







一直想找一个高效的采集电影信息的方法,查了下网上资料, 说最快的方式是aiohttp+asyncio, 后来实测了一下,发现还是等待时间太长,直到报了超时错误, 可能是电脑性能以及网速的原因,继续尝试使用asyncio+selenium, 还是报了超时错误, 后期尝试知乎上推荐的aiomultiprocess, 以及ChatGPT推荐的aiopool库,都不行, aiopool库还导入不了AioPool(限制并发数的模块),后来思考了一下发现还是得通过限制并发数的方法来充分利用电脑的最大性能,再次咨询ChatGPT后发现由于gevent使用了更底层的协程 API,因此性能更加高效,尤其在IO密集型任务中,它的效率更高, 最终决定使用gevent协程池+selenium去采集数据了.
#!usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2023/5/16 13:51
# @Author : l84171088
# @Email : laihuajian@huawei.com
# @File : get_movies_data.py
# @Software: PyCharm
import os
import logging
import traceback
from gevent import monkey, pool
monkey.patch_all()
import gevent
import pandas as pd
import lxml.html as lh
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
def log_func(root_path):
"""
项目运行日志
:param root_path:项目根路径
:return:
"""
log_name = 'py_log' # 日志名称(默认py_log)
log_level = logging.DEBUG # 日志等级(默认DEBUG)
console = True # 是否在控制台输出(默认在控制台输出)
# 日志输出格式
log_format = u'[%(asctime)s] - [%(filename)s :%(lineno)d line] - %(levelname)s: %(message)s'
# 日志文件的名称和路径
log_file_path = os.path.join(root_path, "Output\\" + 'py_log_file.txt')
# 日志文件夹
log_dir_path = os.path.dirname(log_file_path)
if not os.path.exists(log_dir_path): # 判断文件夹是否存在
os.makedirs(log_dir_path) # 创建日志文件夹
py_loges = logging.getLogger(log_name) # 创建log
py_loges.setLevel(log_level) # 设置等级
# 定义log输入格式
formatter = logging.Formatter(log_format)
file_handler = logging.FileHandler(log_file_path) # 创建文件
file_handler.setFormatter(formatter)
file_handler.setLevel(logging.DEBUG) # 设置写入日志文件的内容
py_loges.addHandler(file_handler)
if console:
console_handler = logging.StreamHandler() # 创建控制台
console_handler.setFormatter(formatter)
py_loges.addHandler(console_handler)
with open(log_file_path, "a+") as f:
f.truncate()
return py_loges
# 获取文件目录
cur_path = os.path.abspath(os.path.dirname(__file__))
# 获取项目根路径,内容为当前项目的名字
path_root = cur_path[:cur_path.find('mysite') + len('mysite')]
logger = log_func(path_root) # 日志对象
def get_movie_urls(driver, pages_url):
"""
获取所有电影href
:param driver:浏览器驱动
:param pages_url:每页30部电影数据的页面url
:return:所有电影url列表
"""
try:
logger.info(f'开始采集{pages_url}')
driver.get(pages_url)
driver.implicitly_wait(180)
html_urls = driver.page_source # 获取源网页
doc_urls = lh.fromstring(html_urls)
# 每页数据的电影href列表, 为了避免缓存元素引起异常, 现在直接返回元素链接
page_href = doc_urls.xpath("//ul[@id='content']//li/a/@href")
return page_href
except:
logger.error(traceback.format_exc(), exc_info=True)
def get_movie_info(driver, movie_url):
"""
获取所有电影名称.年代.主演.导演.简介等信息
:param driver:浏览器驱动
:param movie_url:电影url
:return:
"""
try:
logger.info(f"开始获取{movie_url}电影名称.年代.主演.导演.简介等信息")
driver.get(movie_url)
html_doc = driver.page_source # 获取源网页
doc = lh.fromstring(html_doc)
# 在这里解析网页,获取所需的电影信息数据
# 电影封面图片
# movie_pic = doc.xpath("//div[@class='layout-boxc video-box']//div[@class='pic-img video-pic']/img/@src")
# 影片名称
movie_name = ';'.join(doc.xpath(
"//div[@class='layout-boxc video-box']//h1[@class='text-overflow']/text()"
))
# 状态
movie_statu = ';'.join(doc.xpath(
"//div[@class='layout-boxc video-box']/div[@class='container']/div/div[2]/div[1]/text()"
))
# 类型
movie_type = ';'.join(doc.xpath(
"//div[@class='layout-boxc video-box']/div[@class='container']/div/div[2]/div[2]//a/text()"
))
# 主演
the_lending_role = ';'.join(doc.xpath(
"//div[@class='layout-boxc video-box']/div[@class='container']/div/div[2]/div[3]//a/text()"
))
# 导演
director = ';'.join(doc.xpath(
"//div[@class='layout-boxc video-box']/div[@class='container']/div/div[2]/div[4]//a/text()"
))
# 年代
times = ';'.join(doc.xpath(
"//div[@class='layout-boxc video-box']/div[@class='container']/div/div[2]/div[5]/text()"
))
# 时长
duration = ';'.join(doc.xpath(
"//div[@class='layout-boxc video-box']/div[@class='container']/div/div[2]/div[6]/text()"
))
# 语言字幕
language_subtitles = ';'.join(doc.xpath(
"//div[@class='layout-boxc video-box']/div[@class='container']/div/div[2]/div[7]/text()"
))
# 国家地区
country_region = ';'.join(doc.xpath(
"//div[@class='layout-boxc video-box']/div[@class='container']/div/div[2]/div[8]/text()"
))
# 影视评论
film_reviews = doc.xpath(
"//div[@class='layout-boxc video-box']/div[@class='container']/div/div[2]/div[10]/a//text()"
)
# 简介
introduction = ';'.join(doc.xpath(
"//div[@class='layout-boxc video-box']/div[@class='container']/div/div[2]/div[11]/p/text()"
))
# 电影信息字典
dict_movie = {
'影片名称': [movie_name], '状态': [movie_statu], '类型': [movie_type],
'主演': [the_lending_role], '导演': [director], '年代': [times],
'时长': [duration], '语言字幕': [language_subtitles],
'国家地区': [country_region], '影视评论': [film_reviews],
'简介': [introduction]
}
logger.info(f'已获取{movie_url}电影信息字典数据')
return dict_movie
except:
logger.error(traceback.format_exc(), exc_info=True)
def main_spider():
try:
logger.info('开始采集...')
# 第一页的30部电影数据页面
url_page_1 = 'http://www.yy6080dy.cc//index.php?s=home-vod-type-id-1-picm-1-p-1'
# 待拼接的url前缀
url_base = url_page_1[:-1]
s = Service('D:\packages\chromedriver.exe') # 需要自行下载ChromeDriver并设置路径
option = webdriver.ChromeOptions()
option.add_argument("--headless")
driver = webdriver.Chrome(service=s, options=option)
driver.get(url_page_1)
html_page_1 = driver.page_source
# 获取电影页数
doc_page_1 = lh.fromstring(html_page_1)
# 电影总页数文本列表
content_numbers_pages = doc_page_1.xpath("//div[@id='page']/ul/li[9]")
if not content_numbers_pages:
logger.info('未获取到页数')
return '未获取到页数'
# 电影总页数
numbers_pages = int(content_numbers_pages[0].text_content())
logger.info(f'电影总页数为{numbers_pages}')
# 电影url的TXT文件储存路径
path_movie_href = os.path.join(os.getcwd(), 'movie_data/movies_hrefs.txt')
path_href_dir = os.path.dirname(path_movie_href)
pool_size = 10 # 协程池设置并发数为10
pool_obj = pool.Pool(size=pool_size)
if not os.path.exists(path_movie_href): # 如果不存在该txt, 那么就进行并发采集
result_hrefs_task = [] # 所有hrefs任务列表
# 获取所有电影href
for num_page in range(1, numbers_pages + 1):
result_hrefs_task.append(
pool_obj.spawn(get_movie_urls, driver, url_base + str(num_page)))
gevent.joinall(result_hrefs_task)
result_hrefs = [] # 所有电影href列表
for r in result_hrefs_task: # 所有电影href任务结果
result_hrefs += r.get()
# 所有电影完整url列表
result_hrefs = [r'http://www.yy6080dy.cc' + href for href in result_hrefs]
if not os.path.exists(path_href_dir):
os.makedirs(path_href_dir)
for href in result_hrefs:
with open(path_movie_href, 'a') as f:
f.write(href + '\n')
logger.info('已获取所有电影详细信息链接, 并存储在TXT文件中')
# 按行读取已经下载的电影href的TXT文件
with open(path_movie_href) as f:
result_hrefs = f.readlines()
# 去除换行符以及空值
result_hrefs = [h.strip() for h in result_hrefs if h != "" and h is not None]
# 获取每部电影详细信息的任务列表
task_movies_info = []
# 将每个URL的采集结果传递给下一个函数, 获取所有电影详细信息
for h in result_hrefs:
task_movies_info.append(pool_obj.spawn(get_movie_info, driver, h))
# 将所有获取电影信息的任务按照每次10个并发量分别执行,等待所有任务完成
gevent.joinall(task_movies_info)
movies_info_list = [] # 所有电影信息字典列表
for task_single in task_movies_info: # 所有电影href任务结果
movies_info_list.append(task_single.get()) # 添加单个任务产生的电影信息字典数据
df_movies = pd.DataFrame() # 存储电影信息的空DataFrame
for d_info in movies_info_list:
df_movies = df_movies.append(pd.DataFrame(d_info))
path_movies_info = os.path.join(os.getcwd(), 'movie_data/movies_info.xlsx')
path_movie_data = os.path.dirname(path_movies_info)
if not os.path.exists(path_movie_data):
os.makedirs(path_movie_data)
df_movies.to_excel(path_movies_info, index=False)
logger.info(f'已生成所有电影信息数据excel表')
driver.quit()
except:
logger.error(traceback.format_exc(), exc_info=True)
main_spider()
部分采集数据展示如下,运行时候忘记了打开monkey.patch_all(), 耗时会长一些
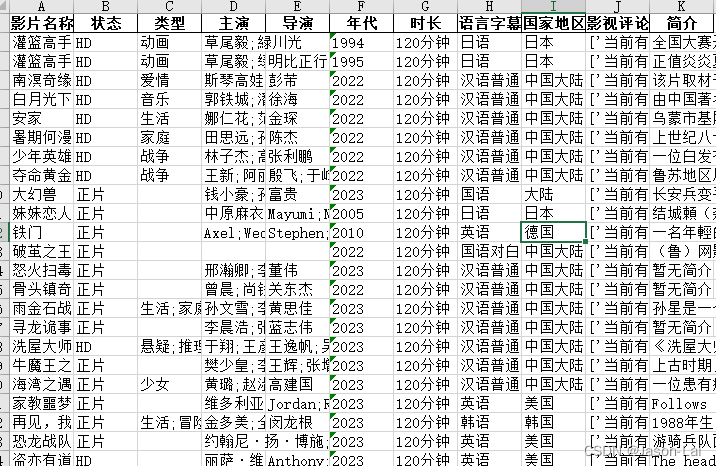

![]()
耗时11小时11分左右,如果并发数继续往上酌情调整,开启猴子补丁运行后,时间会成倍往下降















 1076
1076











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









