







SIMD函数的Intel官网
AVX和AVX2指令的介绍
我调用的是函数,不是汇编指令(special C functions called intrinsic functions)
每个函数实际调用的可能不止1个指令,例如_mm256_fmadd_ps后面实际调用了3个函数
函数命名规则:_mm<bit_width>_<name>_<data_type>
<bit_width>是返回值位长度;<name>是功能;<data_type>是输入参数类型;
只需要 #include <immintrin.h> 即可,不需要链接任何库,该头文件包含其他头文件会把函数映射到指令上;
初始化函数,是按Little-endian来的,{}里第一个数其实在内存里被放到最后;
用_m256_load_*把数据从内存加载到__mm256变量里,要求内存里的数据必须按32位对齐,否则会报段错误;用 _m256_loadu_*来加载不一定对齐的数据;
mm256_maskload_*可用来对付末尾不足256位的数据,比如最后还剩3个float(8个float才满),则mask住的在结果里置0;
整型的计算有adds版本:_mm256_adds_epi8,处理“saturation”,"饱和"问题,即结果超出范围后自动锁定在最大or最小值上;不用带s的会直接返回越界后的数值;
水平相加函数:

乘法,因为位数会增一倍,所以一种函数是只乘一半数目,一种函数是都乘但是只保留低位在结果中;
减少浮点乘法的精度损失:instead of returning round(round(a * b) + c), they return round(a * b + c)
_mm256_permute_ps:把1个256位的8个float打散放到1个256位的8个float结果中;
_mm256_shuffle_ps :把2个256位的一共16个float打散挑8个放到1个256位的8个float结果中;
向量reduce的例子
(我们Conv-DSSM的3个向量加和,根本不需要reduce的!我们只用了_mm256_add_ps做3个向量加和和_mm256_max_ps做词组向量max-pooling)

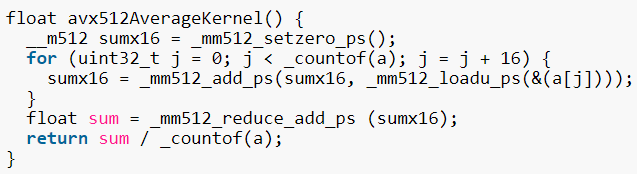
reduce函数是AVX512才支持的!AVX2不支持!














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









