







作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
学习必须往深处挖,挖的越深,基础越扎实!
阶段1、深入多线程
阶段2、深入多线程设计模式
阶段3、深入juc源码解析
码哥源码部分
码哥讲源码-原理源码篇【2024年最新大厂关于线程池使用的场景题】
码哥讲源码-原理源码篇【揭秘join方法的唤醒本质上决定于jvm的底层析构函数】
码哥源码-原理源码篇【Doug Lea为什么要将成员变量赋值给局部变量后再操作?】
码哥讲源码【谁再说Spring不支持多线程事务,你给我抽他!】
打脸系列【020-3小时讲解MESI协议和volatile之间的关系,那些将x86下的验证结果当作最终结果的水货们请闭嘴】
本章,我将对网络层中的最后两个组件 RequestChannel 和 RequestHandler 进行讲解。严格来说, RequestChannel 和 RequestHandler 并不属于网络层(Network Layer),当然,它们也不属于API层(API Layer)。
我将RequestChannel和RequestHandler定位为Kafka Server端 网络层与API层之间交互的中间件 。本章,我会分析RequestChannel和RequestHandler的整体架构,以及它们对请求/响应的底层处理细节。
一、RequestChannel
首先,我们来看RequestChannel。RequestChannel会缓存Processor线程发送过来的Request请求,同时也接受API层的Response响应。它的内部有两个重要的队列:
- 一个请求缓存队列requestQueue;
- N个响应缓存队列responseQueues。
requestQueue本质是一个ArrayBlockingQueue, 所有Processor线程共享一个 ,每个Processor线程都会将请求封装成Request对象并入到这个队列里面。
responseQueue本质是一个LinkedBlockingQueue, 每个Processor线程独立拥有一个 ,API层会将响应封装成Response对象并入队。
1.1 内部结构
整体结构大致如下图:
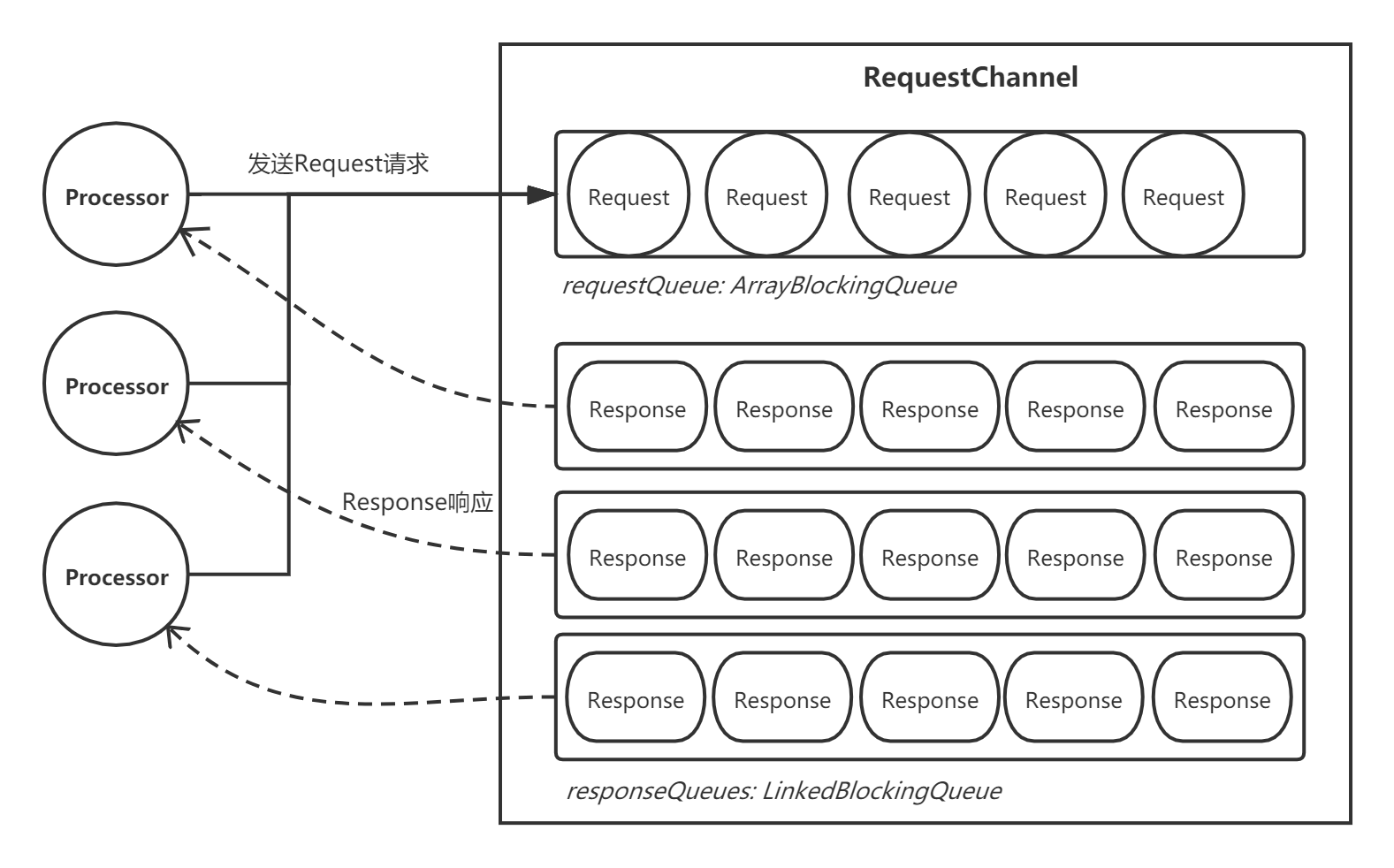
接受Processor线程发送过来的Request请求:
// RequestChannel.scala
def sendRequest(request: RequestChannel.Request) {
requestQueue.put(request)
}
获取Response对象,返回给Processor线程处理:
// RequestChannel.scala
def receiveResponse(processor: Int): RequestChannel.Response = {
val response = responseQueues(processor).poll()
if (response != null)
response.request.responseDequeueTimeMs = Time.SYSTEM.milliseconds
response
}
接受API层的响应结果,并添加到响应队列中:
// RequestChannel.scala
def sendResponse(response: RequestChannel.Response) {
responseQueues(response.processor).put(response)
for(onResponse <- responseListeners)
onResponse(response.processor)
}
二、RequestHandler
我们再来看另一个组件—— RequestHandler ,它是在Kafka Server启动时创建的,内部委托了对API层的调用:
// KafkaServer.scala
var apis: KafkaApis = null
var requestHandlerPool: KafkaRequestHandlerPool = null
def startup() {
try {
//...
if (canStartup) {
// 14.启动请求处理线程池
apis = new KafkaApis(socketServer.requestChannel, replicaManager, adminManager,
groupCoordinator,kafkaController, zkUtils, config.brokerId,
config, metadataCache, metrics, authorizer, quotaManagers,
clusterId, time)
requestHandlerPool = new KafkaRequestHandlerPool(config.brokerId,
socketServer.requestChannel,
apis, time, config.numIoThreads)
}
}
catch {
case e: Throwable =>
fatal("Fatal error during KafkaServer startup. Prepare to shutdown", e)
isStartingUp.set(false)
shutdown()
throw e
}
}
整个处理流程可以用下面这张图表述:

2.1 KafkaRequestHandlerPool
我们来看下KafkaRequestHandlerPool的内部,它封装了一堆线程,可以看成是一个线程池,这些线程启动后,就不断执行 KafkaRequestHandler 任务:
// KafkaRequestHandlerPool.scala
class KafkaRequestHandlerPool(val brokerId: Int,
val requestChannel: RequestChannel,
val apis: KafkaApis,
time: Time,
numThreads: Int) extends Logging with KafkaMetricsGroup {
// 工作线程,默认8个
val threads = new Array[Thread](numThreads)
// KafkaRequestHandler任务
val runnables = new Array[KafkaRequestHandler](numThreads)
for(i <- 0 until numThreads) {
runnables(i) = new KafkaRequestHandler(i, brokerId, aggregateIdleMeter, numThreads, requestChannel, apis, time)
threads(i) = Utils.daemonThread("kafka-request-handler-" + i, runnables(i))
// 启动任务
threads(i).start()
}
}
2.2 KafkaRequestHandler
KafkaRequestHandler本质是一个Runnable任务,它会不断从RequestChannel的请求队列中获取Request对象,然后交给Kafak API层进行处理:
// KafkaRequestHandler.scala
def run() {
while(true) {
try {
var req : RequestChannel.Request = null
while (req == null) {
val startSelectTime = time.nanoseconds
// 从RequestChannel的请求队列中获取Request
req = requestChannel.receiveRequest(300)
}
//...
// 将请求交给API层处理
apis.handle(req)
} catch {
case e: Throwable => error("Exception when handling request", e)
}
}
}
这里我额外展开下,我们看下Kafka API层的内部,其实就是根据Request请求的不同类型进行处理:
// KafkaApis.scala
def handle(request: RequestChannel.Request) {
try {
trace("Handling request:%s from connection %s;securityProtocol:%s,principal:%s".
format(request.requestDesc(true), request.connectionId, request.securityProtocol, request.session.principal))
// 根据Request请求的不同类型进行处理
ApiKeys.forId(request.requestId) match {
case ApiKeys.PRODUCE => handleProducerRequest(request)
case ApiKeys.FETCH => handleFetchRequest(request)
case ApiKeys.LIST_OFFSETS => handleOffsetRequest(request)
case ApiKeys.METADATA => handleTopicMetadataRequest(request)
case ApiKeys.LEADER_AND_ISR => handleLeaderAndIsrRequest(request)
case ApiKeys.STOP_REPLICA => handleStopReplicaRequest(request)
case ApiKeys.UPDATE_METADATA_KEY => handleUpdateMetadataRequest(request)
case ApiKeys.CONTROLLED_SHUTDOWN_KEY => handleControlledShutdownRequest(request)
case ApiKeys.OFFSET_COMMIT => handleOffsetCommitRequest(request)
case ApiKeys.OFFSET_FETCH => handleOffsetFetchRequest(request)
case ApiKeys.GROUP_COORDINATOR => handleGroupCoordinatorRequest(request)
case ApiKeys.JOIN_GROUP => handleJoinGroupRequest(request)
case ApiKeys.HEARTBEAT => handleHeartbeatRequest(request)
case ApiKeys.LEAVE_GROUP => handleLeaveGroupRequest(request)
case ApiKeys.SYNC_GROUP => handleSyncGroupRequest(request)
case ApiKeys.DESCRIBE_GROUPS => handleDescribeGroupRequest(request)
case ApiKeys.LIST_GROUPS => handleListGroupsRequest(request)
case ApiKeys.SASL_HANDSHAKE => handleSaslHandshakeRequest(request)
case ApiKeys.API_VERSIONS => handleApiVersionsRequest(request)
case ApiKeys.CREATE_TOPICS => handleCreateTopicsRequest(request)
case ApiKeys.DELETE_TOPICS => handleDeleteTopicsRequest(request)
case requestId => throw new KafkaException("Unknown api code " + requestId)
}
} catch {
//...
} finally
request.apiLocalCompleteTimeMs = time.milliseconds
}
我们重点看下handleProducerRequest,它对普通Producer生产者的请求进行处理,处理完成后会触发以下回调函数。可以看到, 最终处理完的响应结果会被封装程Response对象,交给RequestChannel处理:
def produceResponseCallback(delayTimeMs: Int) {
// 如果该请求不需要ACK确认
if (produceRequest.acks == 0) {
//...
}
// 如果该请求需要ACK确认
else {
val respBody = request.header.apiVersion match {
case 0 => new ProduceResponse(mergedResponseStatus.asJava)
case version@(1 | 2) => new ProduceResponse(mergedResponseStatus.asJava, delayTimeMs, version)
case version => throw new IllegalArgumentException(s"Version `$version` of ProduceRequest is not handled. Code must be updated.")
}
// 将响应入队到RequestChannel
requestChannel.sendResponse(new RequestChannel.Response(request, respBody))
}
}
三、总结
本章,我对网络层的最后两个组件RequestChannel和RequestHandler进行了讲解。它们的整体设计思路还是比较清晰简单的,本质就是利用不用的内存队列和线程池对请求/响应进行处理,提升整体吞吐量,这种思路在实际的生产应用中运用非常多,我在《分布式系统从理论到实战系列》专栏的实战篇中也讲解过这类运用,感兴趣的读者可以去看一看。















 252
252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









