







一、需求:在豆瓣官网中,使用Scrapy实现模拟登录,并爬取登录后的个人中心界面中的用户名及日记信息数据。

二、实现思路:
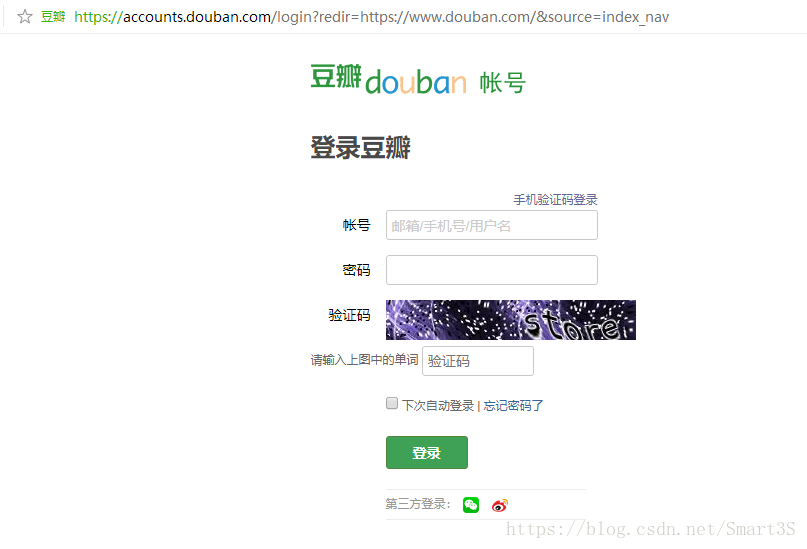
1、关于用户名与密码以及其提交网址:
观察登录网页的源代码,注意到用户名与密码都使用不同name属性的input来输入。

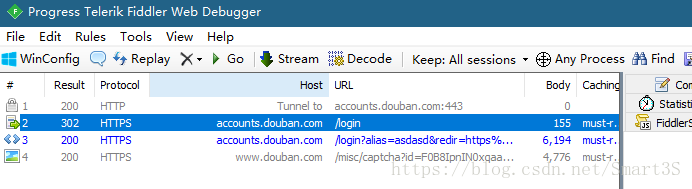
登录信息的提交网址为,这个网址可以在源代码中找到,但是非常建议使用Fiddler进行抓包分析得到,方法是首先对Fiddler进行clear,然后故意输入错误的用户名密码,点击登录,Fiddler立即回抓到登录信息的提交链接:
2、关于爬取的信息:
1)用户名称:在网页的title标签中。

2)日记内容:被class属性为note的div标签所包围。
2、关于处理豆瓣的反爬机制:
1)伪装浏览器,获取浏览器的header,可参考Python数据爬虫学习笔记(6)爬虫异常处理与浏览器伪装。
2)登录验证码,采用半自动输入的方式,在实际工作时可以使用打码api实现。
三、编写Scrapy项目代码:
1、settings.py(非常重要):
#非常重要!否则运行爬虫会报crawl(403)的错误,无法爬取信息
DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
}
ROBOTSTXT_OBEY = False2、soubanSpider.py(笔者创建的Scrapy爬虫文件):
import scrapy
from scrapy.http import Request,FormRequest
#导入用于爬取网页验证码
import urllib.request
class DoubanspiderSpider(scrapy.Spider):
name = 'doubanSpider'
allowed_domains = ['douban.com']
#浏览器的header
header={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36 OPR/54.0.2952.71"}
#start_urls = ['http://www.douban.com/']
#设置提交登录信息的网址,注意要设置cookie储存登录信息以实现连续爬取
def start_requests(self):
return [Request("https://accounts.douban.com/login", callback=self.parse, meta={"cookiejar": 1})]
#处理数据的方法
def parse(self, response):
#尝试获取网页中的验证码链接
captcha = response.xpath("//img[@id='captcha_image']/@src").extract()
#根据是否爬取到了验证码图片执行相关处理
if len(captcha) > 0:
print("此时有验证码")
#爬取验证码图片至本地,提示用户进行输入
localpath = "E:/Scrapy/result/captcha.png"
urllib.request.urlretrieve(captcha[0], filename=localpath)
print("请查看本地验证码图片并输入验证码")
captcha_value = input()
#设置需要提交至登录URL的数据,包括用户名、密码、验证码以及登录成功的回调页
data = {
"form_email": "正确的用户名",
"form_password": "正确的对应密码",
"captcha-solution": captcha_value,
"redir": "https://www.douban.com/people/164741792/",
}
else:
print("此时没有验证码")
#设置需要提交至登录URL的数据,包括用户名、密码以及登录成功的回调页
data = {
"form_email": "正确的用户名",
"form_password": "正确的对应密码",
"redir": "https://www.douban.com/people/164741792/",
}
print("登录……")
#登录成功后执行后续方法
return [FormRequest.from_response(response,
meta={"cookiejar": response.meta["cookiejar"]},
headers=self.header,
formdata=data,
callback=self.next,
)]
#登录成功后,提取用户信息
def next(self, response):
print("此时已经登陆完成并爬取了个人中心的数据")
title = response.xpath("/html/head/title/text()").extract()
note = response.xpath("//div[@class='note']/text()").extract()
print(title[0])
print(note[0])四、运行结果:
1、输入命令运行爬虫,等待出现输入验证码提示:

2、到对应目录查看验证码图片,本博文存储在E盘Scrapy的result文件夹中:

3、之后输入验证码,即可查看爬取结果:















 1194
1194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









