







作者简介:大家好,我是smart哥,前中兴通讯、美团架构师,现某互联网公司CTO
联系qq:184480602,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬
学习必须往深处挖,挖的越深,基础越扎实!
阶段1、深入多线程
阶段2、深入多线程设计模式
阶段3、深入juc源码解析
码哥源码部分
码哥讲源码-原理源码篇【2024年最新大厂关于线程池使用的场景题】
码哥讲源码-原理源码篇【揭秘join方法的唤醒本质上决定于jvm的底层析构函数】
码哥源码-原理源码篇【Doug Lea为什么要将成员变量赋值给局部变量后再操作?】
码哥讲源码【谁再说Spring不支持多线程事务,你给我抽他!】
打脸系列【020-3小时讲解MESI协议和volatile之间的关系,那些将x86下的验证结果当作最终结果的水货们请闭嘴】
什么是 Stream API
Stream API 是 Java 8 引入的一个用于对集合数据进行函数式编程操作的强大的库。它允许我们以一种更简洁、易读、高效的方式来处理集合数据,可以极大提高 Java 程序员的生产力,是目前为止对 Java 类库最好的补充。
Stream API 的核心思想是将数据处理操作以函数式的方式链式连接,以便于执行各种操作,如过滤、映射、排序、归约等,而无需显式编写传统的循环代码。
下面是 Stream API 的一些重要概念和操作:
Stream****(流):Stream是 Java 8 中处理集合的关键抽象概念,它是数据渠道,用于操作数据源所生成的元素序列。这些数据源可以来自集合(Collection)、数组、I/O操作等等。它具有如下几个特点:Stream不会存储数据。Stream不会改变源数据对象,它返回一个持有结果的新的Stream。Stream操作是延迟执行的,这就意味着他们要等到需要结果的时候才会去执行。
- 中间操作:这些操作允许您在
Stream上执行一系列的数据处理。常见的中间操作有filter(过滤)、map(映射)、distinct(去重)、sorted(排序)、limit(截断)、skip(跳过)等。这些操作返回的仍然是一个 Stream。 - 终端操作:终端操作是对流进行最终处理的操作。当调用终端操作时,流将被消费,不能再进行进一步的中间操作。常见的终端操作包括
forEach(遍历元素)、collect(将元素收集到集合中)、reduce(归约操作,如求和、求最大值)、count(计数)等。 - 惰性求值:Stream 操作是惰性的,只有在调用终端操作时才会执行中间操作。这可以提高性能,因为只处理需要的数据。
为什么要用 Stream API
作为一个 CRUD Boy ,在实际开发中,我们的数据来源大多数都是基于数据库、文件等等,一般情况下这些数据都需要我们用 Java 程序来处理。这时有小伙伴就说,我用 for 循环就能很好的处理集合数据了,为什么偏要用 Stream API 呢?其实相比传统集合处理方式,Stream API 有很多优点:
- 简洁和可读性:Stream API 的链式操作使代码更加简洁、可读。
- 不可变性:Stream 操作不会修改原始数据,而是创建一个新的 Stream,确保了原始数据的不可变性,有助于并发编程。
- 惰性求值:Stream 操作是惰性的,只有在调用终端操作时才会触发中间操作的执行,提高了性能,因为只处理需要的数据。
- 并行处理:Stream API 支持并行处理数据,可以充分利用多核处理器,提高性能。
- 更高的效率:使用 Stream API 可以更快速地编写代码,因为它减少了样板代码的编写,同时提供了丰富的操作。
Stream 与集合的差异是:Stream 讲的是计算,而集合讲的是数据。
Stream 操作三部曲
一个完整的 Stream 操作包括三步
创建 Stream
首先我们需要一个 Stream 对象,常见的创建方式有:
- 使用集合的
stream()方法
在集合中有两个方法可以创建 Stream 对象:
default Stream<E> stream():返回一个顺序流
default Stream<E> parallelStream():返回一个并行流
- 通过数组
Arrays.stream(T[] array),将数组转换为 Stream 对象:
String[] array = {"死磕 Java","死磕 Java 并发","死磕 Java 新特性","死磕 Netty"};
Stream<String> stream = Arrays.stream(array);
- 使用
Stream.of(T... values)方法
Stream<String> stream = Stream.of("死磕 Java","死磕 Java 并发","死磕 Java 新特性","死磕 Netty");
这种方式适用于直接提供一组元素来创建Stream。
- 使用
Stream.builder()方法
Stream 提供了一个 builder() 方法来提供构建 Stream 的构造器:
Stream.Builder<String> builder = Stream.builder();
builder.accept("死磕 Java");
builder.accept("死磕 Java 并发");
builder.accept("死磕 Java 新特性");
builder.accept("死磕 Netty");
Stream<String> stream = builder.build();
这种方式适用于需要逐个添加元素到Stream中的情况。
Stream.generate()orStream.iterate(T seed, UnaryOperator<T> f)
这两个方法都是用于生成无限元素的Stream,需要通过limit()方法来限制元素数量。
Stream<String> stream = Stream.generate(() -> "a").limit(3);
这两个方法使用比较少。
中间操作
有了 Stream 对象,就可以在 Stream 上应用中间操作。
中间操作是一系列的操作,对数据源的数据进行处理,例如过滤、映射、排序、去重等等。注意这些操作不会立即执行,而是构建一个操作链。下表是 Stream 中常用中间操作方法。
| 方法名 | 描述 |
|---|---|
filter(Predicate<T> predicate) | 根据给定的谓词条件过滤元素。 |
map(Function<T, R> mapper) | 将元素通过给定的函数映射为另一个类型的元素。 |
flatMap(Function<T, Stream<R>> mapper) | 将每个元素映射为一个流,然后将这些流合并为一个流。 |
distinct() | 去除流中的重复元素。 |
sorted() | 对元素进行排序,默认按自然顺序排序。 |
sorted(Comparator<T> comparator) | 使用自定义比较器对元素进行排序。 |
limit(long maxSize) | 截取流中的前 maxSize 个元素。 |
skip(long n) | 跳过流中的前N个元素。 |
终端操作
做完中间操作后,我们需要调用一个终端操作来触发实际的数据处理。终端操作会遍历 Stream 并执行中间操作并产生结果。下表是一些常见的终端操作方法:
| 方法名 | 方法描述 |
|---|---|
forEach() | 对流中的每个元素执行指定的操作。 |
forEachOrdered() | 与forEach类似,但保留了元素的顺序。 |
toArray() | 将流中的元素收集到数组中。 |
reduce(accumulator) | 通过累积操作将流中的元素归约为单个结果。 |
reduce(identity, accumulator) | 使用初始值和累积操作将流中的元素归约为单个结果。 |
reduce(identity, accumulator, combiner) | 使用初始值、累积操作和组合操作将流中的元素归约为单个结果。 |
collect() | 将流中的元素收集到集合或映射中,可以指定收集器来定制收集行为。 |
min(comparator) | 使用指定的比较器找到流中的最小元素。 |
max(comparator) | 使用指定的比较器找到流中的最大元素。 |
count() | 计算流中元素的数量。 |
anyMatch() | 检查流中是否有任何元素匹配指定的条件。 |
allMatch() | 检查流中的所有元素是否都匹配指定的条件。 |
noneMatch() | 检查流中是否没有元素匹配指定的条件。 |
findFirst() | 返回流中的第一个元素(如果存在),通常与filter操作一起使用。 |
findAny() | 返回流中的任意元素(如果存在),通常与filter操作一起使用。 |
Stream API 介绍
中间操作
筛选与切片
filter(Predicate<T> predicate):根据给定的谓词条件过滤元素。
filter() 接受一个谓词函数作为参数,该函数用于对流中的每个元素进行验证,只有满足谓词条件的元素才会被保留在新的流中,而不满足条件的元素将被过滤掉。
@Test
public void filterTest() {
Stream<String> stream = Stream.of("死磕 Java","死磕 Java 并发","死磕 Java 新特性","死磕 Netty");
stream.filter(x -> x.endsWith("Netty"))
.forEach(System.out::println);
}
// 结果......
死磕 Netty
skip(long n):跳过流中的前N个元素。
skip() 通常用于分页或忽略前几个元素的场景。若流中元素不足 N 个,则返回空流。
@Test
public void skipTest() {
Stream<String> stream = Stream.of("死磕 Java","死磕 Java 并发","死磕 Java 新特性","死磕 Netty");
stream.skip(2)
.forEach(System.out::println);
}
// 结果......
死磕 Java 新特性
死磕 Netty
limit(long maxSize):截取流中的前 maxSize个元素。
limit() 通常用于对流进行限制,以获取一定数量的元素,比如分页或筛选操作。如果 maxSize 大于流中元素的总数,那么 limit 方法将返回包含所有元素的新流,不会有任何元素被丢弃。
@Test
public void limitTest() {
Stream<String> stream = Stream.of("死磕 Java","死磕 Java 并发","死磕 Java 新特性","死磕 Netty");
stream.limit(3)
.forEach(System.out::println);
}
// 结果......
死磕 Java
死磕 Java 并发
死磕 Java 新特性
distinct():去除流中的重复元素。
distinct() 依赖于元素的 equals() 来检查是否重复,因此对于自定义对象,需要确保正确实现了 equals() 和 hashCode() 方法以实现正确的去重功能。
@Test
public void distinctTest() {
Stream<String> stream = Stream.of("死磕 Java","死磕 Java 并发","死磕 Java 新特性","死磕 Netty","死磕 Java","死磕 Java 新特性");
stream.distinct()
.forEach(System.out::println);
}
// 结果......
死磕 Java
死磕 Java 并发
死磕 Java 新特性
死磕 Netty
映射
map(Function<T, R> mapper):将元素通过给定的函数映射为另一个类型的元素。
map() 会对流中的每个元素执行一个函数操作,将每个元素映射为另一个类型的元素,然后将映射后的元素作为新的流返回,通常用于数据转换和提取元素的属性。
@Test
public void mapTest() {
Stream<String> stream = Stream.of("死磕 Java","死磕 Java 并发","死磕 Java 新特性","死磕 Netty");
stream.map(String::toUpperCase)
.forEach(System.out::println);
}
比如这个例子,将所有的元素全部转换为大写形式。
再比如,我们有一批学生列表,要获取年龄小于 6 岁所有小朋友的名字,去重:
@Test
public void mapTest() {
Stream<Student> stream = Stream.<Student>builder()
.add(new Student("梓涵",5))
.add(new Student("子涵",4))
.add(new Student("紫涵",5))
.add(new Student("子晗",6))
.add(new Student("梓晗",7))
.add(new Student("梓涵",5))
.add(new Student("紫晗",6))
.build();
stream.filter(x -> x.getAge() < 6) // 过滤年龄小于6岁
.map(Student::getName) // 拿到所有学生的名字
.distinct() // 去重
.forEach(System.out::println);
}
// 结果......
梓涵
子涵
紫涵
map() 是非常有用的,它允许我们对流中的元素执行各种转换操作,如类型转换、属性提取等等,这使得在流处理中进行数据转换变得非常方便。
flatMap(Function<T, Stream<R>> mapper):将每个元素映射为一个流,然后将这些流合并为一个流。
flatMap() 通常用于将嵌套的集合结构扁平化,或者将元素进行扁平映射以进行处理。例如:
@Test
public void flatMapTest() {
List<List<String>> list = Arrays.asList(
Arrays.asList("死磕 Java","死磕 Java 并发"),
Arrays.asList("死磕 Java 基础"),
Arrays.asList("死磕 Java NIO","死磕 Netty"),
Arrays.asList("死磕 Redis","死磕 Spring"),
Arrays.asList("死磕 Java 新特性")
);
list.stream()
.flatMap(List::stream)
.forEach(System.out::println);
}
// 结果......
死磕 Java
死磕 Java 并发
死磕 Java 基础
死磕 Java NIO
死磕 Netty
死磕 Redis
死磕 Spring
死磕 Java 新特性
在这个例子中,flatMap() 接受一个 函数 List::stream,该函数将每个嵌套的集合转换为一个流,然后 flatMap() 将所有流合并成一个单一的流。
我们再来一个稍微复杂点的:
@Data
@AllArgsConstructor
public class User {
private String name;
private List<Order> orderList;
}
@Data
@AllArgsConstructor
public class Order {
private Integer id;
private String name;
}
@Test
public void flatMapTest1() {
List<User> users = Arrays.asList(
new User("张三", Arrays.asList(new Order(1, "iPhone 13"), new Order(2, "iPhone 14"))),
new User("李四", Arrays.asList(new Order(3, "MacBook Pro"))),
new User("王五", Arrays.asList(new Order(4, "iPad"), new Order(5, "MacBook Air")))
);
users.stream()
.flatMap(u -> u.getOrderList().stream())
.map(Order::getName)
.forEach(System.out::println);
}
// 结果......
iPhone 13
iPhone 14
MacBook Pro
iPad
MacBook Air
在这个示例中,flatMap() 首先将每个 User的 OrderList转换为一个流,然后使用 map() 提取订单的名称,最终将所有订单名称打印出来。
排序
sorted():对元素进行排序,默认按自然顺序排序。
sorted() 用于对流中的元素进行自然排序,要求流中的元素必须实现 Comparable 接口。
@Test
public void sortedTest() {
Stream.of("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发")
.sorted()
.forEach(System.out::println);
}
// 结果......
死磕 Java
死磕 Java 并发
死磕 Java 新特性
死磕 Netty
再如:
@Test
public void sortedTest1() {
Stream<Student> stream = Stream.<Student>builder()
.add(new Student("梓涵",5))
.add(new Student("子涵",4))
.add(new Student("紫涵",5))
.add(new Student("子晗",6))
.add(new Student("梓晗",7))
.add(new Student("梓涵",5))
.add(new Student("紫晗",6))
.build();
// 排序
stream.sorted().forEach(System.out::println);
}
这个时候执行就会报错:
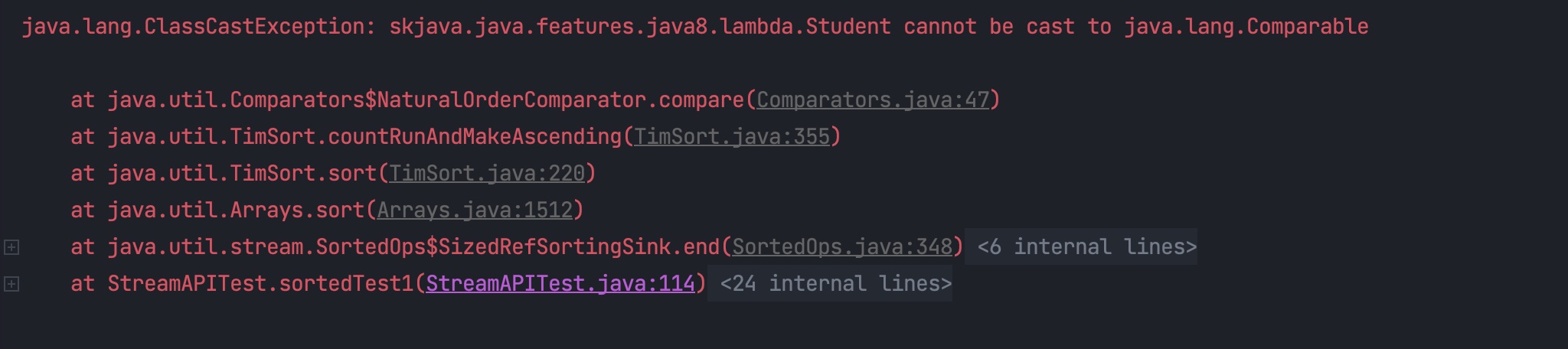
告诉你没有实现 java.lang.Comparable 接口。
sorted(Comparator<? super T> comparator):使用自定义比较器对元素进行排序。
该方法接受一个自定义的比较器Comparator,允许我们根据自定义规则对流中的元素进行排序。
@Test
public void sortedTest1() {
Stream<Student> stream = Stream.<Student>builder()
.add(new Student("梓涵",5))
.add(new Student("子涵",4))
.add(new Student("紫涵",5))
.add(new Student("子晗",6))
.add(new Student("梓晗",7))
.add(new Student("梓涵",5))
.add(new Student("紫晗",6))
.build();
// 排序
stream.sorted(Comparator.comparing(Student::getAge)).forEach(System.out::println);
}
// 结果......
Student(name=子涵, age=4)
Student(name=梓涵, age=5)
Student(name=紫涵, age=5)
Student(name=梓涵, age=5)
Student(name=子晗, age=6)
Student(name=紫晗, age=6)
Student(name=梓晗, age=7)
终端操作
匹配与查找
allMatch():检查流中的所有元素是否都匹配指定的条件。
allMatch() 会遍历流中的每一个元素,检查每一个元素是否符合条件,如果全都符合条件,则返回 true,否则返回 false。如果流为空,则返回 true 。
@Test
public void allMatchTest() {
boolean result = Stream.of("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发")
.allMatch(x -> x.startsWith("死磕"));
System.out.println(result);
}
// 结果......
true
anyMatch():检查流中是否有任何元素匹配指定的条件。
anyMatch() 遍历流中的每一个元素,检查每个元素是否符合条件,如果有一个满足条件则返回 true,否则返回 false。如果流为空,返回 false。
@Test
public void anyMatchTest() {
boolean result = Stream.of("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发")
.anyMatch(x -> x.indexOf("Spring") > 0);
System.out.println(result);
}
// 结果......
false
noneMatch():检查流中是否没有元素匹配指定的条件。
noneMatch() 检查流中每个元素是否都不满足条件,如果都不满足返回 true,否则返回 false,如果为空,则返回 true。
@Test
public void noneMatchTest() {
boolean result = Stream.of("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发")
.noneMatch(x -> x.indexOf("Spring") > 0);
System.out.println(result);
}
// 结果......
true
findFirst():返回流中的第一个元素(如果存在)
findFirst() 结果为Optional,如果流为空,findFirst() 返回的是一个包含null的Optional,否则包含第一个元素。
由于流有可能为无限流,所以 findFirst() 一般都会与其他操作一起使用,例如 filter(),找满足条件的第一个元素。
@Test
public void findFirstTest() {
Optional<String> result = Stream.of("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发")
.filter(x -> x.indexOf("Java") > 0)
.findFirst();
System.out.println(result.orElse(""));
}
findAny():返回流中的任意元素(如果存在)
findAny() 与 findFirst() 相似,不同的是 findAny 不保证返回流中的第一个元素,而是返回任意一个满足条件的元素。
@Test
public void findAnyTest() {
Optional<String> result = Stream.of("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发")
.filter(x -> x.contains("死磕"))
.findAny();
System.out.println(result.orElse(""));
}
min():找到流中的最小元素
@Test
public void minTest() {
Optional<String> result = Stream.of("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发")
.min(String::compareTo);
System.out.println(result.orElse(""));
}
max():找到流中的最大元素
@Test
public void maxTest() {
Optional<String> result = Stream.of("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发")
.max(String::compareTo);
System.out.println(result.orElse(""));
}
count():计算流中元素的数量。
count() 通常用于获取流中元素的数量,以便在需要时进行统计、计数或其他操作。
@Test
public void countTest() {
long result = Stream.of("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发")
.filter(x -> x.contains("Java"))
.count();
System.out.println(result);
}
forEach():对流中的每个元素执行指定的操作。
forEach() 主要用于遍历流中的每个元素,并对每个元素应用指定的操作。这可以用于执行各种自定义操作,例如打印元素、将元素存储到集合中等。
@Test
public void forEachTest() {
Stream.of("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发")
.forEach(x -> System.out.println(x + " 就是牛..."));
}
// 结果......
死磕 Java 新特性 就是牛...
死磕 Java 就是牛...
死磕 Netty 就是牛...
死磕 Java 并发 就是牛...
forEachOrdered():与forEach类似,但保留了元素的顺序。
forEachOrdered() 会保证元素的顺序不会发生变化 ,输出将按原始顺序产生。
@Test
public void forEachOrderedTest() {
List<String> list = Arrays.asList("死磕 Java 新特性","死磕 Java","死磕 Netty","死磕 Java 并发");
System.out.println("================ forEach 结果 ================ ");
list.parallelStream().forEach(System.out::println);
System.out.println("================ forEachOrdered 结果 ================ ");
list.parallelStream().forEachOrdered(System.out::println);
}
// 结果......
================ forEach 结果 ================
死磕 Netty
死磕 Java 并发
死磕 Java 新特性
死磕 Java
================ forEachOrdered 结果 ================
死磕 Java 新特性
死磕 Java
死磕 Netty
死磕 Java 并发
从这个输出结果就可以看出两者的差异了吧?如果我们将 list.parallelStream().forEach(System.out::println); 调整为 list.stream().forEach(System.out::println); 则两个输出结果是一样的,因为 stream() 产生的是一个顺序流。
forEachOrdered() 通常在需要保持元素处理顺序的情况下使用,特别是在使用并行流时,以确保元素按照原始顺序进行处理。
归约
reduce(BinaryOperator<T> accumulator):归约为一个值(无初始值)
accumulator是一个BinaryOperator函数,用于定义归约操作,接受两个参数,合并它们并返回一个结果。比如我们要求1 ~ 10的和:
@Test
public void reduceTest() {
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
Optional<Integer> optional = list.stream().reduce((a,b) -> a + b);
System.out.println(optional.orElse(0));
}
// 结果......
55
reduce(T identity, BinaryOperator<T> accumulator):归约为一个值,有初始值
identity是一个初始值,用作归约的起始值。
该方法从 identity 开始,将 accumulator 函数应用于流中的第一个元素和 identity,然后将结果作为下一个元素的 identity 继续,如此重复,直到所有元素都被处理,最后返回归约后的结果。如果流为空,则返回 identity作为最终结果。
@Test
public void reduceTest() {
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
Integer reduce = list.stream().reduce(10,(a,b) -> a + b);
System.out.println(reduce);
}
// 结果......
65
T reduce(T identity, BinaryOperator<T> accumulator, BinaryOperator<T> combiner):归约为一个值(有初始值),并提供并行执行时的并行归约操作。
combiner是一个BinaryOperator函数,用于定义并行执行时如何合并归约的部分结果。
该方法用于在并行流的情况下执行归约操作。identity用作初始值,accumulator函数应用于流中的各个部分,然后combiner函数用于合并这些部分结果,最终得到一个归约后的结果。
@Test
public void reduceTest() {
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
Integer reduce = list.parallelStream().reduce(0,(a,b) -> a + b,(a,b) -> a + b);
System.out.println(reduce);
}
收集
collect():将流中的元素收集到集合或映射中,可以指定收集器来定制收集行为。
方法定义如下:
<R, A> R collect(Collector<? super T, A, R> collector)
R是收集操作的最终结果类型。A是中间累积类型,通常由Collector定义的累积器类型。Collector<? super T, A, R>是一个用于收集元素的Collector,它包含了四种操作:创建累积器、累积元素、合并中间结果和完成收集。它通常由Collectors工具类提供,用于执行常见的收集操作,例如收集到List、Set、Map等容器中,当然我们也可以使用自定义的Collector来执行复杂的收集操作。
另外,Java 8 提供了一个工具类:Collectors,它提供了一系列预定义的静态方法,这些方法可以用于执行各种常见的收集操作,包括将元素收集到列表、集合、映射、分组、统计等等,不需要我们编写复杂的自定义逻辑,是不是很人性化?静态方法如下:
| 方法名 | 描述 |
|---|---|
toList() | 将元素收集到一个List中。 |
toSet() | 将元素收集到一个Set中,去除重复元素。 |
toCollection(Supplier<C> collectionFactory) | 将元素收集到指定类型的集合,使用提供的工厂函数创建集合。 |
toMap(keyMapper, valueMapper) | 将元素收集到一个Map中,指定键和值的映射方式。 |
toMap(keyMapper, valueMapper, mergeFunction) | 将元素收集到一个Map中,指定键和值的映射方式,并提供冲突解决策略。 |
toConcurrentMap(keyMapper, valueMapper) | 将元素收集到一个并发ConcurrentMap中,指定键和值的映射方式。 |
toConcurrentMap(keyMapper, valueMapper, mergeFunction) | 将元素收集到一个并发ConcurrentMap中,指定键和值的映射方式,并提供冲突解决策略。 |
counting() | 计算元素的数量,并返回一个Long。 |
summingInt() | 对Integer属性进行求和。 |
summingLong() | 对Long属性进行求和。 |
summingDouble() | 对Double属性进行求和。 |
averagingInt() | 计算Integer属性的平均值。 |
averagingLong() | 计算Long属性的平均值。 |
averagingDouble() | 计算Double属性的平均值。 |
maxBy(comparator) | 找到最大元素,使用指定的比较器。 |
minBy(comparator) | 找到最小元素,使用指定的比较器。 |
joining() | 将元素拼接成一个字符串,可以指定分隔符、前缀和后缀。 |
mapping() | 对元素进行映射操作,然后将结果收集。 |
partitioningBy(predicate) | 将元素根据给定条件分成两个部分,返回一个Map<Boolean, List<T>>。 |
partitioningBy(predicate, downstream) | 将元素根据给定条件分成两个部分,并对每个部分应用另一个收集器。 |
groupingBy(classifier) | 将元素按照给定的分类器分组,返回一个Map<K, List<T>>。 |
groupingBy(classifier, downstream) | 将元素按照给定的分类器分组,并对每个组应用另一个收集器。 |
collect() 配合 Collectors 使对流中的元素进行灵活的收集和处理变得非常方便,适用于各种数据处理需求。使用技巧很多,大明哥就不列举了,在下篇文章大明哥会列举一些常见使用技巧。
示例
上面大明哥对 Stream 做了一个非常详细的介绍,几乎每个方法都做了说明和举例了,但是这些例子都是比较简单的,而且 API 都是单独使用,然而在实际开发过程中,我们大部分都需要用 Stream 来处理一些复杂的场景,所以下面大明哥用几个复杂点的示例来教你如何正确使用 Stream,玩转集合 的筛选、归约、分组、聚合等操作。
案例使用的基础数据
定义两个类。
- 班级类
@Data
@AllArgsConstructor
public class Class {
/**
* 班级名称
*/
private String name;
/**
* 学生
*/
private List<Student> students;
}
- 学生
@Data
@AllArgsConstructor
public class Student {
/**
* 姓名
*/
private String name;
/**
* 年龄
*/
private Integer age;
/**
* 性别
*/
private String gender;
/**
* 成绩
*/
private Integer grade;
}
- 样例数据
public List<Class> getClassList() {
List<Student> students1 = Arrays.asList(
new Student("张三", 18, "男", 456),
new Student("李四", 17, "女", 432),
new Student("王五", 16, "男", 368),
new Student("小红", 18, "女", 511),
new Student("小明", 17, "男", 517)
);
List<Student> students2 = Arrays.asList(
new Student("小丽", 16, "女", 554),
new Student("刘六", 18, "男", 587),
new Student("陈七", 17, "男", 502),
new Student("赵八", 16, "男", 498)
);
List<Student> students3 = Arrays.asList(
new Student("林九", 18, "女", 356),
new Student("郑十", 17, "男", 411),
new Student("孙十一", 16, "男", 435),
new Student("吴十二", 18, "女", 389),
new Student("朱十三", 17, "女", 490),
new Student("许十四", 16, "男", 543)
);
List<Student> students4 = Arrays.asList(
new Student("何十五", 18, "女", 612),
new Student("胡十六", 17, "男", 698) ,
new Student("王十七", 16, "女", 687),
new Student("黄十八", 18, "男", 665),
new Student("马十九", 17, "男", 701),
new Student("周二十", 16, "女", 711),
new Student("郭二一", 18, "男", 689)
);
List<Student> students5 = Arrays.asList(
new Student("林二二", 17, "男", 567),
new Student("吴二三", 16, "男", 587),
new Student("谢二四", 18, "女", 687),
new Student("胡二五", 17, "女", 598),
new Student("何二六", 16, "男", 654),
new Student("王二七", 18, "女", 512),
new Student("徐二八", 17, "男", 633),
new Student("刘二九", 16, "女", 632)
);
return Arrays.asList(
new Class("一班",students1),
new Class("二班",students2),
new Class("三班",students3),
new Class("四班",students4),
new Class("五班",students5)
);
}
01、获取一班中学生的平均年龄
@Test
public void test1() {
double age = getClassList().stream()
.filter(x -> x.getName().equals("一班")) // 过滤一班
.flatMap(cl -> cl.getStudents().stream()) // 获取一班的学生
.mapToInt(Student::getAge) // 拿到一班学生的年龄
.average() // 求平均值
.orElse(0);
System.out.println(age);
}
// 结果......
17.2
首先通过 filter() 将“一班”过滤出来,然后通过 flatMap() 获取“一班”的学生列表,最后 average() 求平均值,由于 average() 返回的 OptionalDouble,利用 orElse(0) 转换下就可以了
02、找出所有班级中的学生中的最高分数
@Test
public void test2() {
Integer maxGrade = getClassList().parallelStream()
.flatMap(cl -> cl.getStudents().stream()) //获取所有班级的所有学生列表
.max(Comparator.comparing(Student::getGrade)) //获取成绩最高的学生
.map(Student::getGrade) // 得到该成绩
.orElse(0);
System.out.println(maxGrade);
}
// 结果......
711
这里创建 Stream 使用的是 parallelStream()。利用 flatMap() 获取所有班级的所有学生,max() 得到分数最高的学生,最后利用 map() 提取这个最高分。
03、获取所有班级中的学生的数量
@Test
public void test3() {
long count = getClassList().stream()
.flatMap(cl -> cl.getStudents().stream())
.count();
System.out.println(count);
}
// 结果......
30
还可以改成这种方式:
@Test
public void test3() {
long count = getClassList().stream()
.mapToLong(cl -> cl.getStudents().size())
.sum();
System.out.println(count);
}
04、获取所有学生中的男女数量
@Test
public void test4() {
Map<String,Long> genderMap = getClassList().stream()
.flatMap(cl -> cl.getStudents().stream())
.collect(Collectors.groupingBy(Student::getGender,Collectors.counting()));
System.out.println(genderMap);
}
// 结果......
{女=13, 男=17}
采用 Collectors.groupingBy() 根据性别分组,然后再利用 collect() 收集。
05、统计每个班级的男女数量
@Test
public void test5() {
Map<String,Map<String,Long>> genderMap = getClassList().stream()
.collect(Collectors.toMap(Class::getName,
cl -> cl.getStudents().stream()
.collect(Collectors.groupingBy(Student::getGender,Collectors.counting()))));
System.out.println(genderMap);
}
// 结果......
{五班={女=4, 男=4}, 一班={女=2, 男=3}, 四班={女=3, 男=4}, 二班={女=1, 男=3}, 三班={女=3, 男=3}}
这个例子稍微有点儿复杂,要分两次分组,第一次按班级来,第二次按性别来。
06、找出所有班级中成绩前10名的学生
@Test
public void test6() {
List<Student> students = getClassList().stream()
.flatMap(cl -> cl.getStudents().stream())
.sorted(Comparator.comparing(Student::getGrade).reversed()) // 根据成绩排序
.limit(10) // 获取前 10 名
.collect(Collectors.toList());
System.out.println(students);
}
// 结果......
[Student(name=周二十, age=16, gender=女, grade=711), Student(name=马十九, age=17, gender=男, grade=701), Student(name=胡十六, age=17, gender=男, grade=698), Student(name=郭二一, age=18, gender=男, grade=689), Student(name=王十七, age=16, gender=女, grade=687), Student(name=谢二四, age=18, gender=女, grade=687), Student(name=黄十八, age=18, gender=男, grade=665), Student(name=何二六, age=16, gender=男, grade=654), Student(name=徐二八, age=17, gender=男, grade=633), Student(name=刘二九, age=16, gender=女, grade=632)]
sorted() 按照成绩排序,要倒序,所以使用 reversed() 来逆序下,最后 limit() 获取前 10 个用户。
07、找出每个班级成绩前 3 名的学生
@Test
public void test7() {
Map<String,List<Student>> result = getClassList().stream()
.collect(Collectors.toMap(Class::getName,
cl -> cl.getStudents().stream()
.sorted(Comparator.comparing(Student::getGrade).reversed())
.limit(3)
.collect(Collectors.toList())));
System.out.println(result);
}
// 结果......
{五班=[Student(name=谢二四, age=18, gender=女, grade=687), Student(name=何二六, age=16, gender=男, grade=654), Student(name=徐二八, age=17, gender=男, grade=633)], 一班=[Student(name=小明, age=17, gender=男, grade=517), Student(name=小红, age=18, gender=女, grade=511), Student(name=张三, age=18, gender=男, grade=456)], 四班=[Student(name=周二十, age=16, gender=女, grade=711), Student(name=马十九, age=17, gender=男, grade=701), Student(name=胡十六, age=17, gender=男, grade=698)], 二班=[Student(name=刘六, age=18, gender=男, grade=587), Student(name=小丽, age=16, gender=女, grade=554), Student(name=陈七, age=17, gender=男, grade=502)], 三班=[Student(name=许十四, age=16, gender=男, grade=543), Student(name=朱十三, age=17, gender=女, grade=490), Student(name=孙十一, age=16, gender=男, grade=435)]}















 8839
8839

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









