是基本基于PIL库实现的,但是由于MindSpore本身图像库接口和timm和PyTorch存在一定的区别,非常不易自己实现。
因此笔者选择将timm的相关数据增强代码复制到MindSpore中并且基于numpy对其中PyTorch的一部分完整修改,同时也可以认为相当于是MindSpore的dataset扩充了一个可以即插即用的AutoAugment,相关的接口和PyTorch完全统一(反正也是cv来的),可以作为未来复现此类论文的一个基本模板,代码见我的仓库swin_transformer/data/data_utils文件夹
模型篇——混合精度
混合精度训练方法是通过混合使用单精度和半精度数据格式来加速深度神经网络训练的过程,同时保持了单精度训练所能达到的网络精度。混合精度训练能够加速计算过程,同时减少内存使用和存取,并使得在特定的硬件上可以训练更大的模型或batchsize。
这里我们主要针对MindSpore的混合精度和PyTorch(Apex)混合精度的区别做一些说明。
这里应该倒过来看,在笔者从模型训练、数据、性能角度都匹配了原基于PyTorch的SwinTransformer后,模型在10轮的时候会比同期PyTorch低1-2个点,这让人非常疑惑,因此最后联想到了混合精度。(不确定最后能不能靠O2跑到,一次三天实在等不起,就选择还是尽量同步源码了)
下面的理解是我基于MindSpore源码得到的,如果有错误希望指正。
首先是关于运算模式的一些定义:
- O0:纯FP32训练,可以作为accuracy的baseline;
- O1:混合精度训练(推荐使用),根据黑白名单自动决定使用FP16(GEMM, 卷积)还是FP32(Softmax)进行计算。
- O2:“几乎FP16”混合精度训练,不存在黑白名单,除了BatchNorm,几乎都是用FP16计算。
- O3:纯FP16训练,很不稳定,但是可以作为speed的baseline;
MindSpore拥有了O0、O2和O3,但是O1是缺省的,对于O2和O3,唯一的区别就是BN层是fp32还是fp16,那就是说如果不使用BN层的大多数ViT,O2和O3是一样的。
知道了这个区别之后,我们了解到Apex库中有对于fp16和fp32在O1模式下的名单,见
list
可以看到,实际在O1模式下,softmax、layernorm这类对精度影响较大的模块都会被保留在fp32,因此我们也选择将这些模块保存在fp32,进一步同步PyTorch。
关于转fp32和fp16的操作,选择直接去抄mindspore的amp.py文件:
print(f"=> using amp_level {args.amp_level}")
# 转换fp16
net.to_float(mstype.float16)
print(f"=> change {args.arch} to fp16")
# 转换fp32,反正swin就用了几个nn.Conv2d,主要还是nn.Dense,我就索性转fp32了
cell_types = (nn.GELU, nn.Softmax, nn.Conv2d, nn.Conv1d, nn.BatchNorm2d, nn.LayerNorm)
_do_keep_fp32(net, cell_types)
print(f"=> cast {cell_types} to fp32 back")
class OutputTo16(nn.Cell):
"Wrap cell for amp. Cast network output back to float16"
def __init__(self, op):
super(OutputTo16, self).__init__(auto_prefix=False)
self._op = op
def construct(self, x):
return F.cast(self._op(x), mstype.float16)
def _do_keep_fp32(network, cell_types):
cells = network.name_cells()
change = False
for name in cells:
subcell = cells[name]
if subcell == network:
continue
elif isinstance(subcell, cell_types):
network._cells[name] = OutputTo16(subcell.to_float(mstype.float32))
change = True
else:
# 这里是递归调用
_do_keep_fp32(subcell, cell_types)
if isinstance(network, nn.SequentialCell) and change:
network.cell_list = list(network.cells()
经过手动的MindSpore的O1模式转换后,十轮同期的精度正常了,然后可以放心往下跑了。
模型篇——性能调优
相对于V100 GPU来说,MindSpore基于CANN,拥有更加优秀的矩阵计算算法,这点非常赞,同时MindSpore的on-device执行 - MindSpore master documentation可以极大的提高数据加载和模型运行的效率。
相应的,目前让人感觉最深刻的就是MindSpore目前对于索引的优化可以说是相当不靠谱了,一旦模型中出现大量的索引算子,整个模型是性能会急剧下滑,甚至单步训练时长可能是同等条件下V100GPU的四五倍。
这里举几个例子,希望可以作为目前Ascend910性能瓶颈经典的几个坑:
例1 qkv范式的不同写法
"""qkv注意力写法1"""
self.qkv = nn.Dense(in_channels=dim, out_channels=dim * 3, has_bias=qkv_bias)
qkv = ops.Reshape()(self.qkv(x), (B_, N, 3, self.num_heads, C // self.num_heads))
qkv = ops.Transpose()(qkv, (2, 0, 3, 1, 4))
q, k, v = qkv[0]*self.scale, qkv[1], qkv[2]
"""qkv注意力写法2"""
self.q = nn.Dense(in_channels=dim, out_channels=dim, has_bias=qkv_bias)
self.k = nn.Dense(in_channels=dim, out_channels=dim, has_bias=qkv_bias)
self.v = nn.Dense(in_channels=dim, out_channels=dim, has_bias=qkv_bias)
q = ops.Reshape()(self.q(x), (B_, N, self.num_heads, C // self.num_heads))
k = ops.Reshape()(self.k(x), (B_, N, self.num_heads, C // self.num_heads))
k = ops.Transpose()(k, (0, 1, 3, 2))
v = ops.Reshape()(self.v(x), (B_, N, self.num_heads, C // self.num_heads))
这两种方法是目前最主流的self attention范式,在Ascend910上,强烈要求使用写法2。虽然这两者得到的最后解决是相同的,但是由于写法1用到了索引操作(哪怕的qkv[0]这么一点),在SwinTransformer上swin_tiny模型的单步训练时长会白白增加100ms最后(大约从600ms左右到700ms+),性能差距非常大。
例2 用reshape和Transpose代替一部分典型索引
"""写法1"""
x0 = x[:, 0::2, 0::2, :] # B H/2 W/2 C
x1 = x[:, 1::2, 0::2, :] # B H/2 W/2 C
x2 = x[:, 0::2, 1::2, :] # B H/2 W/2 C
x3 = x[:, 1::2, 1::2, :] # B H/2 W/2 C
x = torch.cat([x0, x1, x2, x3], -1) # B H/2 W/2 4*C
x = x.view(B, -1, 4 * C) # B H/2*W/2 4*C
"""写法2"""
x = P.Reshape()(x, (B, self.H_2, 2, self.W_2, 2, self.dim))
x = P.Transpose()(x, (0, 1, 3, 4, 2, 5))
x = P.Reshape()(x, (B, self.H2W2, self.dim_mul_4))
很容易可以理解,两者都是做了一个类似于反上采样和PixelShuffle的操作,将像素重排,这个形式的非常规则的,而且输入输出数量也是相同的。
在这种情况下,切记要使用同等的reshape操作,这个操作在这个模型使用较多的情况下,可以为模型再一次节约大量的时间,swin_tiny节约了大概150ms/step
容易知道,当kernel_size=strides的unfold的时候,也推荐之后这种方式,此处略过。
例3 用矩阵乘法代替索引
"""写法1"""
a = [1, 2, 3]
index = 2
a[index] => 3
"""写法2"""
a = [1, 2, 3]
index = 2
one_hot_index = [0, 0, 1] # predefine
a dot one_hot_index.T => 3
这里由于篇幅问题,不拿SwinTransformer的代码做说明(参见relative_position_index的使用处),简单说就是在索引固定的情况下,使用onehot和矩阵乘法来代替索引,只要索引够多,这种方法能为模型性能做很大贡献。
关于如何使用MindSpore的Profiler的性能调试工具,可以参见我的师兄的帖子
【昇腾众智】RetinaFace_ResNet50模型的910训练+310推理
模型篇——模型训练
关于如何使用MindSpore进行自定义训练,可以参考我的博客如何实现MindSpore自定义训练
这里主要对之前的博客留下来的问题进行一些解决(感觉昱峰哥提的建议,深受启发):
异构并行训练
异构并行训练方法是通过分析图上算子内存占用和计算密集度,将内存消耗巨大或适合CPU逻辑处理的算子切分到CPU子图,将内存消耗较小计算密集型算子切分到硬件加速器子图,框架协同不同子图进行网络训练,使得处于不同硬件且无依赖关系的子图能够并行进行执行的过程。
首先是关于异构并行计算方面的优化:
驱动源自MindSpore的这句话:在盘古或GPT3大模型训练过程中,优化器状态占用了大量内存,进而限制了可训练的模型规模。使用优化器异构,将优化器指定到CPU上执行,可以极大扩展可训练模型规模。
结合这两句话,我们很容易意识到,模型的权重保存和更新正好非常符合这种内存大且运算少的特性,之前那种将grad_sum和zero_op放在显存中运算是不合理的,我们要将这种运算都放在CPU里面去,为模型节约宝贵的显存,因此在这里我们对之前的操作进行一些优化:
- 不再自己重写TrainOneStepCell,而是从nn.TrainOneStepWithLossScaleCell继承(这个Cell包含了自动过滤overflow的梯度),减少实际的代码量,特别是关于分布式运算的管理。
- 将_sum_op和_clear_op全部丢到CPU里面去,根据异构计算中的模板即可
assignadd = P.AssignAdd()
assignadd.add_prim_attr("primitive_target", "CPU")
进一步的,考虑到在保存最后的权重的会包括grad_sum和zeros权重,这样子加上原来的optimizer包含的权重,相当于存了四个模型的大小权重,有什么方法可以优化呢?
我们可以去除zeros权重:
_sum_op = C.MultitypeFuncGraph("grad_sum_op")
assignadd = P.AssignAdd()
assignadd.add_prim_attr("primitive_target", "CPU")
# 相当于执行a -= a,a减去自己就可以得到0
self.hyper_map(F.partial(_sum_op), self._grad_sum, -self._grad_sum)
配合上clip_grad_norm,我们成功的从数据和模型都对原来基于PyTorch的SwinTransformer进行了全方位的复现,然后就该去ModelArts进行训练了~ 冲冲冲
ModelArts使用篇
ModelArts 是面向开发者的一站式 AI 开发平台,为机器学习与深度学习提供海量数据预处理及交互式智能标注、大规模分布式训练、自动化模型生成,及端-边-云模型按需部署能力,帮助用户快速创建和部署模型,管理全周期 AI 工作流。
上面的介绍摘自华为云的官方,也就当个大概的介绍,大家可以将这个理解成一个高效的深度学习平台吧。
首先简单介绍一个华为云ModelArts使用的感受:
- 快:不知道是由于Ascend910ProA和Ascend910B的不同,相同的代码在ModelArts跑起来就是比线下的910B服务器要快100ms/step左右。猜想有可能是因为云服务器环境稳定,或者就是传说中的ModelArts对分布式运算做了特定优化。
- 开销大:V100八卡需要195一小时,Ascend910八卡155一小时,SwinTransformer一跑就是3天,1w代金券直接走了 T T
- 难入门,入门后很方便:要不是本地的910NPU资源不够,内心一直是很抗拒使用云服务器的,因为当时缺少合适的文档,官网的教程还误导了我,导致学习成本极高。后来在自己的摸索下,终于解决了其中的坑点,直到后来群里才发了使用文档才发现坑白踩了。这里推荐一份很详细的文档,来自东北大学的一位老兄,写的非常详细:【ModelArts】鹏城云脑实验平台(华为云ModelArts)使用教程
解决完之后就可以安心训练,并且可以保存训练参数,启动训练只需要动动鼠标,再也不用敲命令行写脚本了!
结果篇
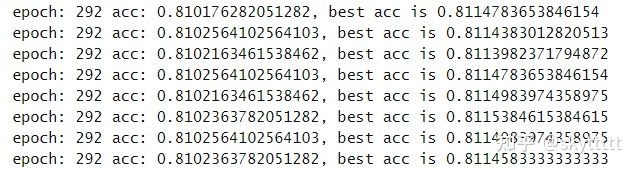
论文当时拿他的权重跑出来是81.15%,复现了一个月,终于到了,果然这种论文还是得各种同步作者的操作~。
这一个月踩了各种MindSpore的坑,感觉自己更懂MindSpore了。
感谢鹏城实验室提供的计算资源、华为工作人员的配合与问题的解答、调试群同学的帮助,希望大家都能调出自己的模型指标。















 692
692











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









