






HLS学习——循环
一、循环流水打拍
自动循环流水打拍
vadd:
for(int i = 0; i < len; i++)
{
c[i] = a[i] + b[i];
}
如上述代码所示,输入、输出、计算,需要三个周期才能完成上述操作。若 len = 20,则lantency = 60。若使用pipeline,则如下图所示:
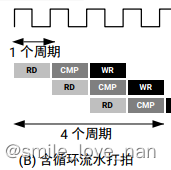
则只需要22个周期。对应代码为
vadd:
for(int i = 0; i < len; i++)
{
#pragma HLS PIPELINE
c[i] = a[i] + b[i];
}
其中,使用 pragma HLS pipeline 时, 您可以指定编译器要实现的 II。如果不指定目标 II, 那么默认情况下编译器将尝试实现 II=1,即当前迭代的一个周期后启动下一次迭代,若 II=2,则两个周期后启动。(#pragma HLS PIPELINE II=2)
回绕已流水打拍的循环以保障性能
PIPELINE 编译指示具有名为 rewind 的选项。该选项支持以重叠方式执行流水打拍循环的后续调用, 前提是此循环为数据流区域或顶层函数的最外层的构造(并且该数据流区域多次执行) 。
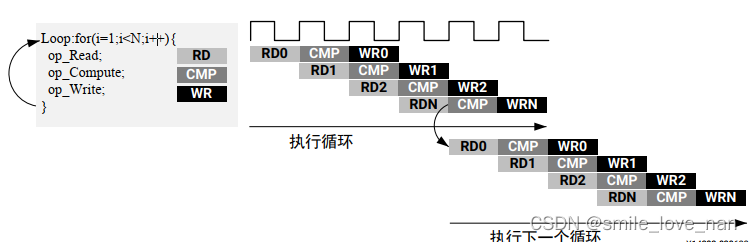
我个人认为是如下一种形式:
vadd:
for(int j = 0; j < len; j++)
{
#pragma HLS PIPELINE rewind
for(int i = 0; i < len; i++)
{
c[j][i] = a[j][i] + b[j][i];
}
}
刷新流水线和流水线类型
只要在流水线输入端数据可用, 流水线就会持续执行。如果没有可供处理的数据, 流水线就会停滞。如下图所示,Input Data Valid 信号转为低电平, 表示没有更多有效的输入数据。当此信号会变为高电平状态后, 即表示有新数据可供处理, 那么流水线就将继续操作。
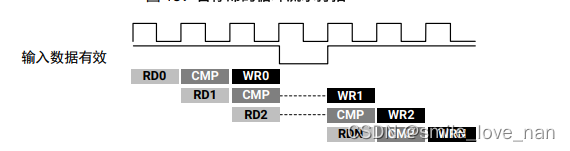
在某些情况下, 最好采用可“清空”或可“刷新”的流水线。提供 flush 选项即可执行此操作。当“刷新”流水线时, 如果没有新输入可用(由流水线起始位置的数据 valid 信号来判定), 流水线就会停止读取, 但仍会继续处理并关闭后续每个流水线阶段, 直至最终输入已处理至流水线输出为止。通过 **#pragma HLS pipeline style=frp **来指定停滞选项 (stp) 或可刷新流水线 (flp)。
管理流水线依赖关系
数据依赖关系”或“存储器依赖关系”的典型用例是在完成上一次读操作或写操作后再次发生读操作或写操作。其中有RAW(先写后读)、WRA(先读后写)、WAW(先写后写)。
二、展开循环
默认情况下, HLS 循环保持处于收起状态。这意味着循环的每次迭代都使用相同硬件。展开循环意味着, 循环的每次迭代都有其自己的硬件用于执行循环函数。这意味着, 展开的循环的性能显著高于收起的循环。但提升性能的代价是增加面积和资源利用率。假定循环边界为静态, 可使用 UNROLL 编译指示来完全展开循环, 以创建循环主体的并行实现。
三、合并循环
所有收起的循环都在设计 FSM 中指明并创建至少一种状态。当存在多个顺序循环时, 它可能会创建其它不必要的时钟周期, 并阻止进一步的最优化。
void top (a[4],b[4],c[4],d[4])
{
Add: for (i=3;i>=0;i--)
{
if (d[i])
a[i] = b[i] + c[i];
}
Sub: for (i=3;i>=0;i--)
{
if (!d[i])
a[i] = b[i] - c[i];
}
}
我们可以看到,循环Add和循环Sub中没有依赖关系,可以同时运行,但如果没有任何操作,需要十个周期。LOOP_MERGE 最优化指令用于自动合并循环。循环合并最优化指令将尝试合并其布局作用域内的所有循环。在上面的示例中, 完成它只需要 6 个时钟周期。
四、处理嵌套循环
• 完美循环嵌套: 仅限最内层的循环才有循环主体内容, 逻辑语句之间未指定任何逻辑, 所有循环边界均为常量
• 非完美循环嵌套: 内层循环具有变量边界, 或者循环主体未完全包含在内层循环内。在此情况下, 设计人员应尝试重构代码或者将循环主体中的循环展开以创建完美循环嵌套。
另外,已展开的嵌套循环之间的移动也需要额外的时钟周期。从外层循环移至内层循环需要一个时钟周期, 从内层循环移至外层循环同样如此。在此处所示小型示例中, 这暗示执行 Outer 循环需 200 个额外时钟周期。如下代码所示:
void foo_top { a, b, c, d}
{
Outer: while(j<100)
Inner: while(i<6) // 1 cycle to enter inner
LOOP_BODY
// 1 cycle to exit inner
}
Outer 循环需 200 个额外时钟周期。
set_directive_loop_flatten Inner
将该指令应用于一组嵌套循环时, 应将其应用于包含循环主体的最内层循环。这样就无需通过重新编码来最优化硬件性能, 并且还可减少执行循环中的运算所需的周期数。
五、处理变量循环边界
当循环边界由顶层输入驱动的变量 width 来判定。在此情况下, 循环被视为包含变量边界,
因为 Vitis HLS 无从知晓循环将何时完成。克服此问题的方法是使用 LOOP_TRIPCOUNT 编译指示或指令来为循环指定最小和/或最大迭代计数。循环次数(tripcount) 表示循环的迭代次数。解决方案是通过循环内部的条件执行来将循环迭代次数设置为固定值。可重写变量循环边界示例中的代码, 如以下代码示例所示。此处循环边界显式设置为变量宽度值 width 的最大值, 循环主体则以有条件方式来执行:
dout_t loop_max_bounds(din_t A[N], dsel_t width)
{
dout_t out_accum=0;
dsel_t x;
LOOP_X:for (x=0; x<N; x++)
{
if (x<width)
out_accum += A[x];
}
return out_accum;
}















 1240
1240











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









