






Python Orange3是一个功能强大且易于使用的开源工具,结合了数据可视化、数据分析和机器学习,为数据科学家和分析师提供了一个全面的平台。在本文中,我们将深入介绍Python Orange3,包括其基本概念、安装方法、基本用法、功能特性、实际应用场景以及总结。
1. 库的介绍和作用
Python Orange3是用于数据分析、数据可视化和机器学习的工具。它提供了用户友好的图形用户界面(GUI),同时也支持通过Python脚本进行扩展和自定义。Orange3帮助用户轻松构建数据流程和分析模型,无需繁琐的编程操作。
2. 安装方法
要开始使用Python Orange3,首先需要安装Python,并通过以下命令安装Orange3:
pip install orange3 pip install orange-canvas
启动Orange3:运行orange-canvas命令来启动Orange3的图形用户界面,从而进行数据分析和机器学习任务。
3. 基本概念
Orange3使用图形界面,允许用户通过拖放操作构建数据流程和分析模型,省去了繁琐的代码编写过程。这种可视化编程使得用户更加直观地进行数据处理和分析。
4. 基本用法
Orange3是一个用于数据挖掘、机器学习和可视化的开源工具,具有强大的功能和易于使用的界面。以下是三个简单的示例,展示Orange3的基本用法。
1. 数据加载与展示
import Orange # 加载数据集 data = Orange.data.Table("iris") # 展示数据集的前几行 print(data[:5])
这段代码演示了如何加载经典的鸢尾花数据集(iris),并显示数据集的前五行。
2. 数据预处理与建模
import Orange # 加载数据集 data = Orange.data.Table("titanic") # 数据预处理 preprocessor = Orange.preprocess.Discretize() preprocessed_data = preprocessor(data) # 构建分类模型 learner = Orange.classification.TreeLearner() classifier = learner(preprocessed_data) # 预测新样本 new_instance = [30, "male", 0] predicted_class = classifier(new_instance) print("Predicted class:", predicted_class)
这个示例展示了如何加载泰坦尼克号数据集,进行数据预处理(离散化),然后使用决策树学习器构建分类模型,并对新样本进行分类预测。
3. 可视化分析
import Orange import matplotlib.pyplot as plt # 加载数据集 data = Orange.data.Table("housing") # 特征相关性可视化 correlation_heatmap = Orange.evaluation.scoring.Correlation(data) Orange.evaluation.visualize.plot_correlation(correlation_heatmap, data.domain.attributes) plt.show()
这个示例演示了如何加载房价数据集,计算特征之间的相关性,并使用Orange3内置的可视化工具绘制特征相关性热图。
通过以上示例,您可以初步了解Orange3工具的基本使用方法,包括数据加载与展示、数据预处理与建模以及可视化分析等功能。希望这些示例能够帮助您更好地利用Orange3进行数据分析和机器学习任务。
5. 功能特性
-
可视化编程:通过图形界面进行操作,无需编写代码。
-
数据可视化:提供丰富的数据可视化工具,帮助用户更好地理解数据。
-
机器学习:集成各种机器学习算法,支持构建和评估不同类型的模型。
-
数据预处理:提供丰富的数据预处理工具,包括特征选择、特征工程和数据清洗等。
-
数据集成:支持轻松集成不同数据源的数据,如CSV、Excel、SQL数据库等。
6. 实际应用场景
Orange3适用于数据科学家和分析师,有助于他们进行数据分析、数据可视化和机器学习建模。可以应用于各种领域,如商业分析、生物信息学、医疗健康等,在实际工作中发挥重要作用。
1、特征选择与建模
import Orange # 加载数据集 data = Orange.data.Table("wine") # 特征选择 subset = Orange.preprocess.SelectBestFeatures(k=5)(data) # 构建分类模型 learner = Orange.classification.TreeLearner() classifier = learner(subset) # 评估模型 results = Orange.evaluation.testing.cross_validation([learner], data) print(Orange.evaluation.scoring.CA(results))
这个案例演示了如何加载葡萄酒数据集,进行特征选择(选择最佳的5个特征),然后使用决策树学习器构建分类模型,并通过交叉验证评估模型性能。
2、聚类分析与可视化
import Orange # 加载数据集 data = Orange.data.Table("iris") # 聚类分析 kmeans = Orange.clustering.kmeans.Clustering(data, k=3) kmeans.run() # 可视化聚类结果 from Orange.widgets.visualize import OWScatterPlot from AnyQt.QtWidgets import QApplication ow = OWScatterPlot() ow.set_data(data, kmeans) ow.show() app = QApplication([]) app.exec_()
这个案例演示了如何加载鸢尾花数据集,使用k均值算法进行聚类分析,然后通过Orange3的散点图可视化工具展示聚类结果。需要注意的是,这段代码可能需要在交互式环境中运行以显示可视化结果。
通过以上示例,您可以进一步探索Orange3工具的功能,包括特征选择与建模、聚类分析与可视化等方面的操作。希望这些案例能够帮助您更深入地了解和应用Orange3进行数据分析和机器学习任务。
7. 总结
Python Orange3是一个功能强大的数据科学和机器学习工具,提供丰富的功能和易于使用的界面,帮助用户处理数据、进行数据探索和构建机器学习模型。不论您是初学者还是经验丰富的数据科学家,Orange3都能满足您的需求,让数据分析和机器学习变得更加容易和高效。
通过本文的介绍,希望读者能够更深入了解Python Orange3,并开始利用其强大功能进行数据科学工作。Orange3的灵活性和功能丰富性将为您的数据分析工作带来便利和效率,助力您在数据领域取得更多成就。
点击下方安全链接前往获取
CSDN大礼包:《Python入门&进阶学习资源包》免费分享
👉Python实战案例👈
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
👉Python书籍和视频合集👈
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
👉Python副业创收路线👈
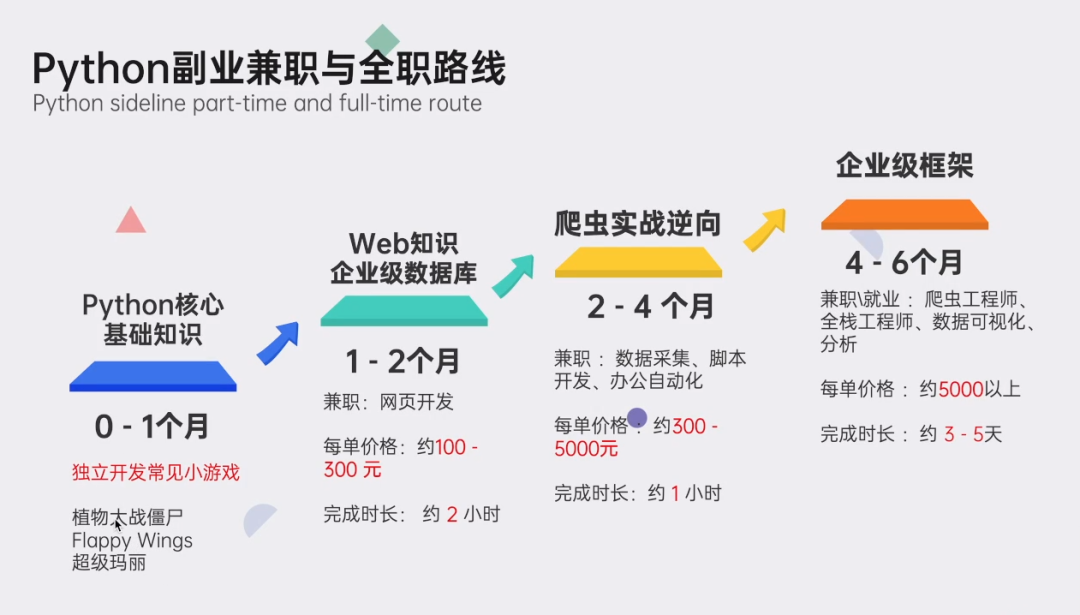
这些资料都是非常不错的,朋友们如果有需要《Python学习路线&学习资料》,点击下方安全链接前往获取
CSDN大礼包:《Python入门&进阶学习资源包》免费分享
本文转自网络,如有侵权,请联系删除。















 2400
2400











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









