






小Mi前天一不留意瞄了眼公众号,发现竟然已经有了YOLOv7,顿时感觉自己落后的不是一星半点,印象中还是YOLOv5来着,怎么大伙的科研速度跟火箭有的一拼?吓得小Mi赶紧补功课。废话不多说(是不是还是熟悉的配方),今天开始先跟大家从CNN开始复习吧~

鼻祖来了
好了,首先详细解释下,为什么要先从CNN 开始复习呢?因为我们常见的很多网络,比如LeNet、Alexnet、VGG、RCNN、Fast RCNN、Faster RCNN、YOLO、YOLOv2、SSD等等这些网络模型的鼻祖就是CNN,只不过后面的各个儿子孙子如神仙打架一般,在各自的领域发挥着自身的优势,比如Lenet、Alexnet、Googlenet、VGG主要面向图像分类任务,RCNN、fastRCNN、fasterRCNN等作为目标检测任务的算法,而YOLO、SSD、YOLOv2又是不同于RCNN系列的另一类目标检测算法。所以是不是鼻祖很重要呢!(鼻祖的创始人Yann LeCun是第一个通过卷积神经网络在MNIST数据集上解决手写数字问题的人。)
网络结构
在这之前,小Mi已经在之前的深度学习系列中对深度神经网络有过简单的介绍(【MindSpore易点通】深度学习系列:深度神经网络_MindSpore_昇腾_华为云论坛),卷积神经网络结构包括:输入层Input layer、卷积层Convolution Layer、池化层Pooling layer、全连接层Full connection Layer和输出层Output Layer。
输入层
该层要做的处理主要是对原始图像数据进行预处理,比如去均值、归一化、PCA降维等等。
卷积层
好啦,为什么我们这个网络要叫卷积神经网络呢?那么重点就来了。
首先让我们以最常见的二维卷积层为例,看下卷积层是如何工作的吧~
在二维卷积层中,一个二维输入数组和一个二维核(kernel)数组通过互相关
运算输出一个二维数组。如图所示,输⼊是一个3×3的二维数组,卷积核是一个2×2的二维数组。
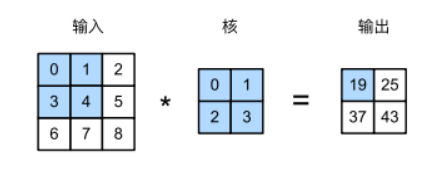
二维互相关运算
输出结果中数字19的计算公式为:0×0+1×1+3×2+4×3=19
在二维互相关运算中,卷积窗口从输⼊数组的最左上方开始,按从左往右、从上往下的顺序,依次在输入数组上滑动。当卷积窗口滑动到某一位置时,窗口中的输入子数组与核数组按元素相乘并求和,得到输出数组中相应位置的元素。
那么剩下的三个元素计算公式为:
1×0+2×1+4×2+5×3=25,
3×0+4×1+6×2+7×3=37,
4×0+5×1+7×2+8×3=43。
二维卷积层输出的二维数组可以看作是输入在空间维度(宽和高)上某⼀级的表征,也叫特征图(feature map)。影响元素x的前向计算的所有可能输入区域(可能大于输入的实际尺寸)叫做x的感受野(receptive field)。以上图为例,输入中阴影部分的四个元素是输出中阴影部分元素的感受野。将输出记为Y,如果Y与另一个形状为2×2的核数组做互相关运算,输出单个元素 z。那么,z在Y上的感受野包括Y的全部四个元素,在输入上的感受野包括其中全部9个元素。可见,可以通过更深的卷积神经网络使特征图中单个元素的感受野变得更加⼴阔,从而捕捉输入上更大尺寸的特征。
因此卷积层的输出形状由输入形状和卷积核窗口形状决定,其中最重要的两个超参数便是填充和步幅了。
填充(padding)是指在输入高和宽的两侧填充元素(通常是为0)。下图中在原输入高和宽的两侧分别添加了0的元素,使得输入高和宽从3变成了5,并导致输出高和宽由2增加到4。

在输入的高和宽两侧分别填充了0元素的二维互相关计算
而卷积窗口从输入数组的最左上方开始,按从左往右、从上往下的顺序,依次在输入数组上滑动,每次滑动的行数和列数就叫做步幅(stride)。在高和宽两个方向上步幅均为1,当然也可以使用更大步幅。比如下图就展示了在高上步幅为3、在宽上步幅为2的二维互相关运算。可以看到,输出第一列第二个元素时,卷积窗口向下滑动了三行。而在输出第一行第二个元素时卷积窗口向右滑动了两列。当卷积窗口在输入上再向右滑动两列时,由于输入元素无法填满窗口,无结果输出。
高和宽上步幅分别为3和2的二维互相关运算
其实通过各种实验最终我们可以发现,填充可以增加输出的高和宽,可以使得输出与输入具有相同的高和宽,而步幅可以减小输出的高和宽,例如输出的高和宽仅为输入的高和宽的1/n(n为大于1的整数)。当然啦,为什么我们一直强调是二维卷积层呢?输出的结果肯定也会与输入的数组维度有关啦,大家可以自行研究下~
池化层
池化(pooling)层的提出是为了缓解卷积层对位置的过度敏感性。
不同于卷积层里计算输入和核的互相关性,池化层直接计算池化窗口内元素的最大值或者平均值。在最大池化中,池化窗口从输⼊数组的最左上方开始,按从左往右、从上往下的顺序,依次在输入数组上滑动。当池化窗口滑动到某⼀位置时,窗口中的输入子数组的最大值即输出数组中相应位置的元素。

池化窗口形状为2×2的最大池化
阴影部分为第⼀个输出元素及其计算所使用的输入元素:max(0, 1, 3, 4) = 4
剩下三个元素分别为:
max(1, 2, 4, 5) = 5,
max(3, 4, 6, 7) = 7,
max(4, 5, 7, 8) = 8.
那么平均池化的共作原理也就很好理解咯。
因此池化操作就是图像的resize,就好比一张狗的图像被缩小了一倍我们还能认出狗,图像压缩时去掉的信息只是一些无关紧要的信息,而留下的信息则是具有尺度不变性的特征;同时还进行了特征降维,去除了很多无用或重复信息,并在一定程度上防止过拟合,更方便优化。
全连接层
这里的全连接与我们之前讲到的全连接并没有任何差异,经过池化层处理得到的结果中的所有元素都有权重连接:

其中,x1、x2、x3为全连接层的输入,a1、a2、a3为输出,
总结
当然啦,今天跟大家分享的卷积神经网络都是从最简单的方面逐步介绍的,既然是深度学习网络系列,我们平常遇到的网络可不是只有几个二维数组,一两个卷积层那么简单,CNN在本质上是一种输入到输出的映射,它能够学习大量的输入与输出之间的映射关系,而不需要任何输入和输出之间的精确的数学表达式,只要用已知的模式对卷积网络加以训练,网络就具有输入输出对之间的映射能力。希望大家在我的基础上,继续学习开始跟大家提到的各种“子孙”网络吧(LeNet、Alexnet、VGG、RCNN、YOLO等等等等)!















 1419
1419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









