







作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
学习必须往深处挖,挖的越深,基础越扎实!
阶段1、深入多线程
阶段2、深入多线程设计模式
阶段3、深入juc源码解析
码哥源码部分
码哥讲源码-原理源码篇【2024年最新大厂关于线程池使用的场景题】
码哥讲源码-原理源码篇【揭秘join方法的唤醒本质上决定于jvm的底层析构函数】
码哥源码-原理源码篇【Doug Lea为什么要将成员变量赋值给局部变量后再操作?】
码哥讲源码【谁再说Spring不支持多线程事务,你给我抽他!】
打脸系列【020-3小时讲解MESI协议和volatile之间的关系,那些将x86下的验证结果当作最终结果的水货们请闭嘴】
从本章开始,我将分析Kafka中的消费者(Consumer)的源码。我在之前的章节已经对Consumer的基本原理进行了分析,我们先来回顾一下,然后我再从源码层面对GroupCoordinator这个消费者组协调器进行分析。
我之前粗略的讲解过 GroupCoordinator :每个消费者组都会选择一个Broker作为自己的Coordinator,这个GroupCoordinator协调器负责监控这个消费组里的各个消费者的心跳,判断它们是否宕机,如果宕机则进行Rebalance。
那么,GroupCoordinator的底层实现是怎样的?Consumer又是如何与它进行通信的?这就是本章我们要了解的内容。
一、消费者组
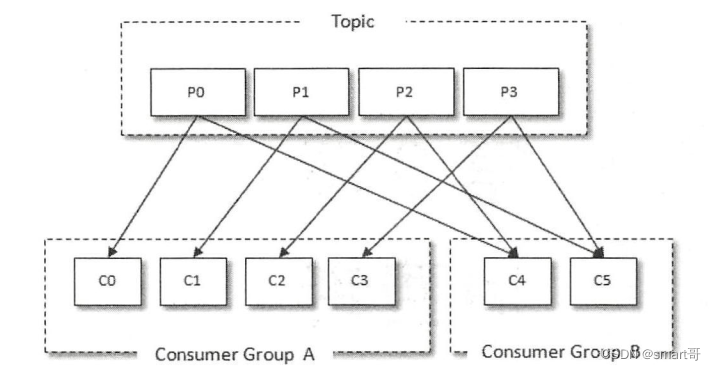
首先回顾下消费者组和消费者的基本使用。每个Consumer都属于一个consumer.group消费者组,每个Topic分区只会分配给消费组中的一个Consumer来处理,每个Consumer可以消费0到多个分区:
我们可以像下面这样创建并使用Consumer:
JAVA public class ConsumerDemo { public static void main(String[] args) throws Exception { // 要订阅的Topic String topicName = “test - topic”; // Consumer Group String groupId = “test - group”; Properties props = new Properties(); props.put(“bootstrap.servers”, “localhost:9092”); props.put(“group.id”, “groupId”); // 自动提交offset props.put(“enable.auto.commit”, “ true”); props.put(“auto.commit.ineterval.ms”, “1000”); // 每次Consumer重启后,都是从最早的offset开始读取,不是接着上一次 props.put(“auto.offset.reset”, “earliest”); props.put(“key.deserializer”, “org.apache.kafka.common.serialization.StringDeserializer”); props.put(“value.deserializer”, “org.apache.kafka.common.serialization.SttringDeserializer”); KafkaConsumer<String, String> consumer = new KafkaConsumer<String, String>(props); consumer.subscribe(Arrays.asList(topicName)); try { while (true) { // 消费消息,超时时间1s ConsumerRecords<String, String> records = consumer.poll(1000); for (ConsumerRecord<String, String> record : records) { System.out.println(record.offset() + “, ” + record.key() + “, ”+record.value()); } } } catch (Exception e) { } } }
### 1.1 Consumer初始化
Consumer启动后,首先会进行初始化,我们来看下Consumer初始化的源码,重点关注它的内部初始化的 ConsumerCoordinator 组件:
JAVA // KafkaConsumer.java private KafkaConsumer(ConsumerConfig config, Deserializer<K> keyDeserializer, Deserializer<V> valueDeserializer) { try { log.debug("Starting the Kafka consumer"); //... this.coordinator = new ConsumerCoordinator(this.client, // NetworkClient config.getString(ConsumerConfig.GROUP_ID_CONFIG), config.getInt(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG), config.getInt(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG), config.getInt(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG), assignors, this.metadata, this.subscriptions, metrics, metricGrpPrefix, this.time, retryBackoffMs, config.getBoolean(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG), config.getInt(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG), this.interceptors, config.getBoolean(ConsumerConfig.EXCLUDE_INTERNAL_TOPICS_CONFIG), config.getBoolean(ConsumerConfig.LEAVE_GROUP_ON_CLOSE_CONFIG)); //... log.debug("Kafka consumer created"); } catch (Throwable t) { close(0, true); throw new KafkaException("Failed to construct kafka consumer", t); } }
上面的代码看起来并没什么特殊的,就是实例化了一个ConsumerCoordinator组件而已。我们继续看ConsumerCoordinator的实例化:
- 首先调用了父类 AbstractCoordinator 的构造器;
- 然后,就是进行了一些字段的赋值。
JAVA // ConsumerCoordinator.java public final class ConsumerCoordinator extends AbstractCoordinator { //... public ConsumerCoordinator(ConsumerNetworkClient client, String groupId, int rebalanceTimeoutMs, int sessionTimeoutMs, int heartbeatIntervalMs, List<PartitionAssignor> assignors, Metadata metadata, SubscriptionState subscriptions, Metrics metrics, String metricGrpPrefix, Time time, long retryBackoffMs, boolean autoCommitEnabled, int autoCommitIntervalMs, ConsumerInterceptors<?, ?> interceptors, boolean excludeInternalTopics, final boolean leaveGroupOnClose) { super(client, groupId, rebalanceTimeoutMs, sessionTimeoutMs, heartbeatIntervalMs, metrics, metricGrpPrefix, time, retryBackoffMs, leaveGroupOnClose); this.metadata = metadata; this.metadataSnapshot = new MetadataSnapshot(subscriptions, metadata.fetch()); this.subscriptions = subscriptions; this.defaultOffsetCommitCallback = new DefaultOffsetCommitCallback(); this.autoCommitEnabled = autoCommitEnabled; this.autoCommitIntervalMs = autoCommitIntervalMs; this.assignors = assignors; this.completedOffsetCommits = new ConcurrentLinkedQueue<>(); this.sensors = new ConsumerCoordinatorMetrics(metrics, metricGrpPrefix); this.interceptors = interceptors; this.excludeInternalTopics = excludeInternalTopics; this.pendingAsyncCommits = new AtomicInteger(); if (autoCommitEnabled) // 开启了自动提交offset this.nextAutoCommitDeadline = time.milliseconds() + autoCommitIntervalMs; this.metadata.requestUpdate(); addMetadataListener(); } } // AbstractCoordinator.java public abstract class AbstractCoordinator implements Closeable { private enum MemberState { UNJOINED, // 当前Consumer还没有加入Group REBALANCING, // 当前Consumer正在reblance STABLE, // 当前Consumer已加入Group,且发送心跳正常 } public AbstractCoordinator(ConsumerNetworkClient client, String groupId, int rebalanceTimeoutMs, int sessionTimeoutMs, int heartbeatIntervalMs, Metrics metrics, String metricGrpPrefix, Time time, long retryBackoffMs, boolean leaveGroupOnClose) { this.client = client; this.time = time; this.groupId = groupId; this.rebalanceTimeoutMs = rebalanceTimeoutMs; this.sessionTimeoutMs = sessionTimeoutMs; this.leaveGroupOnClose = leaveGroupOnClose; this.heartbeat = new Heartbeat(sessionTimeoutMs, heartbeatIntervalMs, rebalanceTimeoutMs, retryBackoffMs); this.sensors = new GroupCoordinatorMetrics(metrics, metricGrpPrefix); this.retryBackoffMs = retryBackoffMs; } }
但是,上面的构造代码中,我们并没有发现Consumer是如何与GroupCoordinator通信的。那么,Consumer怎么知道选择哪一个Broker作为GroupCoordinator?GroupCoordinator又是如何对消费者组进Reblance的呢?
## 二、GroupCoordinator
事实上,Consumer创建完成后,会在调用poll方法时完成GroupCoordinator的寻找,包括申请加入消费者组、执行消费分区策略等。我们来看下Consumer与GroupCoordinator交互的整个流程。
### 2.1 寻找GroupCoordinator(FIND_COORDINATOR)
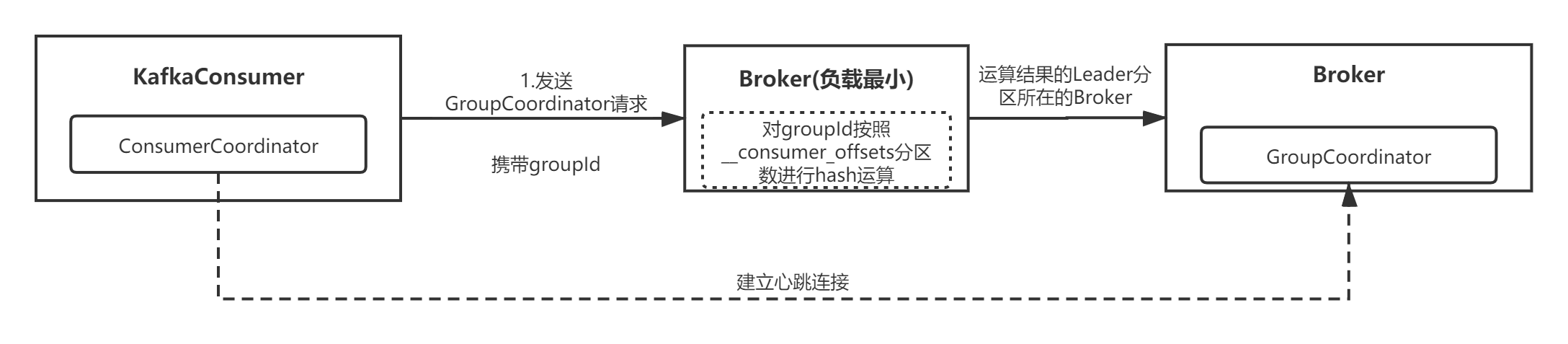
首先,Consumer启动后需要确定它所在的消费组对应的GroupCoordinator所在的Broker,并创建与该Broker相互通信的网络连接,后续通过Consumer内部的一个名为 ConsumerCoordinator 的组件与GroupCoordinator进行交互。整个流程我用下面这张图来表示:
Consumer的poll方法中,会不断循环获取一批批待消费的消息,每次循环的开头都会先调用ConsumerCoordinator.poll()方法处理各种协调事件,也包括含offset的自动提交:
// KafkaConsumer.java
public ConsumerRecords<K, V> poll(long timeout) {
acquire();
try {
//...
do {
Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollOnce(remaining);
//...
} while (remaining > 0);
return ConsumerRecords.empty();
} finally {
release();
}
}
private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollOnce(long timeout) {
// 调用ConsumerCoordinator处理各种协调事件,也包括含offset的自动提交
coordinator.poll(time.milliseconds());
// ...
return fetcher.fetchedRecords();
}
我们看下ConsumerCoordinator的poll方法,关键是第一个条件判断:如果当前Consumer还不知道GroupCoordinator在哪个Broker上,就会通过ensureCoordinatorReady方法先建立与GroupCoordinator的连接:
// ConsumerCoordinator.java
public void poll(long now) {
// offset提交
invokeCompletedOffsetCommitCallbacks();
// 1.确保已与GroupCoordinator建立连接
// 如果是自动分配分区且GroupCoordinator还未知
if (subscriptions.partitionsAutoAssigned() && coordinatorUnknown()) {
// 关键在这里:寻找GroupCoordinator并建立连接
ensureCoordinatorReady();
now = time.milliseconds();
}
if (needRejoin()) {
if (subscriptions.hasPatternSubscription())
client.ensureFreshMetadata();
ensureActiveGroup();
now = time.milliseconds();
}
pollHeartbeat(now);
maybeAutoCommitOffsetsAsync(now);
}
AbstractCoordinator的ensureCoordinatorReady方法,会不断循环直到完成GroupCoordinator的寻找:
// AbstractCoordinator.java
protected synchronized boolean ensureCoordinatorReady(long startTimeMs, long timeoutMs) {
long remainingMs = timeoutMs;
// 循环直到确认GroupCoordinator所在的Broker
while (coordinatorUnknown()) {
// 关键是这里:寻找GroupCoordinator
RequestFuture<Void> future = lookupCoordinator();
client.poll(future, remainingMs);
//...
remainingMs = timeoutMs - (time.milliseconds() - startTimeMs);
if (remainingMs <= 0)
break;
}
return !coordinatorUnknown();
}
Consumer会选择一个负载最小的Broker节点发送FindCoordinatorRequest请求,因为每个Broker都知道集群中的其它Broker信息,所以负载最小的Broker节点会负责GroupCoordinator的寻找,然后将结果返回Consumer:
// AbstractCoordinator.java
protected synchronized RequestFuture<Void> lookupCoordinator() {
if (findCoordinatorFuture == null) {
// 1. 选择一个负载最小的Broker节点,发送请求查找GroupCoordinator
Node node = this.client.leastLoadedNode();
if (node == null) {
log.debug("No broker available to send GroupCoordinator request for group {}", groupId);
return RequestFuture.noBrokersAvailable();
} else
// 2.发送请求
findCoordinatorFuture = sendGroupCoordinatorRequest(node);
}
return findCoordinatorFuture;
}
private RequestFuture<Void> sendGroupCoordinatorRequest(Node node) {
GroupCoordinatorRequest.Builder requestBuilder = new GroupCoordinatorRequest.Builder(this.groupId);
return client.send(node, requestBuilder).compose(new GroupCoordinatorResponseHandler());
}
GroupCoordinatorResponseHandler负责响应结果的处理:
// AbstractCoordinator.java
private class GroupCoordinatorResponseHandler extends RequestFutureAdapter<ClientResponse, Void> {
@Override
public void onSuccess(ClientResponse resp, RequestFuture<Void> future) {
log.debug("Received GroupCoordinator response {} for group {}", resp, groupId);
GroupCoordinatorResponse groupCoordinatorResponse = (GroupCoordinatorResponse) resp.responseBody();
Errors error = Errors.forCode(groupCoordinatorResponse.errorCode());
clearFindCoordinatorFuture();
if (error == Errors.NONE) {
synchronized (AbstractCoordinator.this) {
// 1.缓存该GroupCoordinator
AbstractCoordinator.this.coordinator = new Node(
Integer.MAX_VALUE - groupCoordinatorResponse.node().id(),
groupCoordinatorResponse.node().host(),
groupCoordinatorResponse.node().port());
log.info("Discovered coordinator {} for group {}.", coordinator, groupId);
// 2.建立与该GroupCoordinator的连接
client.tryConnect(coordinator);
// 3.发送心跳
heartbeat.resetTimeouts(time.milliseconds());
}
future.complete(null);
} else if (error == Errors.GROUP_AUTHORIZATION_FAILED) {
future.raise(new GroupAuthorizationException(groupId));
} else {
log.debug("Group coordinator lookup for group {} failed: {}", groupId, error.message());
future.raise(error);
}
}
//...
}
Consumer寻找GroupCoordinator的流程就是上面这些,我这里总结一下:
- 首先,Consumer每次poll消息时,会依靠内部的ConsumerCoordinator组件,判断是否已确认了GroupCoordinator;
- 如果还不知道GroupCoordinator,就会向Kafka集群中负载最小的那个Broker节点发送 GroupCoordinator 请求;
- 接着,负载最小的那个Broker节点接受到请求后,负责寻找GroupCoordinator节点,然后将节点信息返回给Consumer;
- 最后,Consumer收到响应后,根据Broker节点的信息与GroupCoordinator建立连接并发送心跳。
但是,这里还有一个问题:负载最小的那个Broker节点是怎么查找GroupCoordinator的?
事实上,定位的流程非常简单,就是: 对消费者组的groupId进行hash运算,将hash值与集群的某个内部Topic的分区数进行取模,找到一个Leader分区的Broker,该Broker中的GroupCoordinator就是当前消费者组的GroupCoordinator节点 :
// KafkaApis.scala
def handle(request: RequestChannel.Request) {
try {
ApiKeys.forId(request.requestId) match {
case ApiKeys.GROUP_COORDINATOR => handleGroupCoordinatorRequest(request)
//...
}
} catch {
//...
} finally
request.apiLocalCompleteTimeMs = time.milliseconds
}
def handleGroupCoordinatorRequest(request: RequestChannel.Request) {
val groupCoordinatorRequest = request.body.asInstanceOf[GroupCoordinatorRequest]
if (!authorize(request.session, Describe, new Resource(Group, groupCoordinatorRequest.groupId))) {
//...
} else {
// 关键在这里,根据groupId定位GroupCoordinator
val partition = coordinator.partitionFor(groupCoordinatorRequest.groupId)
//...
}
}
我们来看下具体的hash算法,就是取groupId的hash值,然后与groupMetadataTopicPartitionCount进行模运算,而groupMetadataTopicPartitionCount就是__consumer_offsets这个内部分区的分区数:
def partitionFor(groupId: String): Int = Utils.abs(groupId.hashCode) % groupMetadataTopicPartitionCount
定位到某个Leader分区后,该Leader分区所在的Broker节点就作为当前Consumer群组的GroupCoordinator。
通过消费者组的groupId,最终定位到的这个Broker,既扮演 GroupCoordinator 的角色,又负责保存组内Consumer的位移。
2.2 加入消费组(JOIN_GROUP)
在成功找到消费组所对应的 GroupCoordinator 之后,Consumer就进入加入消费组的阶段,在此阶段的消费者会向 GroupCoordinator 发送 JoinGroupRequest 请求,并处理响应:
// AbstractCoordinator.java
private synchronized RequestFuture<ByteBuffer> initiateJoinGroup() {
if (joinFuture == null) {
disableHeartbeatThread();
// 改变Consumer状态
state = MemberState.REBALANCING;
// 发送JoinGroupRequest请求,加入消费组
joinFuture = sendJoinGroupRequest();
joinFuture.addListener(new RequestFutureListener<ByteBuffer>() {
@Override
public void onSuccess(ByteBuffer value) {
synchronized (AbstractCoordinator.this) {
// 加入成功,修改状态为STABLE
state = MemberState.STABLE;
if (heartbeatThread != null)
heartbeatThread.enable();
}
}
@Override
public void onFailure(RuntimeException e) {
// 加入失败,修改状态为UNJOINED
synchronized (AbstractCoordinator.this) {
state = MemberState.UNJOINED;
}
}
});
}
return joinFuture;
}
private RequestFuture<ByteBuffer> sendJoinGroupRequest() {
if (coordinatorUnknown())
return RequestFuture.coordinatorNotAvailable();
log.info("(Re-)joining group {}", groupId);
JoinGroupRequest.Builder requestBuilder = new JoinGroupRequest.Builder(
groupId,
this.sessionTimeoutMs,
this.generation.memberId,
protocolType(),
metadata()).setRebalanceTimeout(this.rebalanceTimeoutMs);
log.debug("Sending JoinGroup ({}) to coordinator {}", requestBuilder, this.coordinator);
return client.send(coordinator, requestBuilder).compose(new JoinGroupResponseHandler());
}
我们来看下Broker端是如何处理JoinGroupRequest请求的:
// KafkaApis.scala
def handle(request: RequestChannel.Request) {
try {
ApiKeys.forId(request.requestId) match {
// ...
case ApiKeys.JOIN_GROUP => handleJoinGroupRequest(request)
case requestId => throw new KafkaException("Unknown api code " + requestId)
}
} catch {
// ...
} finally
request.apiLocalCompleteTimeMs = time.milliseconds
}
由KafkaApis.handleJoinGroupRequest()方法进行处理:
def handleJoinGroupRequest(request: RequestChannel.Request) {
val joinGroupRequest = request.body.asInstanceOf[JoinGroupRequest]
// 响应回调函数
def sendResponseCallback(joinResult: JoinGroupResult) {
val members = joinResult.members map { case (memberId, metadataArray) => (memberId, ByteBuffer.wrap(metadataArray)) }
val responseBody = new JoinGroupResponse(request.header.apiVersion, joinResult.errorCode, joinResult.generationId, joinResult.subProtocol, joinResult.memberId, joinResult.leaderId, members.asJava)
requestChannel.sendResponse(new RequestChannel.Response(request, responseBody))
}
if (!authorize(request.session, Read, new Resource(Group, joinGroupRequest.groupId()))) {
//...
} else {
// 处理请求
val protocols = joinGroupRequest.groupProtocols().asScala.map(protocol =>
(protocol.name, Utils.toArray(protocol.metadata))).toList
coordinator.handleJoinGroup(
joinGroupRequest.groupId,
joinGroupRequest.memberId,
request.header.clientId,
request.session.clientAddress.toString,
joinGroupRequest.rebalanceTimeout,
joinGroupRequest.sessionTimeout,
joinGroupRequest.protocolType,
protocols,
sendResponseCallback)
}
}
上述代码最终调用了GroupCoordinator进行处理:
// GroupCoordinator.scala
def handleJoinGroup(groupId: String, memberId: String, clientId: String, clientHost: String,
rebalanceTimeoutMs: Int, sessionTimeoutMs: Int, protocolType: String,
protocols: List[(String, Array[Byte])], responseCallback: JoinCallback) {
if (!isActive.get) {
//...
} else {
groupManager.getGroup(groupId) match {
case None =>
if (memberId != JoinGroupRequest.UNKNOWN_MEMBER_ID) {
responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID.code))
} else {
val group = groupManager.addGroup(new GroupMetadata(groupId))
doJoinGroup(group, memberId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols, responseCallback)
}
case Some(group) =>
// 关键看这里,执行加入Consumer Group
doJoinGroup(group, memberId, clientId, clientHost, rebalanceTimeoutMs, sessionTimeoutMs, protocolType, protocols, responseCallback)
}
}
}
我们来看核心的doJoinGroup方法,我来解析下下面的流程,GroupCoordinator内部通过一个状态机保存Consumer Group的状态:
- 初始时,Consumer Group的状态是Empty;
- 接着,如果部分Consumer发送了JoinGroup请求,Consumer Group的状态会进入PreparingRebalance,并等待其它成员加入,等待时间通过
max.poll.interval.ms参数控制; - 如果所有Consumer成员都加入了组,Consumer Group的状态就会变成AwaitingSync,此时不再允许任何一个Consumer提交offset,因为马上要进行Rebalance了;
- 接着,GroupCoordinator会选择一个Leader Consumer,由它负责上报消费者分区方案;
- Leader Consumer制定好分区方案后,通过SyncGroup请求发送给GroupCoordinator;
- 最后,GroupCoordinator将分区方案下发给所有的Consumer成员,并进入Stable状态,这样各个Consumer就可以基于poll来正常消费了。
如果GroupCoordinator在Stable状态下,有Consumer进入组或者离开/崩溃了,那么都会重新进入PreparingRebalance状态,然后触发Reblance。
// GroupCoordinator.scala
private def doJoinGroup(group: GroupMetadata, memberId: String, clientId: String, clientHost: String,
rebalanceTimeoutMs: Int, sessionTimeoutMs: Int, protocolType: String,
protocols: List[(String, Array[Byte])], responseCallback: JoinCallback) {
group synchronized {
if (!group.is(Empty) && (group.protocolType != Some(protocolType) || !group.supportsProtocols(protocols.map(_._1).toSet))) {
//...
} else {
group.currentState match {
// DEAD状态
case Dead =>
responseCallback(joinError(memberId, Errors.UNKNOWN_MEMBER_ID.code))
// PreparingRebalance状态
case PreparingRebalance =>
if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) {
addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback)
} else {
val member = group.get(memberId)
updateMemberAndRebalance(group, member, protocols, responseCallback)
}
// AwaitingSync状态
case AwaitingSync =>
if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) {
addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback)
} else {
val member = group.get(memberId)
if (member.matches(protocols)) {
responseCallback(JoinGroupResult(
members = if (memberId == group.leaderId) {
group.currentMemberMetadata
} else {
Map.empty
},
memberId = memberId,
generationId = group.generationId,
subProtocol = group.protocol,
leaderId = group.leaderId,
errorCode = Errors.NONE.code))
} else {
updateMemberAndRebalance(group, member, protocols, responseCallback)
}
}
// Empty状态或Stable状态
case Empty | Stable状态 =>
if (memberId == JoinGroupRequest.UNKNOWN_MEMBER_ID) {
// if the member id is unknown, register the member to the group
addMemberAndRebalance(rebalanceTimeoutMs, sessionTimeoutMs, clientId, clientHost, protocolType, protocols, group, responseCallback)
} else {
val member = group.get(memberId)
if (memberId == group.leaderId || !member.matches(protocols)) {
updateMemberAndRebalance(group, member, protocols, responseCallback)
} else {
responseCallback(JoinGroupResult(
members = Map.empty,
memberId = memberId,
generationId = group.generationId,
subProtocol = group.protocol,
leaderId = group.leaderId,
errorCode = Errors.NONE.code))
}
}
}
if (group.is(PreparingRebalance))
joinPurgatory.checkAndComplete(GroupKey(group.groupId))
}
}
}
2.3 Leader Consumer选举(JOIN_GROUP)
接着,我们再来看下Leader Consumer的选举。GroupCoordinator 需要为消费组内的Consumer们选举出一个Leader ,这个选举的算法很简单,分两种情况:
- 如果消费组内还没有Leader,那么 第一个加入消费组 的消费者即为Leader;
- 如果某一时刻,Leader消费者由于某些原因退出了消费组,那么会 随机选举 一个新的Leader。
2.4 确定分区分配策略(JOIN_GROUP)
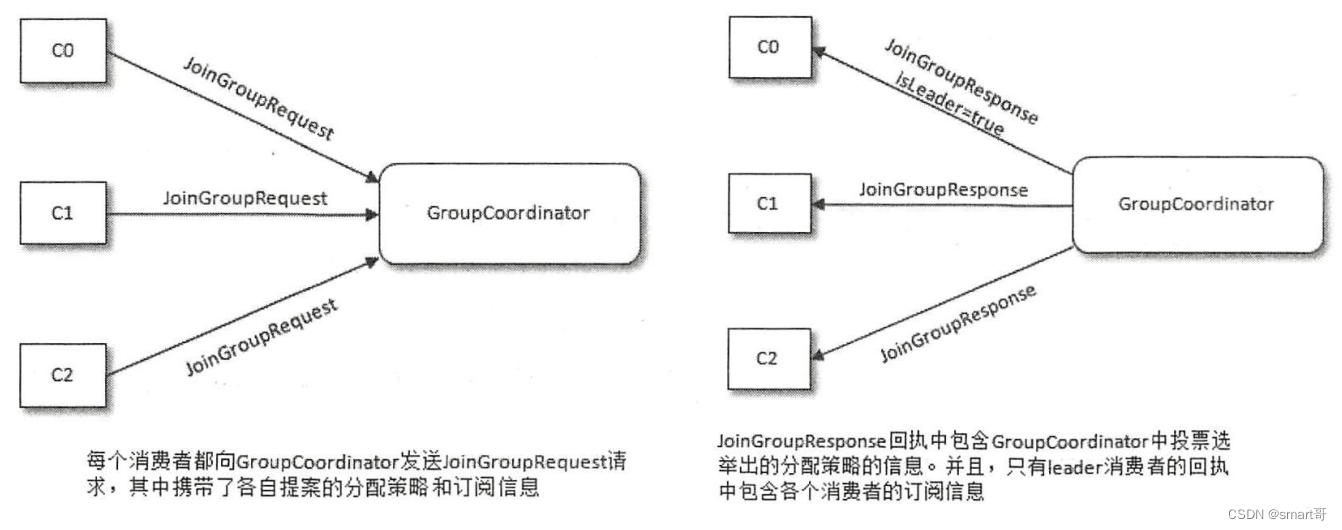
我们知道,Kafka一共提供了三种不同的消费组分区分配策略: Range 、 Round-Robin 、 Sticky 。 也就是说,每一个Consumer的策略可能是不同的,但对于一个消费组而言,是需要统一一种策略的。这个工作其实是在JOIN_GROUP阶段,由GroupCoordinator根据各个Consumer的JoinGroupRequest请求中的信息确认的,整个流程如下:
- GroupCoordinator收集各个Consumer支持的所有分配策略,组成候选集 candidates;
- 每个Consumer从候选集合中找出自身支持的第一个策略,为这个策略投上一票;
- GroupCoordinator计算各个策略的得票数,得票数最多的策略即为当前消费组的分区分配策略,然后响应给Leader Consumer。
Consumer所支持的分区分配策略可通过参数
partition.assignment.strategy配置。比如,如果这个参数值只配置了RangeAssignor,那么这个Consumer就只支持 RangeAssignor 分配策略。
2.5 实施分区分配方案
Leader Consumer收到响应后,负责制定具体的分区分配方案,然后将方案发送给GroupCoordinator。同时,各个Consumer会向GroupCoordinator发送SyncGroupRequest请求来同步分配方案。
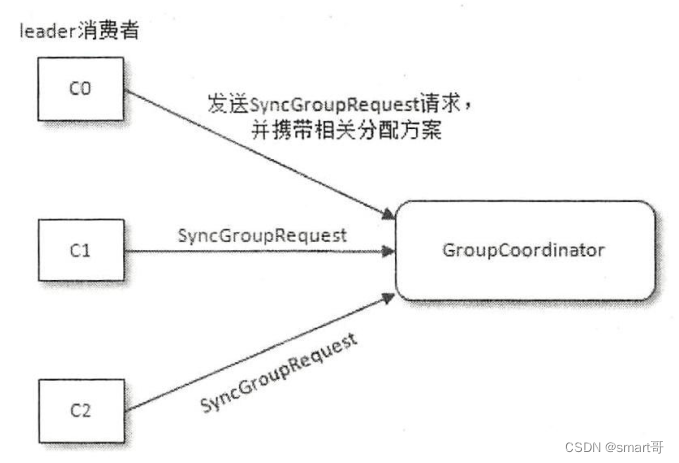
GroupCoordinator 会将从 Leader Consumer 发送过来的分配方案提取出来,连同整个消费组的元数据信息一起存入Kafka的内部主题__consumer_offsets 中,最后发送响应给各个Consumer,提供它们各自所属的分配方案。
最后,当Consumer收到所属的分配方案后,就会调用PartitionAssignor.onAssignment()方法,然后调用 ConsumerRebalanceListener.onPartitionAssigned()方法 ,最后开启心跳任务,定期向Broker的 GroupCoordinator 发送 HeartbeatRequest请求来确定彼此在线。
三、总结
本章,我对GroupCoordinator协调器的底层原理进行了讲解。Kafka Consumer的核心无非就是三块:分区分配、offset管理、底层通信。分区分配的核心就是GroupCoordinator,底层通信的原理和Producer类似,offset管理主要涉及HW、LEO。
至此,整个Kafka源码分析系列我就讲完了,剩余的很多边边角角的内容和细节读者可以自己去研读源码。















 1492
1492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









