







强化学习基本概念
、
Agent根据上一步Environment给出的State和Reward,以及自己的内在策略,做出Action;
Action给到Environment,Environment给出State和Reward,给到Agent去做下一步Action;
该游戏中,State就是游戏画面,Reward就是吃的分、通关等奖励(或者被打死等惩罚),Action就是超级玛丽下一步的<上、下、左、右、静止>动作。Agent是超级玛丽。Environment是游戏机。
目标:学习到一个最优的策略,通过该策略下走的Action序列,拿到尽可能多的Reward总和。
每一步的Action,要做长远考虑,不能只看这一步的Reward,而要尽量使今后的长远Reward之和,也就是Return,最大化。
数学期望(概率加权平均):
强化学习的目标:(2种说法)
数学表达式:
:学习到的策略(模型)
:在该策略下采样得到的轨迹Trajectory
: 该轨迹的Return(Reward之和)
: 在该策略下采样得到该轨迹的概率


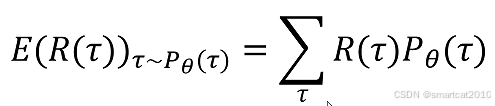
策略梯度的推导:
要最大化E,就要求出
去掉梯度求导,得到:
即对上式进行最大化。
直观含义:
当R(即Return)>0时,让每个状态s下生成这个action a的概率尽量增大。
当R(即Return)<0时,让每个状态s下生成这个action a的概率尽量减小。
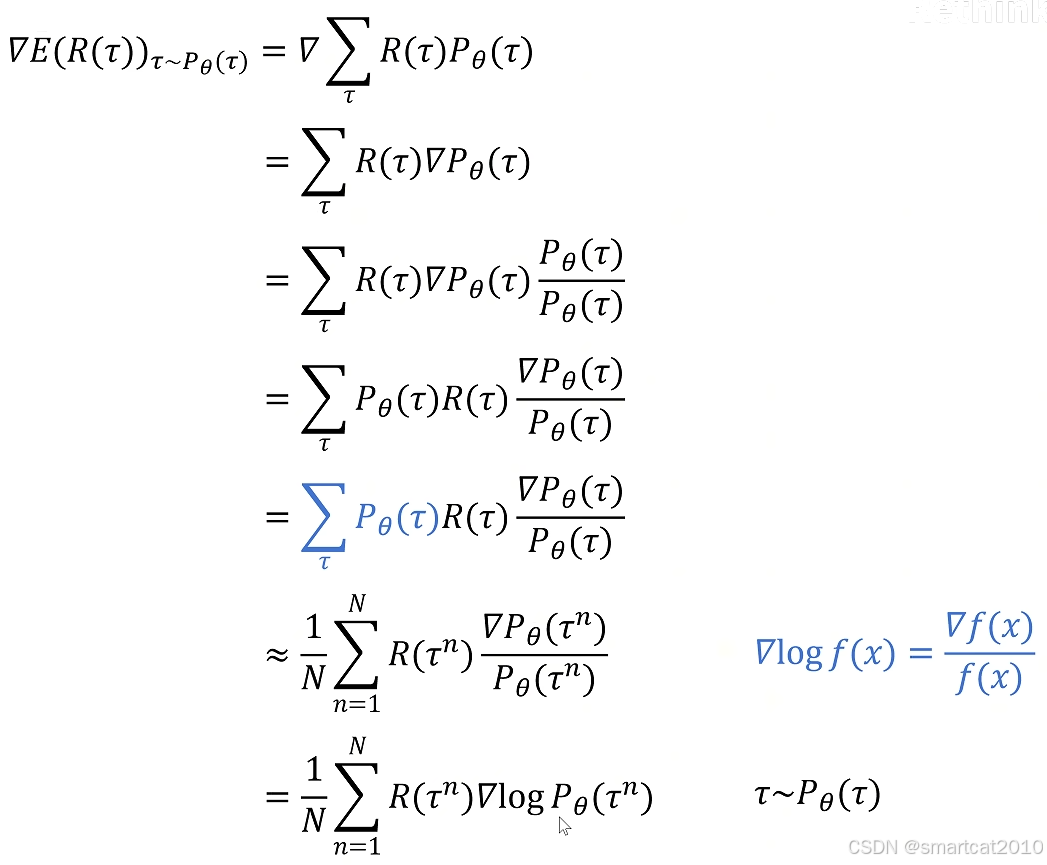
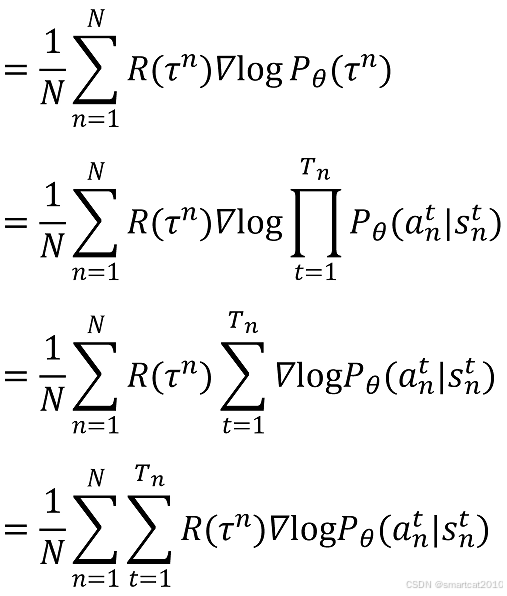
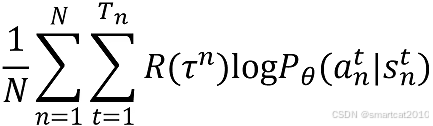
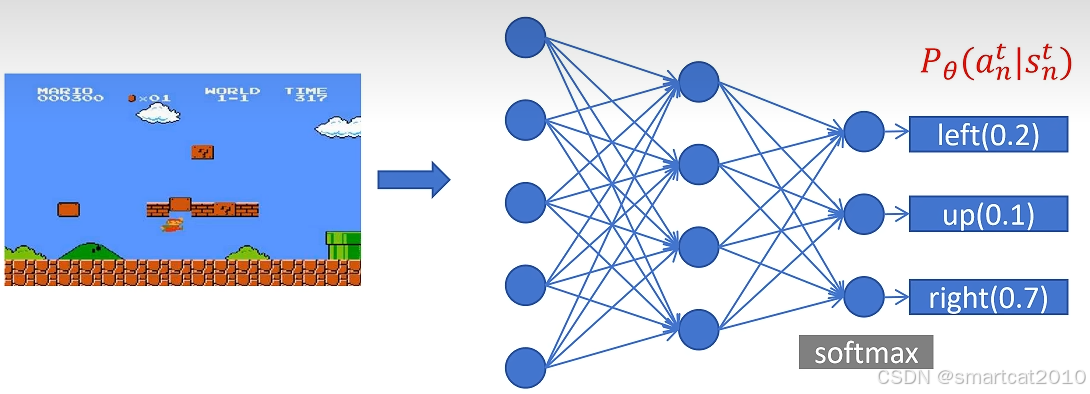
超级玛丽的例子:
定义loss函数:(就是把最大化上式改成最小化下式)
游戏画面是s,作为神经网络的输入;超级玛丽的动作是a,作为神经网络的分类输出;
使用上面的神经网络,玩N次游戏,即采样得到N条轨迹,每条轨迹对应一个Return R:
对每条轨迹,有了R,就可以计算每一步的梯度了;所有轨迹的所有步的梯度,累加起来,更新模型:
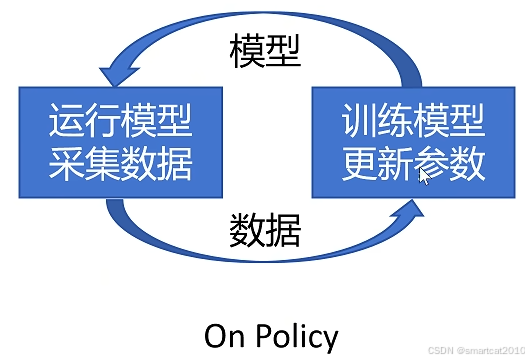
On Policy:采集数据的模型,和训练的策略模型,是同一个模型。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









