






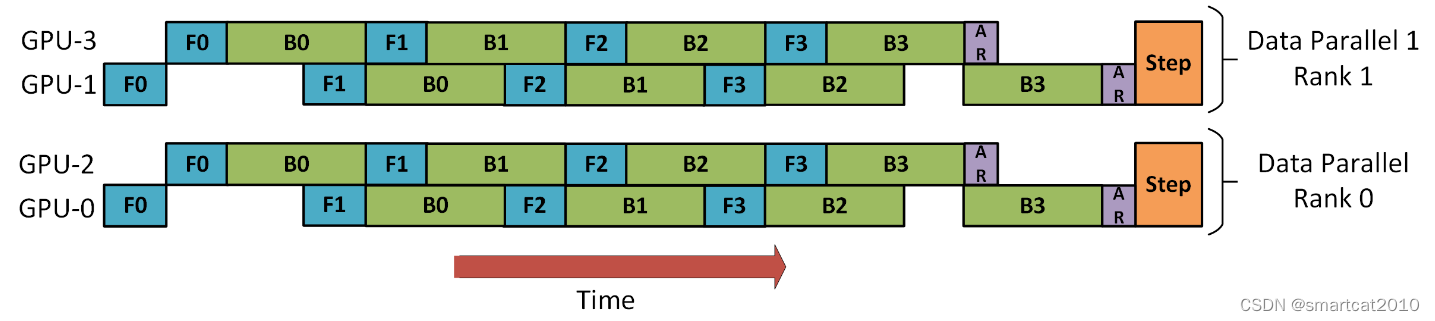
DeepSpeed为了克服一般Pipeline并行的forward时weights,和backward时计算梯度的weights, 二者不相同的问题,退而求其次,牺牲性能,采用gradient-accumulate方式,backward时只累积梯度至local,并不更新weights;多个micro-batch完成之后,才all-reduce一把并更新weights;
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
...
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
...
nn.Linear(4096, num_classes),
)
def to_layers(self):
layers = [
*self.features,
self.avgpool,
lambda x: torch.flatten(x, 1),
*self.classifier
]
return layers
from deepspeed.pipe import PipelineModule
net = AlexNetPipe()
pipeline_model = PipelineModule(layers=net.to_layers(), num_stages=2)
model_engine, _, _, _ = deepspeed.initialize(
args=args,
model=pipeline_model,
model_parameters=pipeline_model.parameters(),
training_data=trainset
)
for epoch in range(num_epochs):
iter_data = iter(trainloader)
for i in range(num_iters):
loss = model_engine.train_batch()具体例子:https://github.com/microsoft/DeepSpeedExamples/tree/master/training/pipeline_parallelism
第1各stage的rank,会去读data features;最后一个stage的rank,会去读data label;
layer划分至各GPU的策略:
1. partition_method="parameters":按可训练参数量,来均匀划分 ;(默认)
2. partition_method="type:[regex]":按name划分;凡是匹配该正则表达式的layers,按个数均匀分摊至各GPU;例如,名字里含有"transformer"的层,每个GPU来分到相同个数。
3. partition_method="uniform":按层数的个数来均匀划分;















 3505
3505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









