






1 报错描述
1.1 系统环境
Hardware Environment(Ascend/GPU/CPU): GPU
Software Environment:
– MindSpore version (source or binary): 1.2.0
– Python version (e.g., Python 3.7.5): 3.7.5
– OS platform and distribution (e.g., Linux Ubuntu 16.04): Ubuntu 4.15.0-74-generic
– GCC/Compiler version (if compiled from source):
1.2 基本信息
1.2.1源码
https://gitee.com/mindspore/mindspore/tree/master/model_zoo/official/nlp/lstm
1.2.2报错
报错信息:ValueError:invalid literal for int()with base10’the’.
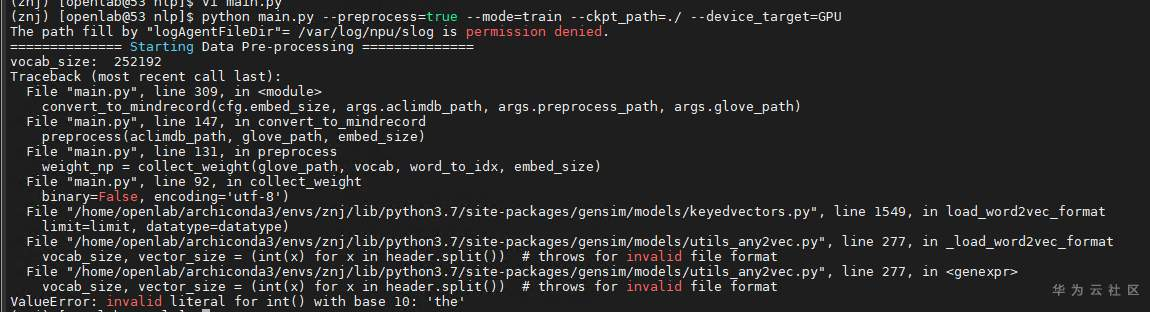
2 原因分析
未按照教程处理数据集,README里说明了需要对数据集添加一行,用来读取40万个单词,每个单词由300维度的词向量来表示。
3 解决方法
在glove.6B.300d.txt文件的第一行之前插入一行:400000 300
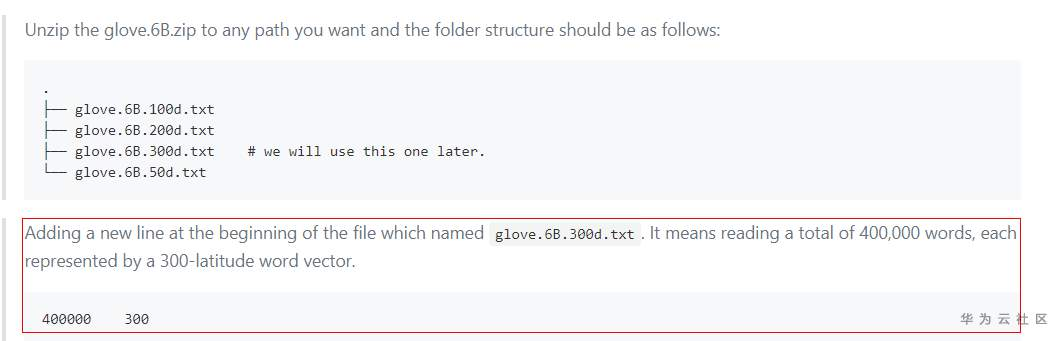
4 总结
运行官方教程中model时,尽量做到对照README中的步骤去执行,遗漏了数据处理的步骤可能导致报错。
5 参考文档
official/nlp/lstm/README_CN.md · MindSpore/models - Gitee.com















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









