







本篇介绍一个适合初学者入门的机器学习工具。
Orange 简介
Orange 是一个开源的数据挖掘和机器学习软件。Orange 基于 Python 和 C/C++ 开发,提供了一系列的数据探索、可视化、预处理以及建模组件。
Orange 拥有漂亮直观的交互式用户界面,非常适合新手进行探索性数据分析和可视化展示;同时高级用户也可以将其作为 Python 的一个编程模块进行数据操作和组件开发。
Orange 由卢布尔雅那大学于 1996 年开发,从 3.0 版本开始使用 Python 代码库进行科学计算,例如 numpy、scipy 以及 scikit-learn;前端的图形用户界面使用跨平台的 Qt 框架。Orange 支持 Windows、macOS 以及 Linux 平台。
Orange 安装
首先,打开 Orange 官方下载页面Orange Data Mining - Download

下载页面提供了几种安装方式:
Miniconda,直接点击“Download”按钮,下载 Orange3-Miniconda-x86_64.exe 文件后双击运行。
Anaconda,如果系统已经 Anaconda 发行版,执行以下两个命令:
conda config --add channels conda-forge
conda install orange3
Python Package Index,执行以下命令:
pip install orange3安装完成后,在命令行输入以下命令可以启动 Orange 图形界面:
orange-canvas
# 或者
python -m Orange.canvas启动之后显示以下欢迎界面。

欢迎界面提供了新建、打开工作流(workflow)的快捷方式以及各种教程、示例和使用文档,关闭该界面就进入了 Orange 主界面。
示例教程
打开 Orange 主界面,左侧显示了默认安装时提供的许多机器学习、预处理以及可视化的算法,这些功能被划分为 5 个组件集(数据、可视化、模型、评估以及无监督算法)。

其中的组件包括:
- 数据(Data):包含数据输入、数据保存、数据过滤、抽样、插补、特征操作以及特征选择等组件,同时还支持嵌入 Python 脚本。
- 可视化(Visualize):包含通用可视化(箱形图、直方图、散点图)和多变量可视化(马赛克图、筛分曲线图)组件。
- 模型(Model):包含一组用于分类和回归的有监督机器学习算法组件。
- 评估(Evaluate):交叉验证、抽样程序、可靠性评估以及预测方法评估。
- 无监督算法(Unsupervised):用于聚类(k-means、层次聚类)和数据降维(多维尺度变换、主成分分析、相关分析)的无监督学习算法。
另外,还可以通过插件(add-ons)的方式为 Orange 增加其他的功能(生物信息学、数据融合与文本挖掘。添加的方法是点击“Options”菜单下的“Add-ons”按钮,打开插件管理器。

然后勾选所需的插件,点击“OK”按钮进行安装;安装插件后有可能需要重启 Orange 才能在左侧出现。
Orange 主界面的右侧是一个工作区(canvas),用于放置各种组件并构成一个数据分析的工作流。我们可以组合左侧的组件实现读取数据、显示数据表、选择特征、训练预测器、比较学习算法以及交互式可视化等功能。为了方便初学者,Orange 提供了许多实用的工作流示例。
点击“Help”菜单下的“Example Workflows”按钮,打开工作流示例界面。

我们选择“Classification Tree”,这是一个用于分类的决策树示例。

我们可以通过示例中的说明了解每个组件的作用和工作流程,其中的组件包括:
- 打开数据文件的 File 组件,用于打开包含鸢尾花(Iris)数据集的文件,这是一个经典的数据挖掘数据集;
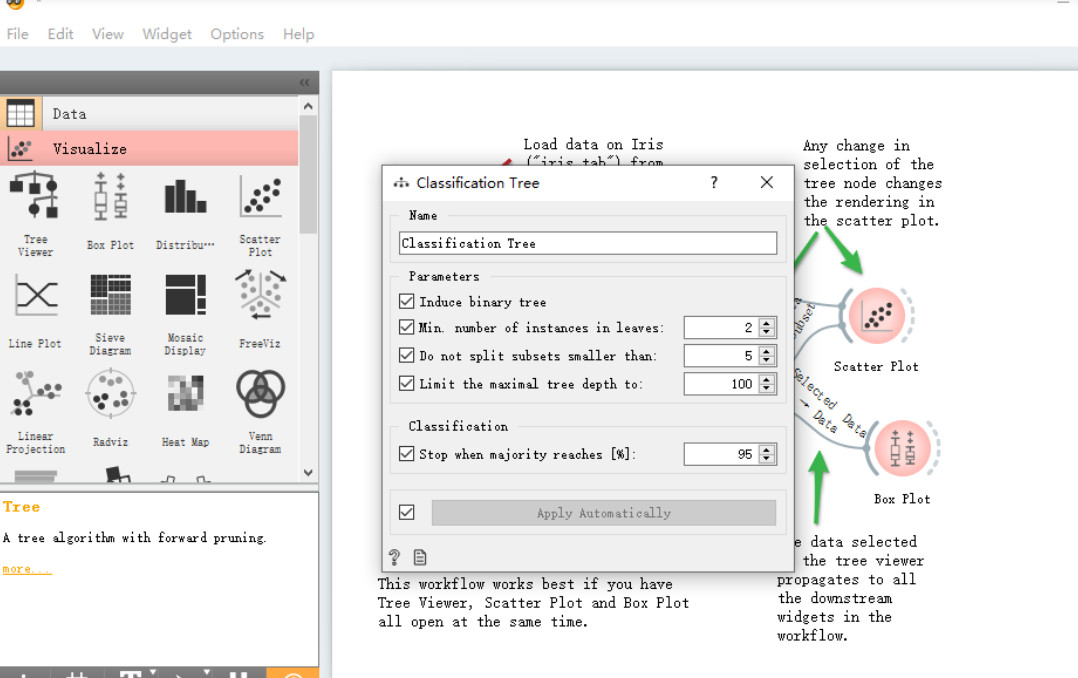
- 用于分类的决策树组件(Classification Tree),这是一个决策树算法;
- 分类树可视化组件(Tree Viewer),用于显示分类树的结果;
- 散点图组件(Scatter Plot),显示选定数据的散点图;
- 箱形图组件(Box Plot),显示选定数据的箱型图。
- 组件之间的连线代表了数据流的方向。
通过这些组件的简单组合,构建了一个交互式分类树浏览器。我们可以点击这些组件,对其进行设置和调整,例如文件组件:
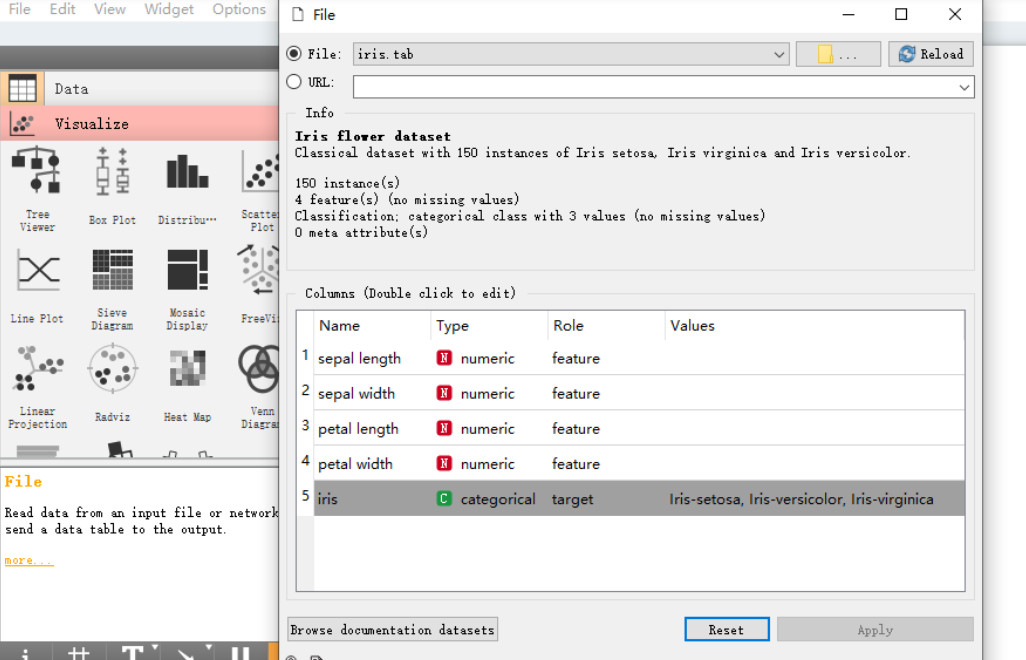
文件组件可以加载数据文件或者在线 URL 资源,并且对每个数据属性的类型、角色等进行设置。分类树组件可以对决策算法进行设置:
分类树可视化组件可以提供直观的分类结果:

散点图组件可以根据分类树可视化组件中选择的节点数据显示相应的散点图,实现同步刷新:

我们也可以从 Orange 官方网站下载更多的示例。Orange Data Mining - Workflows
对于初学者而言,只需要在 Orange 图形界面中通过拖拽加点击的方式就可以实现常见的数据分析、探索、可视化以及数据挖掘任务;对于高级用户,可以通过开发自定义的组件(Widget)实现扩展的功能,或者在 Python 中利用 Orange 代码库编写数据挖掘脚本程序。相关内容可以参考 Orange 官方文档。
参考:
Orange:一个基于 Python 的数据挖掘和机器学习平台_orange python_不剪发的Tony老师的博客-CSDN博客
入门教程:https://blog.csdn.net/weixin_39461079/category_12101011.html














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









