







一、分布式并行理论
0. 分布式并行内容介绍
分布式并行分数据并行、模型并行(张量并行、流水并行)、多维混合并行三类。
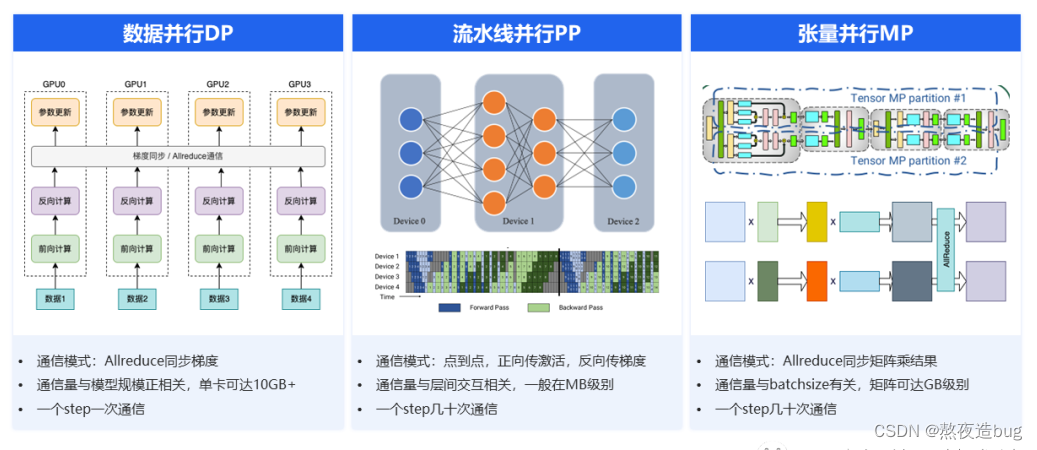
图1. 分布式并行(引用自ZOMI酱up主)
1. 数据并行
将大数据集分割成小批次,分布到多个设备上进行训练。每个设备拥有模型的完整副本,独立进行前向和反向传播。通过聚合各个设备的梯度来更新模型参数。
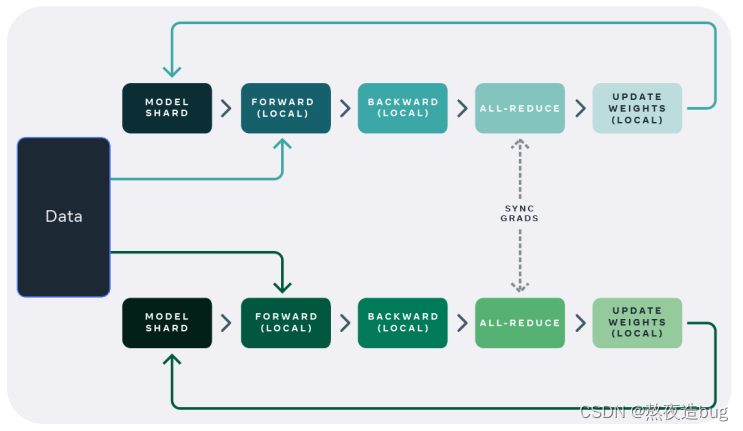
图1. 数据并行(引用自ZOMI酱up主)
# 数据并行关键代码
device = torch.device('cuda: 1, 3')
model = CreateModel()
# 数据并行的标记
model = nn.DataParallel(model, device_ids=[1, 3])
model.to(device)1.1. 数据并行DP
- 也称为单机多卡数据并行。
- 在单个节点上使用多个GPU进行训练。
- 将输入数据分割并在不同的GPU上并行处理。
- 梯度同步通常通过简单的集合操作(如sum或average)实现。
1.2. 分布式数据并行DDP
- 适用于跨多个节点的分布式训练。
- 每个节点都有模型的完整副本和一部分数据。
- 使用 PyTorch 的 DistributedDateParallel 模块,该模块处理了梯度的聚合和通信。
- 需要配置进程组(process group)来管理不同节点间的通信。
1.3. 分片共享数据并行FSDP
- 一种更细粒度的数据并行策略,适用于大规模模型。
- 模型被分割成多个部分(shards),每个部分在不同的GPU上运行。
- 适用于单个GPU无法容纳整个模型的情况。
- 需要更复杂的通信和同步机制,因为它涉及到模型的切分
1.4. 主要区别
- 应用场景:DP主要用于单机多GPU环境,DDP适用于多节点多GPU的分布式环境,而FSDP适用于需要在多个GPU上分割模型的大规模模型训练。
- 模型和数据分布:DP中模型副本在不同GPU上但在同一节点,DDP模型副本分布在不同节点,FSDP模型被切分成多个部分分布在不同GPU上。
- 通信复杂性:FSDP在模型切分和梯度同步方面通常比DP和DDP更复杂。
2. 模型并行
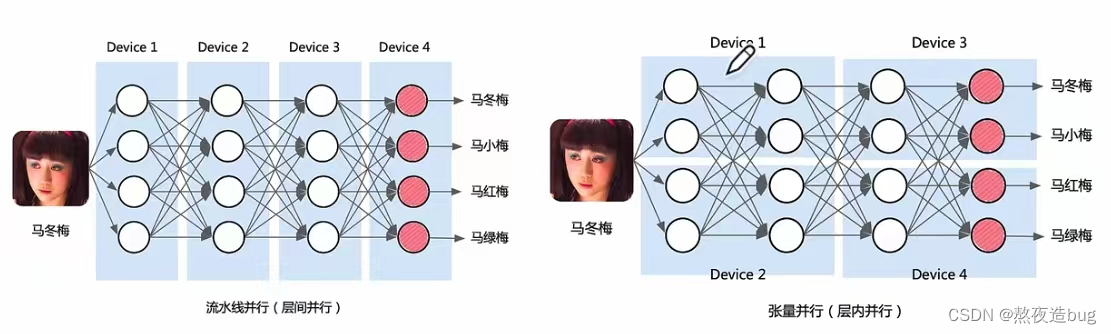
图2. 模型并行(流水并行、张量并行,引用自ZOMI酱up主)
2.1. 流水并行PP
按模型Layer层切分到不同设备,即层间并行。
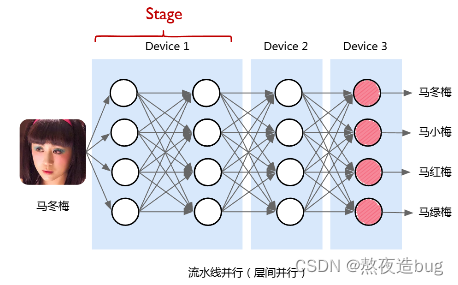
图3. 流水并行(引用自ZOMI酱up主)
2.2. 张量并行TP
数学原理如下:
(1)双设备张量切分
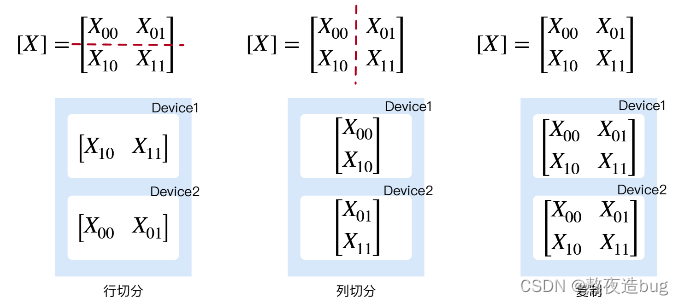
图4
(2)四设备张量切分
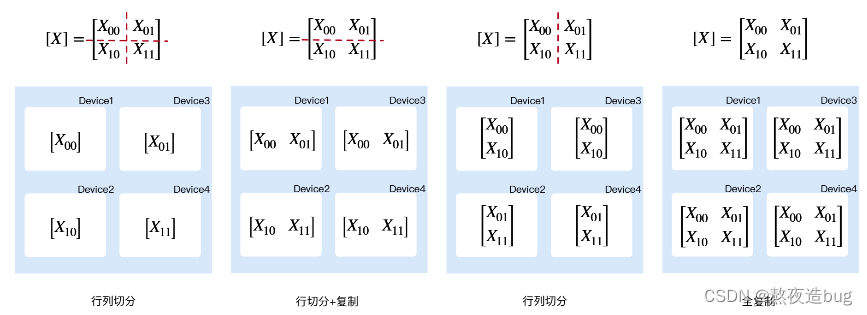
图5
(3)切分到两个节点的 Tensor 节点张量重排
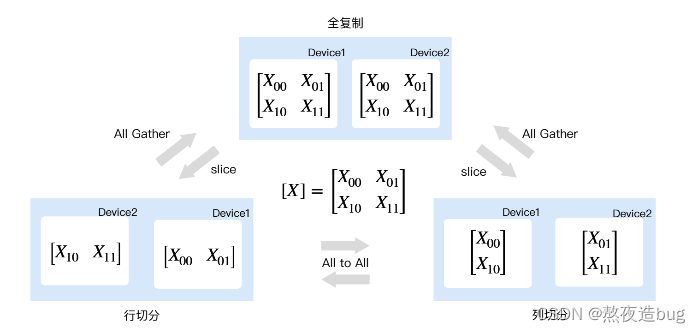
图6
3. 多维混合并行
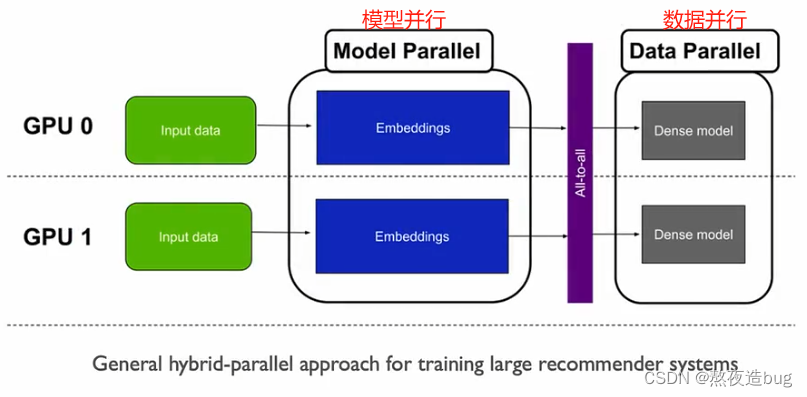
图7
3.1. 混合并行(Hybrid Parallelism):
混合并行包括数据并行、模型并行(张量并行和流水并行)以及pipeline并行。指将不同的并行策略结合使用,以充分利用硬件资源并提高训练效率。它可以显著提高大规模分布式训练的效率,尤其是在处理大型模型时。
3.2. 多维并行(Multi-Dimensional Parallelism):
多维并行是指在不同的维度上应用并行策略,例如在数据维度、模型维度和计算步骤维度上同时进行并行处理。这种并行方式允许模型在多个维度上扩展,从而更好地适应不同的硬件配置和训练需求,可以更全面地利用分布式系统的计算能力。
二、分布式并行实践(以DeepSpeed为例)
视频教程:DeepSpeed:炼丹小白居家旅行必备【神器】_哔哩哔哩_bilibili
github: GitHub - OvJat/DeepSpeedTutorial: DeepSpeed Tutorial
参考说明
1. DeepLearningSystem/06Foundation/08Parallel/old at main · chenzomi12/DeepLearningSystem (github.com)![]() https://github.com/chenzomi12/DeepLearningSystem/tree/main/06Foundation/08Parallel/old2. 混合并行?多维并行?有多维度混合在一起并行吗?【分布式并行】系列第06篇_哔哩哔哩_bilibili
https://github.com/chenzomi12/DeepLearningSystem/tree/main/06Foundation/08Parallel/old2. 混合并行?多维并行?有多维度混合在一起并行吗?【分布式并行】系列第06篇_哔哩哔哩_bilibili![]() https://www.bilibili.com/video/BV1gD4y1t7Ut/?spm_id_from=333.788&vd_source=741fbd6a09f652574b8e335339fdc5703. CIFAR-10 Tutorial - DeepSpeed
https://www.bilibili.com/video/BV1gD4y1t7Ut/?spm_id_from=333.788&vd_source=741fbd6a09f652574b8e335339fdc5703. CIFAR-10 Tutorial - DeepSpeed![]() https://www.deepspeed.ai/tutorials/cifar-10/4. Getting Started - DeepSpeed
https://www.deepspeed.ai/tutorials/cifar-10/4. Getting Started - DeepSpeed![]() https://www.deepspeed.ai/getting-started/
https://www.deepspeed.ai/getting-started/















 2383
2383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









