







安装
pip install scrapy
在命令行输入scrapy,出现提示说明安装成功

创建项目
scrapy startproject my_scrapy
会生成一个项目名文件夹,包含一些文件
其中对于开发Scrapy爬虫来说,需要关心的内容如下。
(1)spiders文件夹:存放爬虫文件的文件夹。
(2)items.py:定义需要抓取的数据。
(3)pipelines.py:负责数据抓取以后的处理工作。pipelines.py文件用于对数据做初步的处理,包括但不限于初步清洗数据、存储数据等。
(4)settings.py:爬虫的各种配置信息。

创建爬虫文件
scrapy genspider example baidu.com
example为爬虫文件名 可以随便定义
最后一个参数为要爬取的网址
会在spiders文件夹下生成一个文件example.py
example.py文件初始内容
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example'
allowed_domains = ['baidu.com']
start_urls = ['http://baidu.com/']
def parse(self, response):
pass
这里没有输出内容
把pass改为print(response.body.decode())
运行爬虫,可以看到输出结果,注意这里的操作,都是在命令行进行的,不能直接用python运行爬虫文件。
parse 表示请求 start_urls 中的地址,获取响应之后的回调函数,直接通过参数 response 的 .text 属性进行网页源码的输出。
运行爬虫
scrapy crawl example
要想在python直接运行爬虫,可以新建main文件,放置项目根目录。
from scrapy import cmdline
cmdline.execute("scrapy crawl example".split())
scrapy中使用xpath
需要使用extract()提取内容,如果不提取,XPath获得的结果是保存在一个SelectorList中
import scrapy
class ExampleSpider(scrapy.Spider):
name = 'example'
allowed_domains = ['baidu.com']
start_urls = ['http://baidu.com/']
def parse(self, response):
# print(response.body.decode())
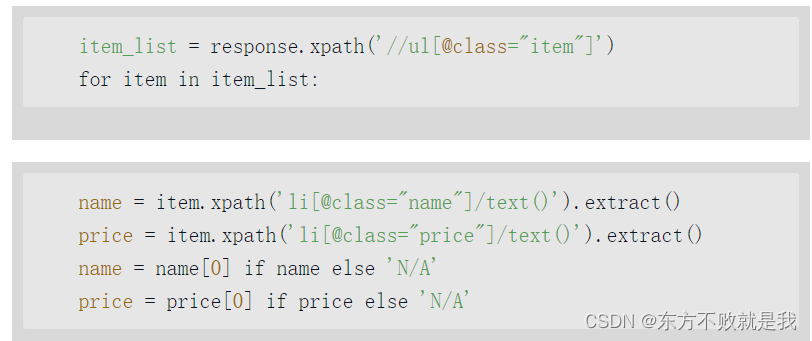
title=response.xpath('//title/text()').extract()
search_button_text=response.xpath('//input[@id="su"]/@value').extract()
print(title)
print(search_button_text)
这个SelectorList非常有意思,它本身很像一个列表。可以直接使用下标读取里面的每一个元素,也可以像列表一样使用for循环展开,然后对每一个元素使用.extract()方法。同时,又可以先执行SelectorList的.extract()方法,得到的结果是一个列表,接下来既可以用下标来获取每一个元素,也可以使用for循环展开
当不需要从抓取到的信息中提取文本的时候,就不需要调用extract()方法。
实例
使用xpath方法,打印出url和文章标题
class ExampleSpider(scrapy.Spider):
name = 'example'
allowed_domains = ['imspm.com']
start_urls = ['http://imspm.com/']
def parse(self, response):
# item=MyScrapyItem()
item_list=response.xpath("//div[@class='item-div']")
for each in item_list:
url=each.xpath("a/@href").extract()
title=each.xpath("a/h2[@class='title']/text()").extract()
print("文章地址:{0},文章标题{1}".format(url,title))
输出结果

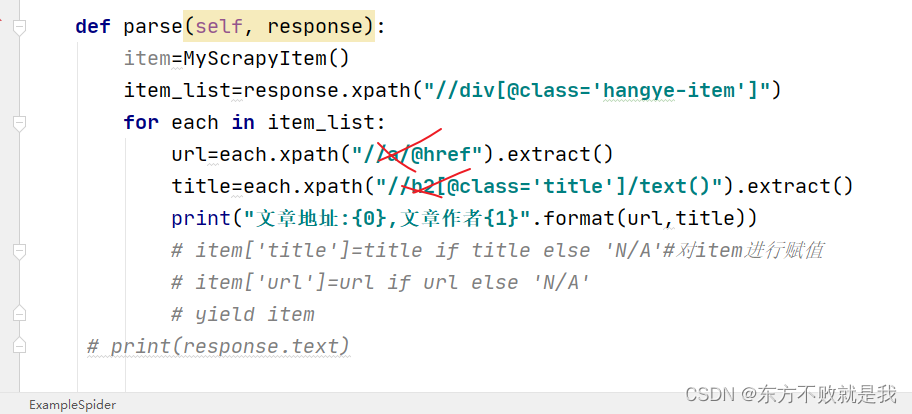
这里需要注意,采用抓大放小的方法,循环each时,元素xpath不能再用相对路径,直接写标签即可。
如下图这种写法,是错误的,会直接根据相对路径得到结果,最后就是输出了10遍想要的结果。
Item中定义抓取的数据
要想把结果保存起来,需要先定义要抓取的数据
在item.py中写入如下代码,这个类就是要存储的数据的结果。
一个Scrapy工程可以有多个爬虫;再看items.py文件,可以发现,在一个items.py里面可以对不同的爬虫定义不同的抓取内容Item。
import scrapy
class MyScrapyItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title=scrapy.Field()#文章标题
url=scrapy.Field()#文章地址
修改爬虫文件
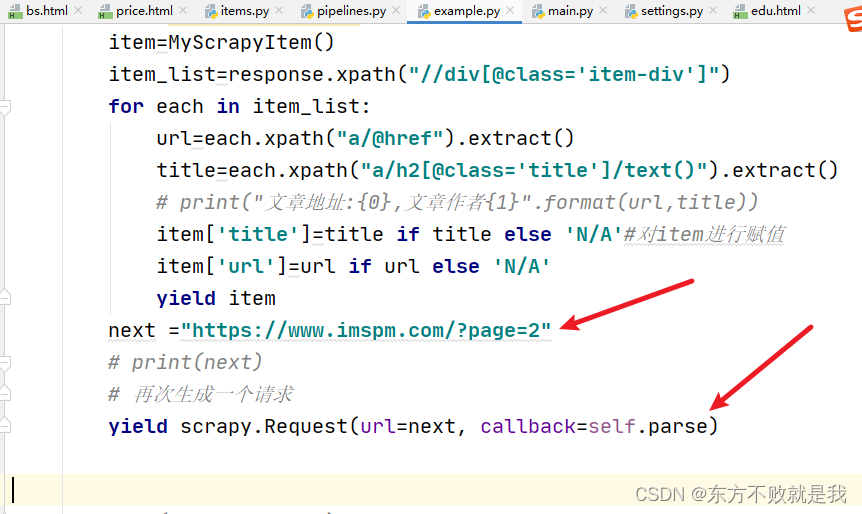
def parse(self, response):
item=MyScrapyItem()
item_list=response.xpath("//div[@class='item-div']")
for each in item_list:
url=each.xpath("a/@href").extract()
title=each.xpath("a/h2[@class='title']/text()").extract()
# print("文章地址:{0},文章作者{1}".format(url,title))
item['title']=title if title else 'N/A'#对item进行赋值
item['url']=url if url else 'N/A'
yield item
输出,可以看到,将结果保存到了字典中。

这就爬取到了第一页内容,要想继续爬取。
可以下面这种方法。
yield scrapy.Request(url=next, callback=self.parse)
如果想要保存运行结果,运行下面的命令即可。
scrapy crawl 文件名 -o json文件名,可将结果保存为json文件。
如scrapy crawl example -o example.json
生成的文件还支持 csv 、 xml、marchal、pickle
管道
在pipelines填写如下代码
class MyScrapyPipeline:
def process_item(self, item, spider): # 移除标题中的空格
if item["title"]:
item["title"] = item["title"].strip()#移出标题左右空格
return item
该代码用于移除标题中的左右空格。再次运行爬虫代码,会发现标题的左右空格已经被移除。















 954
954











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









