







简介
在本实验中,我们将实现spawn,一个加载并运行磁盘可执行文件的库调用。 然后,我们要充分利用内核和操作系统库,以便在控制台上运行shell。 这些功能需要一个文件系统,本实验室引入了一个简单的读/写文件系统。
You should run the pingpong, primes, and forktree test cases from lab 4 again after merging in the new lab 5 code.
按照文档说明注释掉两条语句后运行python grade-lab4,一开始发现 lab4 的 Test 都过不了了。 发现不知道为什么几句 cprintf 被注释掉了,而且输出也有了一丝变化,在env_free and env_alloc取消掉相应注释就好啦。有惊无险,let’s move.
File system preliminaries
我们要完成一个相对简单的文件系统,其可以实现创建、读、写以及删除在分层目录结构中组织的文件。目前我们的OS只支持单用户,因此我们的文件系统也不支持UNIX文件拥有或权限的概念。同时也不支持硬链接、符号链接、时间戳或是特别的设备文件。
On-Disk File System Structure
大多是 Unix 文件系统将磁盘空间分为 inode和数据 区域。目录包含文件名和指向inode的指针; 如果文件系统中的多个目录引用该文件的inode,则称文件是硬链接的。由于我们的文件系统不需要支持硬链接,因此我们不需要这一间接层并且能做一个方便的简化:我们的文件系统根本不使用inode,相反我们仅仅将所有文件(或子目录)的 meta-data存储在描述该文件的唯一的目录中。
我们的文件系统允许用户环境直接读取目录元数据(例如,通过 read),这意味着用户环境本身可以执行目录扫描操作(例如,实现ls),而不必依赖额外的特殊调用 到文件系统。 目录扫描的这种方法的缺点,以及大多数现代UNIX变体不鼓励这种做法的原因在于,它使应用程序依赖于目录元数据的格式,使得难以在不改变或至少改变文件系统的内部布局的情况下 重新编译应用程序。
Sectors and Blocks
扇区是对磁盘的概念,块是对OS的概念。 块的 size 必须是扇区size 的整数倍。
Superblocks
文件系统通常在磁盘上的“易于查找”位置保留某些磁盘块(例如从最开始或最后)以保存描述文件系统属性的元数据,例如块大小 ,磁盘大小,查找根目录所需的任何元数据,上次挂载文件系统的时间,文件系统上次检查错误的时间等等。 这些特殊块称为超级块。
Our file system will have exactly one superblock, which will always be at block 1 on the disk. Its layout is defined by struct Super in
inc/fs.h.
struct Super {
uint32_t s_magic; // Magic number: FS_MAGIC
uint32_t s_nblocks; // Total number of blocks on disk
struct File s_root; // Root directory node
};
File Meta-data
The layout of the meta-data describing a file in our file system is described by struct File in
inc/fs.h. Unlike in most “real” file systems, for simplicity we will use this one File structure to represent file meta-data
as it appears both on disk and in memory.
struct File {
char f_name[MAXNAMELEN]; // filename
off_t f_size; // file size in bytes
uint32_t f_type; // file type
// Block pointers.
// A block is allocated iff its value is != 0.
uint32_t f_direct[NDIRECT]; // direct blocks
uint32_t f_indirect; // indirect block
// Pad out to 256 bytes; must do arithmetic in case we're compiling
// fsformat on a 64-bit machine.
uint8_t f_pad[256 - MAXNAMELEN - 8 - 4*NDIRECT - 4];
} __attribute__((packed)); // required only on some 64-bit machines
Directories versus Regular Files
我们的文件系统中的超级块包含一个 File结构,其保存了文件系统根目录的元数据。这个目录文件的内容是一系列文件结构体,其描述了文件系统根目录下的文件和目录。任何根目录下的子目录可能包含更多表示子子目录的文件结构体,以此类推。
The File System
我们实现的文件系统的关键部分是,读数据到缓存中并能写回到磁盘;分配磁盘块; 将文件偏移映射到磁盘块; 并在IPC接口中实现读,写和打开。
Disk Access
我们不采用传统的宏内核操作系统策略。其将 IDE(Integrated Drive Electronics,电子集成驱动器) 磁盘驱动添加到内核中,并提供一些必要的系统来允许文件系统访问它。相反,我们以用户级文件系统环境的形式来实现 IDE disk driver。我们仍然需要稍微修改内核,以便文件系统环境具有实现磁盘访问本身所需的权限。
内核必须在接收设备中断并将它们分派到正确的用户模式环境。
The x86 processor uses the IOPL bits in the EFLAGS register to determine whether protected-mode code is allowed to perform special device I/O instructions such as the IN and OUT instructions.
Note that the GNUmakefile file in this lab sets up QEMU to use the file obj/kern/kernel.img as the image for disk 0 (typically “Drive C” under DOS/Windows) as before, and to use the (new) file obj/fs/fs.img as the image for disk 1 (“Drive D”). In this lab our file system should only ever touch disk 1; disk 0 is used only to boot the kernel. If you manage to corrupt either disk image in some way, you can reset both of them to their original, “pristine” versions simply by typing:
Execise 1
i386_init identifies the file system environment by passing the type ENV_TYPE_FS to your environment creation function, env_create. Modify env_create in env.c, so that it gives the file system environment I/O privilege, but never gives that privilege to any other environment.
在load_icode之前加入以下判断即可。
if (type == ENV_TYPE_FS) {
newenv->env_tf.tf_eflags |= FL_IOPL_MASK;
}
Question
- 你是否不得不做一些其他事来确保当环境不断切换时,I/O特权设定依然能被保存和恢复? 为什么?
不需要,因为在环境切换时,会保存eflags的值,也会用 env_pop_tf恢复eflags的值。
The Block Cache
we will implement a simple “buffer cache” (really just a block cache).
我们为文件系统环境保留了巨大固定的地址空间,从 0x10000000 (DISKMAP)到0xD0000000 (DISKMAP+DISKMAX),作为磁盘的内存映射。 For example, disk block 0 is mapped at virtual address 0x10000000, disk block 1 is mapped at virtual address 0x10001000, and so on.
由于我们的文件系统有独立于系统中其他环境的虚拟地址空间(不重叠),因为我们的文件系统唯一需要做的事是实现文件的 access。如此看来我们为文件系统保留大量的空间也是十分合理的。
Of course, it would take a long time to read the entire disk into memory, so instead we’ll implement a form of demand paging, wherein we only allocate pages in the disk map region and read the corresponding block from the disk in response to a page fault in this region.
Execise 2
Implement the bc_pgfault and flush_block functions in fs/bc.c.
如之前说明的,块号与扇区号有一定的区别,在完成这两个函数时,要注意区分这两个概念。 JOS 块大小位4kB,扇区大小为512B,每次读写一个块,就需要读写4个扇区。因此,JOS使用了一个宏定义#define BLKSECTS (BLKSIZE / SECTSIZE)来描述两者的关系。
- bc_pgfault(struct UTrapframe *utf)
// LAB 5: you code here:
// envid 传入 0? 在最初的哪个进程下 alloc 一个page ?
addr =(void *) ROUNDDOWN(addr, PGSIZE);
if ( (r = sys_page_alloc(0, addr, PTE_P|PTE_W|PTE_U)) < 0) {
panic("in bc_pgfault, sys_page_alloc: %e", r);
}
// size_t secno = (addr - DISKMAP) / BLKSIZE;
if ( (r = ide_read(blockno*BLKSECTS, addr, BLKSECTS)) < 0) {
panic("in bc_pgfault, ide_read: %e",r);
}
- flush_block(void *addr)
// LAB 5: Your code here.
addr = (void *)ROUNDDOWN(addr, PGSIZE);
if (va_is_mapped(addr) && va_is_dirty(addr)) {
ide_write(blockno*BLKSECTS, addr , BLKSECTS);
if ((r = sys_page_map(0, addr, 0, addr, uvpt[PGNUM(addr)] & PTE_SYSCALL)) < 0)
panic("in flush_block, sys_page_map: %e", r);
}
Challenge
The block cache has no eviction policy. Once a block gets faulted in to it, it never gets removed and will remain in memory forevermore. Add eviction to the buffer cache. Using the PTE_A “accessed” bits in the page tables, which the hardware sets on any access to a page, you can track approximate usage of disk blocks without the need to modify every place in the code that accesses the disk map region. Be careful with dirty blocks.
The Block Bitmap(位图块)
After fs_init sets the bitmap pointer, we can treat bitmap as a packed array of bits, one for each block on the disk. bitmap = diskaddr(2);,位图存放在 2 号块中。操作系统课程一般都会提到这个概念,位图概念也挺好理解的。每一个bit 标记一个 block 是否 free。
uint32_t *bitmap; // bitmap blocks mapped in memory
Exercise 3
Use free_block as a model to implement alloc_block in fs/fs.c, which should find a free disk block in the bitmap, mark it used, and return the number of that block.
我们以一个实例来分析 bitmap的工作原理, 若标记第35个块(块号为34)为使用状态, 则将bitmap[1] 的第 2 (34%32)位标记为 0。 讲道理应该位图位为0是free的呀,JOS这里反过来了。
int
alloc_block(void)
{
// The bitmap consists of one or more blocks. A single bitmap block
// contains the in-use bits for BLKBITSIZE blocks. There are
// super->s_nblocks blocks in the disk altogether.
// LAB 5: Your code here.
size_t i;
for(i=1; i < super->s_nblocks; i++) {
if (block_is_free(i)) {
// 清零,标记已经使用。有点令人费解
bitmap[i/32] &= ~(1<<(i%32));
flush_block(&bitmap[i/32]);
return i;
}
}
// panic("alloc_block not implemented");
return -E_NO_DISK;
}
File Operations
Exercise 4
Implement file_block_walk and file_get_block. file_block_walk maps from a block offset within a file to the pointer for that block in the struct File or the indirect block, very much like what pgdir_walk did for page tables. file_get_block goes one step further and maps to the actual disk block, allocating a new one if necessary.
- file_block_walk 获得文件第
filebno块的地址(其本身是个指针),编写需要注意以下几点。具体实现,看代码就好啦。
ppdiskbno是块指针(记录块的地址)f_indirect直接记录块号,而不是记地址。- Don’t forget to clear any block you allocate. 对分配的块进行清零操作后,要写入 disk 中。
static int
file_block_walk(struct File *f, uint32_t filebno, uint32_t **ppdiskbno, bool alloc)
{
// LAB 5: Your code here.
// ppdiskbno 块指针
if (filebno < NDIRECT) {
// but note that *ppdiskbno might equal 0
if(ppdiskbno)
*ppdiskbno = &(f->f_direct[filebno]);
else
return 0;
}
if (filebno >= NDIRECT + NINDIRECT)
return -E_INVAL;
filebno -= NDIRECT;
// indirect 还未分配
if (!!f->f_indirect) {
if (alloc == 0)
return -E_NOT_FOUND;
// 分配一个 indirect block
uint32_t blockno;
if ( (blockno = alloc_block()) < 0)
return blockno;
// f_indirect 直接记录块号,而不是记地址
// f->f_indirect = (uint32_t)diskaddr(blockno);
f->f_indirect = blockno;
memset(diskaddr(blockno), 0, BLKSIZE);
flush_block(diskaddr(blockno));
}
if (ppdiskbno)
*ppdiskbno = (uint32_t *)diskaddr(f->f_indirect) + filebno;
return 0;
// panic("file_block_walk not implemented");
}
- file_get_block()
int
file_get_block(struct File *f, uint32_t filebno, char **blk)
{
// LAB 5: Your code here.
uint32_t *pdiskbno;
int r;
if ( (r = file_block_walk(f, filebno, &pdiskbno, 1))< 0)
return r;
if(*pdiskbno == 0) {
// 文件块还未分配
if ( (r = alloc_block()) < 0)
return r;
*pdiskbno = r;
memset(diskaddr(r), 0, BLKSIZE);
flush_block(diskaddr(r));
}
// 最终指向块
*blk = diskaddr(*pdiskbno);
return 0;
//panic("file_get_block not implemented");
}
The file system interface
感觉这部分才是这个Lab的重点。一直听说的RPC原来是 Remote Procedure Call 的缩写。
它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。在OSI网络通信模型中,RPC跨越了传输层和应用层。RPC使得开发包括网络分布式多程序在内的应用程序更加容易。
由于其他环境无法直接调用文件系统环境中的函数,因此我们将通过 RPC 或在JOS的IPC机制上构建的RPC抽象来公开对文件系统环境的访问。 为什么不能直接调用?不都是用户环境的函数么,是特意不让别的环境直接使用?
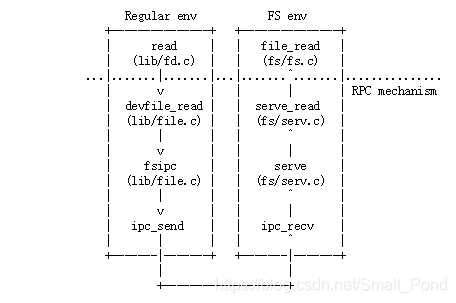
在开始时,read只需调度到适当的设备读取函数,就可以适用于任何文件描述符,在本例中为devfile_read(我们可以有更多的设备类型,如管道)。 devfile_read专门为磁盘文件实现读取。 这个和lib / file.c中的其他devfile_ *函数实现了FS操作的客户端,并且所有工作都以大致相同的方式工作,在请求结构体中捆绑参数,调用fsipc发送IPC请求,以及解包和返回 结果。 fsipc函数只处理向服务器发送请求和接收回复的常见细节。
文件系统的服务端代码在 fs/serv.c中。
- 32-bit number for the request type.
- store the arguments to the request in a union Fsipc on the page shared via the IPC.
3.5.1. Exercise 5
Implement serve_read in fs/serv.c.
Fsipc 联合体是个 sao 操作噢。
union Fsipc {
struct Fsreq_open {
char req_path[MAXPATHLEN];
int req_omode;
} open;
struct Fsreq_set_size {
int req_fileid;
off_t req_size;
} set_size;
struct Fsreq_read {
int req_fileid;
size_t req_n;
} read;
struct Fsret_read {
char ret_buf[PGSIZE];
} readRet;
struct Fsreq_write {
int req_fileid;
size_t req_n;
char req_buf[PGSIZE - (sizeof(int) + sizeof(size_t))];
} write;
struct Fsreq_stat {
int req_fileid;
} stat;
struct Fsret_stat {
char ret_name[MAXNAMELEN];
off_t ret_size;
int ret_isdir;
} statRet;
struct Fsreq_flush {
int req_fileid;
} flush;
struct Fsreq_remove {
char req_path[MAXPATHLEN];
} remove;
// Ensure Fsipc is one page
char _pad[PGSIZE];
};
OpenFile结构是服务端进程维护的一个映射,它将一个真实文件struct File和用户客户端打开的文件描述符struct Fd对应到一起。
struct OpenFile {
uint32_t o_fileid; // file id
struct File *o_file; // mapped descriptor for open file
int o_mode; // open mode
struct Fd *o_fd; // Fd page
};
struct Fd {
int fd_dev_id;
off_t fd_offset;
int fd_omode;
union {
// File server files
struct FdFile fd_file;
};
};
查看serve_set_size的实现流程,我们不难写出serve_read,首先使用参数envid 以及fileid调用lookup可以得到 openfile 信息。然后调用已有的实现file_read即可将数据读到 ret 的 buff 中,实现文件数据的传递。其中要注意一下细节部分,要更改文件的 offset ! 实际也不用考虑请求的n是否会大于BLOCKSIZE,在file_read中进行了大小处理count = MIN(count, f->f_size - offset);,其只会读取较小的一部分。
int
serve_read(envid_t envid, union Fsipc *ipc)
{
struct Fsreq_read *req = &ipc->read;
struct Fsret_read *ret = &ipc->readRet;
int r, reqn;
// Lab 5: Your code here:
struct OpenFile *of;
if ( (r = openfile_lookup(envid, req->req_fileid, &of) )< 0)
return r;
if ( (r = file_read(of->o_file, ret->ret_buf, req->req_n, of->o_fd->fd_offset))< 0)
return r;
// then update the seek position.
of->o_fd->fd_offset += r;
return r;
}
Exercise 6
Implement
serve_writeinfs/serv.canddevfile_writeinlib/file.c.
struct Fsreq_write {
int req_fileid;
size_t req_n;
char req_buf[PGSIZE - (sizeof(int) + sizeof(size_t))];
} write;
serve_write:serve_write的实现很简单,参考上个Exe的代码即可。 同时我们关注一个细节,在file_write中考虑了块边界的问题bn = MIN(BLKSIZE - pos % BLKSIZE, offset + count - pos);,因此我们同样不需要对 req_n 进行处理。
int
serve_write(envid_t envid, struct Fsreq_write *req)
{
if (debug)
cprintf("serve_write %08x %08x %08x\n", envid, req->req_fileid, req->req_n);
int r;
struct OpenFile *of;
int reqn;
if ( (r = openfile_lookup(envid, req->req_fileid, &of)) < 0)
return r;
reqn = req->req_n > PGSIZE? PGSIZE:req->req_n;
if ( (r = file_write(of->o_file, req->req_buf, reqn, of->o_fd->fd_offset)) < 0)
return r;
of->o_fd->fd_offset += r;
return r;
}
devfile_write: 根据上面RPC机制的图,我们的devfile_write需要调用fsipc,其向文件服务器发送一个进程间请求,并等待回复。请求体保存在fsipcbuf中,回复部分也应该写回到fsipcbuf中。
static ssize_t
devfile_write(struct Fd *fd, const void *buf, size_t n)
{
// LAB 5: Your code here
int r;
if ( n > sizeof (fsipcbuf.write.req_buf))
n = sizeof (fsipcbuf.write.req_buf);
fsipcbuf.write.req_fileid = fd->fd_file.id;
fsipcbuf.write.req_n = n;
memmove(fsipcbuf.write.req_buf, buf, n);
return fsipc(FSREQ_WRITE, NULL);
}
Spawning Processes
We have given you the code for spawn (see lib/spawn.c) which creates a new environment, loads a program image from the file system into it, and then starts the child environment running this program. The parent process then continues running independently of the child. spawn函数表现得像在Unix下创建子进程带有一个立刻执行exec的fork函数。
我们实现了spawn而不是UNIX风格的exec,因为在没有内核特殊帮助的情况下,spawn更容易以“exokernel fashion”从用户空间实现。
Exercise 7
spawn relies on the new syscall
sys_env_set_trapframeto initialize the state of the newly created environment. Implement sys_env_set_trapframe inkern/syscall.c(don’t forget to dispatch the new system call in syscall()).
直接跳到 sys_env_set_trapframe 有点摸不着头脑,也不知道该 save 哪些内容。先阅读一下 spawn实现的关键代码。
// Create new child environment
if ((r = sys_exofork()) < 0)
return r;
// 父进程返回子进程的PID
child = r;
// Set up trap frame, including initial stack.
// 复制 tf, 修改eip 指向子进程代码进入点
child_tf = envs[ENVX(child)].env_tf;
child_tf.tf_eip = elf->e_entry;
// 利用栈向子进程传递参数
if ((r = init_stack(child, argv, &child_tf.tf_esp)) < 0)
return r;
// Set up program segments as defined in ELF header.
...
...
close(fd);
fd = -1;
// Copy shared library state.
if ((r = copy_shared_pages(child)) < 0)
panic("copy_shared_pages: %e", r);
child_tf.tf_eflags |= FL_IOPL_3; // devious: see user/faultio.c
if ((r = sys_env_set_trapframe(child, &child_tf)) < 0)
panic("sys_env_set_trapframe: %e", r);
// 子进程可运行
if ((r = sys_env_set_status(child, ENV_RUNNABLE)) < 0)
panic("sys_env_set_status: %e", r);
return child;
在spawn中对 child_tf 进行了一系列的初始化,最后我们需要调用sys_env_set_trapframe来设定子环境的tf。不过这里为什么要传child_tf的指针呢,一开始我还以为是将env的tf 复制到 child_tf 中。只是为了减小传递内容的大小吗? env->env_tf.tf_cs |= 0x3;保证了子进程在用户态运行。
static int
sys_env_set_trapframe(envid_t envid, struct Trapframe *tf)
{
struct Env *env;
int r;
if ( (r = envid2env(envid, &env, 1)) < 0)
return r;
// 什么时候会出现没有权限访问的问题?
user_mem_assert(env, tf, sizeof(struct Trapframe), PTE_U);
// 直接整个结构体也是可以赋值的
env->env_tf = *tf;
env->env_tf.tf_cs |= 0x3;
env->env_tf.tf_eflags &= (~FL_IOPL_MASK);
env->env_tf.tf_eflags |= FL_IF;
return 0;
}
Sharing library state across fork and spawn
在JOS中,每个设备类型都具有相应的struct Dev,其中包含指向实现读/写/等的函数指针。对于该设备类型。 lib / fd.c在此基础上实现了类似UNIX的通用文件描述符接口。 每个结构体Fd表示它的设备类型,lib/fd.c中的大多数函数只是将操作分派给适当的struct Dev中的函数。
// Per-device-class file descriptor operations
struct Dev {
int dev_id;
const char *dev_name;
ssize_t (*dev_read)(struct Fd *fd, void *buf, size_t len);
ssize_t (*dev_write)(struct Fd *fd, const void *buf, size_t len);
int (*dev_close)(struct Fd *fd);
int (*dev_stat)(struct Fd *fd, struct Stat *stat);
int (*dev_trunc)(struct Fd *fd, off_t length);
};
lib/fd.c 还在每个应用程序环境的地址空间中维护一个文件描述符表区域,从FDTABLE开始。 该区域为应用程序一次性打开的最多MAXFD(当前为32个)文件描述符保留一个页面(4KB)的地址空间。 在任何给定时间,当且仅当相应的文件描述符正在使用时,才映射特定的文件描述符表页面。 每个文件描述符在从FILEDATA开始的区域中也有一个可选的“data page”,设备可以选择使用。
**We would like to share file descriptor state across fork and spawn, but file descriptor state is kept in user-space memory. **
现在,在fork中,内存将被标记为 COW,所以状态会被复制而不是共享。(这意味着环境将无法在文件中寻找他们自己没有打开的文件,而且管道也无法在fork中工作。)why?
在spawn上,内存将被left behind,而不是复制。(实际上,生成的环境从没有打开的文件描述符开始。)
我们将更改fork以了解“库操作系统”使用的某些内存区域,并且应始终共享。 我们不会在某个地方硬编码区域列表,而是在页表条目中设置一个未使用的位(就像我们在fork中使用PTE_COW位一样)。
我们在inc/lib.h中定义了一个新的PTE_SHARE位。 该位是Intel和AMD手册中标记为“可供软件使用”的三个PTE位之一。 我们将建立一个约定,即如果页表项已设置此位,则应在fork和spawn中将PTE直接从父进程复制到子进程。 请注意,这与标记copy-on-write不同:如第一段所述,我们希望确保共享页面更新。
Exercise 8
Change
duppageinlib/fork.cto follow the new convention. If the page table entry has the PTE_SHARE bit set, just copy the mapping directly. (You should use PTE_SYSCALL, not 0xfff, to mask out the relevant bits from the page table entry. 0xfff picks up the accessed and dirty bits as well.)
Likewise, implementcopy_shared_pagesinlib/spawn.c. It should loop through all page table entries in the current process (just like fork did), copying any page mappings that have the PTE_SHARE bit set into the child process.
- duppage: 在最前面添加一个if 分支即可。
if (uvpt[pn] & PTE_SHARE) {
if((ret = sys_page_map(thisenv->env_id, (void *) va, envid, (void * )va, uvpt[pn] & PTE_SYSCALL)) <0 )
return ret;
}
else if ( (uvpt[pn] & PTE_W) || (uvpt[pn] & PTE_COW)) {
// 子进程标记
if ((ret = sys_page_map(thisenv->env_id, (void *) va, envid, (void *) va, PTE_P|PTE_U|PTE_COW)) < 0)
return ret;
// 父进程标记
if ((ret = sys_page_map(thisenv->env_id, (void *)va, thisenv->env_id, (void *)va, PTE_P|PTE_U|PTE_COW)) < 0)
return ret;
}
else {
// 简单映射
if((ret = sys_page_map(thisenv->env_id, (void *) va, envid, (void * )va, PTE_P|PTE_U)) <0 )
return ret;
}
return 0;
- copy_shared_pages: 其实现与 fork 中的循环类似。
static int
copy_shared_pages(envid_t child)
{
// LAB 5: Your code here.
size_t pn;
int r;
struct Env *e;
for (pn = PGNUM(UTEXT); pn < PGNUM(USTACKTOP); ++pn) {
if ( (uvpd[pn >> 10] & PTE_P) && (uvpt[pn] & PTE_P) ) {
if (uvpt[pn] & PTE_SHARE) {
if ( (r = sys_page_map(thisenv->env_id, (void *)(pn*PGSIZE), child, (void *)(pn*PGSIZE), uvpt[pn] & PTE_SYSCALL )) < 0)
return r;
}
}
}
return 0;
}
The keyboard interface
目前我们只能在内核监视器中才能接收输入。kern/console.c already contains the keyboard and serial drivers that have been used by the kernel monitor since lab 1, but now you need to attach these to the rest of the system.
Exercise 9
In your
kern/trap.c, callkbd_intrto handle trapIRQ_OFFSET+IRQ_KBDandserial_intrto handle trapIRQ_OFFSET+IRQ_SERIAL.
在/kern/console.c/cons_getc()中的代码,实现了在 monitor 模式下(禁止中断)可以正常获取用户输入。
// poll for any pending input characters,
// so that this function works even when interrupts are disabled
// (e.g., when called from the kernel monitor).
serial_intr();
kbd_intr();
在 trap.c 中加入中断处理函数。
case (IRQ_OFFSET + IRQ_KBD):
lapic_eoi();
kbd_intr();
break;
case (IRQ_OFFSET + IRQ_SERIAL):
lapic_eoi();
serial_intr();
break;
The Shell
Run make run-icode。 QEMU将运行内核并执行user/icode,icode 将 console 设置为 文件描述符 0 和 1。然后 spawn sh。
Exercise 10
The shell doesn’t support I/O redirection. It would be nice to run
sh <scriptinstead of having to type in all the commands in the script by hand, as you did above. Add I/O redirection for<touser/sh.c.
实现 I/O 重定向。第一反映就是解析<后的文件,通过打开文件获得文件描述符,再将此文件描述符传入关联到标准输入 0(使用dup实现),最后关闭之前获得的描述符。
if ( (fd = open(t, O_RDONLY) )< 0 ) {
fprintf(2,"file %s is no exist\n", t);
exit();
}
if (fd != 0) {
dup(fd, 0);
close(fd);
}
// LAB 5: Your code here.
// panic("< redirection not implemented");
break;
Challenge!
Add more features to the shell. Possibilities include (a few require changes to the file system too):
- backgrounding commands (ls &)
- multiple commands per line (ls; echo hi)
- command grouping ((ls; echo hi) | cat > out)
- environment variable expansion (echo $hello)
- quoting (echo “a | b”)
- command-line history and/or editing
- tab completion
- directories, cd, and a PATH for command-lookup.
- file creation
- ctl-c to kill the running environment
but feel free to do something not on this list.
巨坑 Bug
在Exercise 7 中出现了一个莫名其妙的bug。
make grade 时发生了一个错误,在此记录一下。spawn via spawnhello: OK之前 Protection I/O space都是 ok的。 但spawn via spawnhello: OK之后这个错误就一直存在,当时没有注意。
Protection I/O space: FAIL (2.7s)
AssertionError: ...
[00001002] exiting gracefully
...
qemu-system-i386: terminating on signal 15 from pid 21171 (make)
MISSING 'TRAP'
跟踪发现错误应该出现在一个 trap 上, 我写的代码没有产生本应出现的 trap。在user/faultio.c中。
// this outb to select disk 1 should result in a general protection
// fault, because user-level code shouldn't be able to use the io space.
outb(0x1F6, 0xE0 | (1<<4));
这个 bug 真是找了我三个小时, 一个个文件对比,最后才发现是trap.c和trapentry.S中的错误,~~应该是 General Protection handler 的锅。~~最终发现是trap.c中 trap_init_percpu出现了问题。因为一直没有涉及到I/O, 所以这个Bug也没有浮现。
加入一行代码thiscpu->cpu_ts.ts_iomb = sizeof(struct Taskstate);后就正常了。这次真的是被坑惨了,以前写的代码留下的 Bug,真是毒噢。现在是时候搞清楚trap_init_percpu都做了什么工作了。看了之前的代码,实际这条语句是有的,是我在Lab4 对各个 CPU进行初始化时以为没用给删了(捂脸!)
TSS 全称task state segment,是指在操作系统进程管理的过程中,任务(进程)切换时的任务现场信息。在任务切换过程中,首先,处理器中各寄存器的当前值被自动保存到TR(任务寄存器)所指定的TSS中;然后,下一任务的TSS的选择子被装入TR;最后,从TR所指定的TSS中取出各寄存器的值送到处理器的各寄存器中。由此可见,通过在TSS中保存任务现场各寄存器状态的完整映象,实现任务的切换。
uint16_t ts_iomb; // I/O map base address
总结
Lab5 主要介绍了文件系统的基本组成,为超级块分配易查找的位置,并在超级块中记录根目录文件,此后递进存储即实现了FS的多级目录。利用虚拟地址和MMIO实现了类似统一编址方式,我们可以很方便实现文件访问,其操作过程与内存访问很类似(在文件结构体中 walk 到块号)。
JOS在用户环境实现FS,FS接口是这个Lab的重点。其通过RPC公开接口,在JOS中利用IPC机制构建RPC抽象。regular env->read->ipc_send -> ipc_recv->serve->file_read。
这实际上以微内核的方式实现的FS,FS的serv相当于一种微服务进程,其接收、解析内核转发的信息再执行相应的操作。消息通过一个页映射的Union Fsipc进行传递。
spawn函数表现得像在Unix下创建子进程带有一个立刻执行exec的fork函数。exec()会把当前执行进程覆盖掉来执行外部程序,spawn()则会创建一个新的进程来执行。对于spawn的设计,还是有一些困惑,因为不明白 Unix-Style的exec是如何实现的,所以不能理解为什么spawn更容易在用户空间实现。
最后的Keyboard 接口和Shell都相对简单,比较容易理解。
Questions
- 其他环境无法直接调用文件系统环境中的函数,要通过IPC,进程间消息传递实现。这里应该就是微内核的概念了。但为什么不能直接调用,是怎么实现不能直接调用的?是特意不让别的环境直接使用其函数吗?有没有方法可以实现不同用户程序可以直接调用其他用户程序的函数?
不能直接调用,应该是因为每个用户态的代码都存在于自身的地址空间中,其他用户程序无法访问到。但是我如果在源代码中的某个环境直接#include并且调用另一个环境文件夹下的代码(例如fs),即在编译前就调用了,这会出现什么情况?这样就相当于是宏内核的概念了吗? 或者是这样设计会增大代码的耦合性?这让我十分疑惑。毕竟这与越过系统调用不一样,系统调用有权限限制。
- Execise7 :
spawn函数表现得像在Unix下创建子进程带有一个立刻执行exec的fork函数。Unix-style 的exec改如何实现,为什么在用户空间实现exec会更难呢?














 5843
5843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









