







使用HTMLParser时无报错情况下异常中止
今天在使用Python写一个爬虫时出现HTMLParser没有完全将整个页面解析完就中止的情况,且没有出现任何报错。问题已经解决了,特意把内容分享一下避免大家继续入坑。
错误结果:
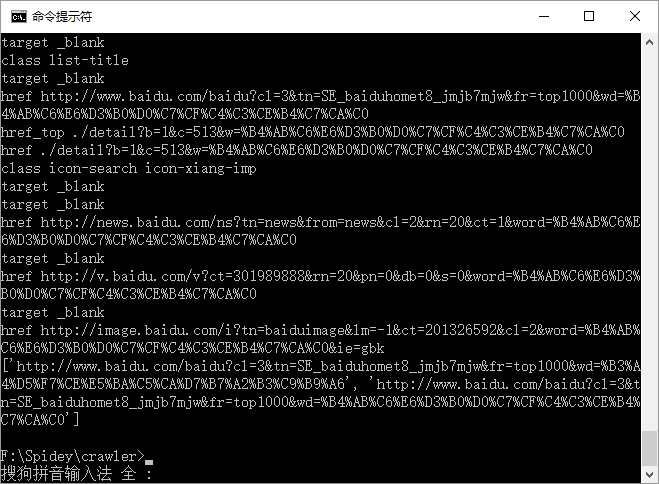
上图显示出没有任何报错,HTMLParser最后解析到一个含href的超链接后中止。之前没有遇到过此类问题,百度上也找不到相关结果。为了找到问题的起因,直接把爬取的网页提取到本地,看在什么地方中止。
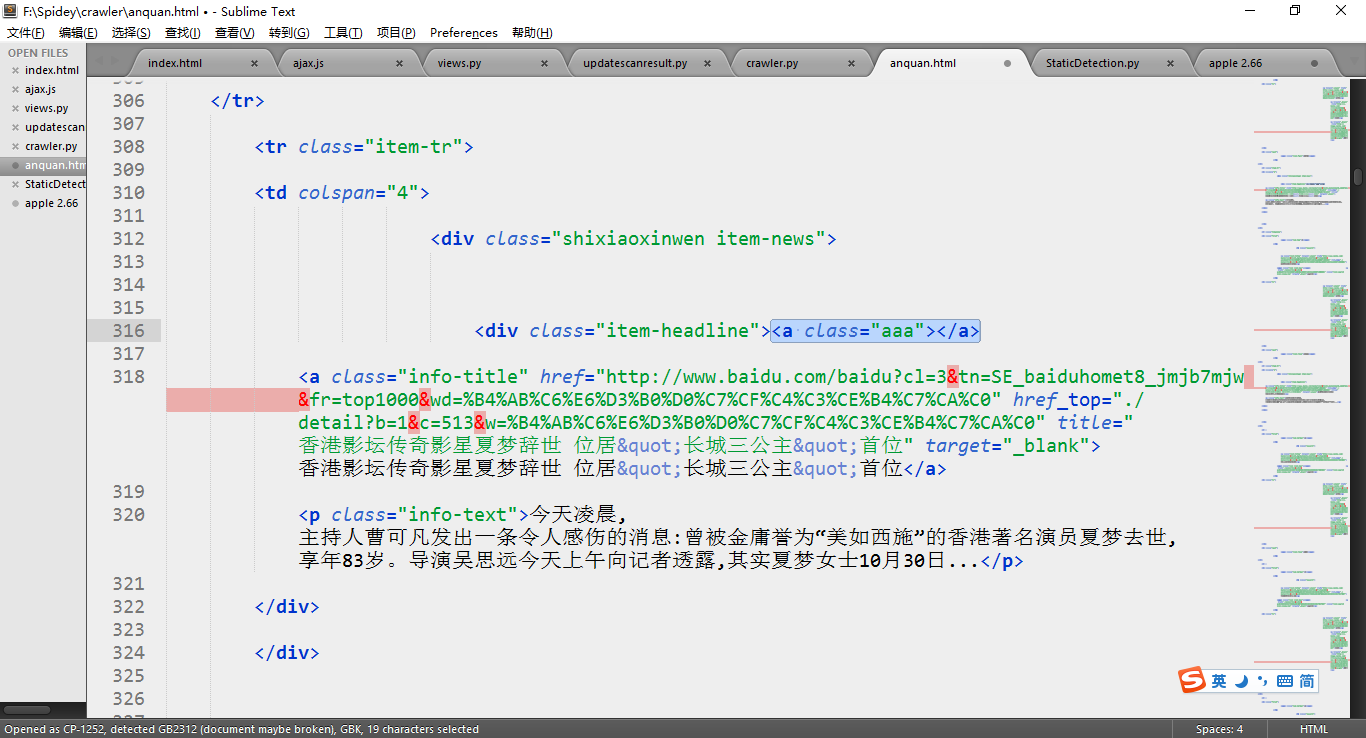
其中class为aaa的超链接是我自己把网页保存到本地后加的,目的是判断HTMLParser解析到哪里中止。
测试结果:
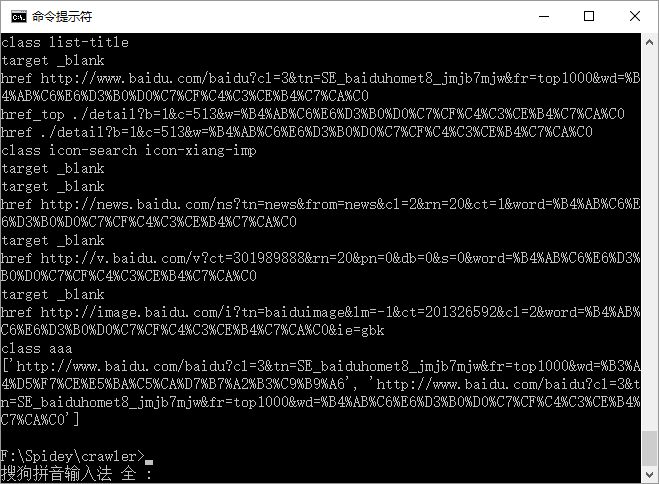
可以看出来class为aaa的超链接是可以解析到的。但是下一个超链接就没有被解析到了,解析直接结束,打印出最后我return的一个list。这个解析不出来的超链接如下:
<a class="info-title" href="http://www.baidu.com/baidu?cl=3& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6081
6081











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









