







生活中无论有什么闪失,统统是自己的错,与人无尤,从错处学习改过,精益求精,直至不犯同一错误,从不把过失推诿到他人肩膀上去,免得失去学乖的机会。——《阿修罗》
1、概述
推荐系统是大数据中最常见和最容易理解的应用之一,比如说淘宝的猜你喜欢和京东等网站的用户提供个性化的内容。但是不仅仅只有电商会用推荐引擎为用户提供额外的商品,推荐系统也可以被用在其他行业,以及具有不同的应用中使用,如网易云音乐的每日歌曲推荐、活动、产品到约会对象。
2、大数据推荐系统架构
一般中型的网站(10W的PV以上),每天会产生1G以上Web日志文件。大型或超大型的网站,可能每小时就会产生10G的数据量。
具体来说,比如某电子商务网站,在线团购业务。每日PV数100w,独立IP数5w。用户通常在工作日上午10:00-12:00和下午15:00-18:00访问量最大。日间主要是通过PC端浏览器访问,休息日及夜间通过移动设备访问较多。网站搜索浏量占整个网站的80%,PC用户不足1%的用户会消费,移动用户有5%会消费。
对于日志的这种规模的数据,用HADOOP进行日志分析,是最适合不过的了。通过日志分析,增加销售量,出售更多不同的商品,提升用户满意度,更好的理解用户想要什么。下面是推荐系统离线模式和实时模式的推荐架构。两种架构经常是相互辅助使用。
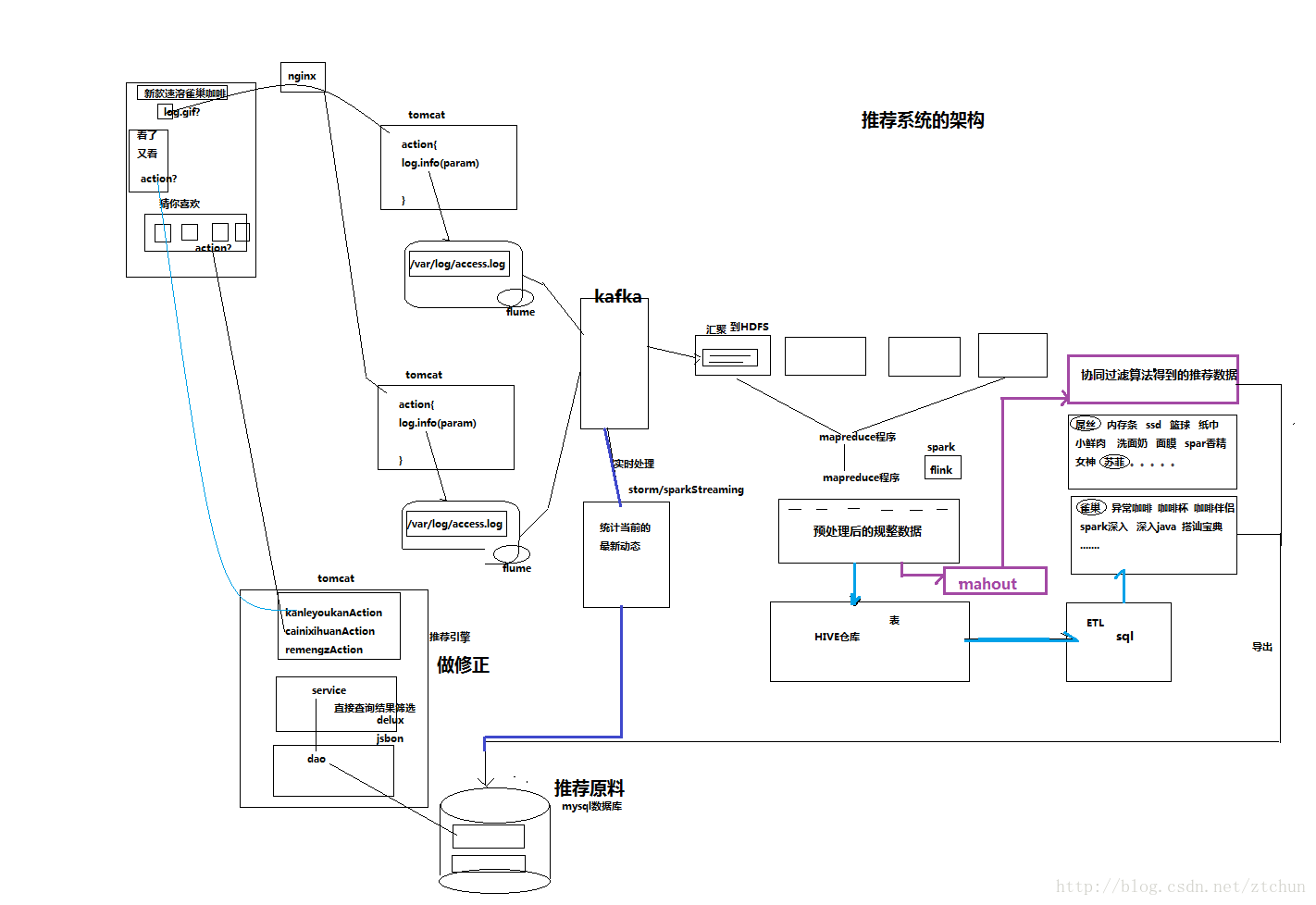
2.1 离线模式过程
(1)数据来源
在页面预埋一段js程序,为页面上想要监听的标签绑定事件,只要用户点击或移动到标签,即可触发ajax请求到后台servlet程序,用log4j记录下事件信息,从而在web服务器(nginx、tomcat等)上形成不断增长的日志文件。在移动设备上,通过访问接口,后端记录访问日志。
(2)数据采集
定制开发采集程序,或使用开源框架FLUME,flume是分布式的日志收集系统,它将各个服务器中的数据收集起来并送到指定的地方去,比如说送到图中的HDFS,简单来说flume就是收集日志的。
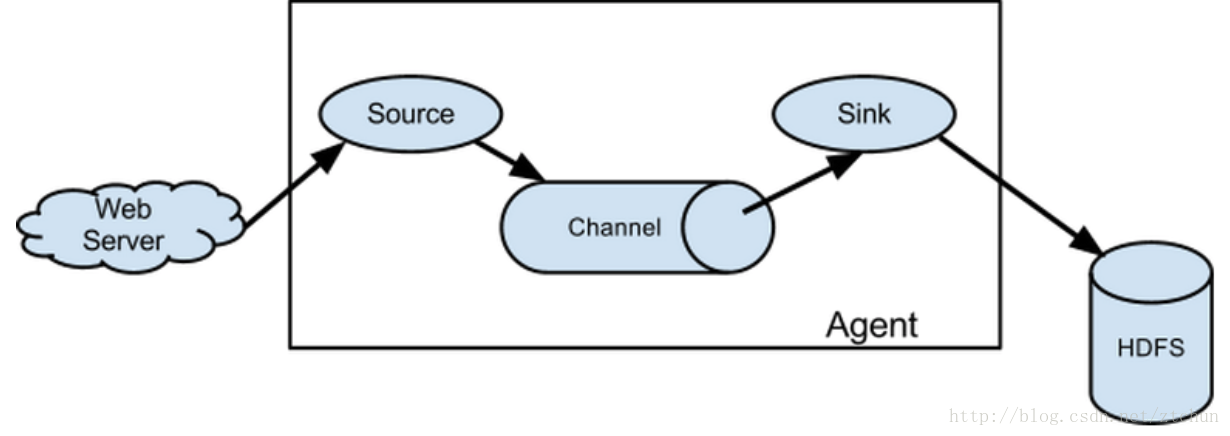
flume之所以这么神奇,是源于它自身的一个设计,这个设计就是agent,agent本身是一个java进程,运行在日志收集节点—所谓日志收集节点就是服务器节点。
agent里面包含3个核心的组件:source—->channel—–>sink,类似生产者、仓库、消费者的架构。
source:source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定义。
channel:source组件把数据收集来以后,临时存放在channel中,即channel组件在agent中是专门用来存放临时数据的——对采集到的数据进行简单的缓存,可以存放在memory、jdbc、file等等。
sink:sink组件是用于把数据发送到目的地的组件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定义
(3)数据汇聚
原始日志通过flume汇聚到HDFS分布式存储系统。
(4)数据预处理
定制开发mapreduce程序运行于hadoop集群,得到规整数据放入hdfs。
(5)数据仓库技术
基于hadoop之上的Hive,将规整数据映射成表。
(6)ETL
在hive进行数据查询,写sql导出结果。或者通过mahout机器学习算法分析出推荐数据写入到推荐原料。例如,协同过滤算法。
(7)推荐引擎
将推荐结果导入到业务数据库,web推荐引擎根据数据库进行推荐。
(8)可视化显示
根据业务数据库的推荐信息,前端显示推荐结果。
2.2 实时模式过程
热门事件,爆款。需要实时推荐。
(1)数据来源
在页面预埋一段js程序,为页面上想要监听的标签绑定事件,只要用户点击或移动到标签,即可触发ajax请求到后台servlet程序,用log4j记录下事件信息,从而在web服务器(nginx、tomcat等)上形成不断增长的日志文件。在移动设备上,通过访问接口,后端记录访问日志。
(2)数据采集
定制开发采集程序,或使用开源框架FLUME,flume是分布式的日志收集系统,它将各个服务器中的数据收集起来并送到指定的地方去,比如说HDFS,简单来说flume就是收集日志的。
(3)数据汇聚
原始日志通过flume汇聚到kafka集群。一部分数据发送给storm实时处理,另一部分发送给hdfs做离线处理。
(4)实时处理
通过storm和sparkStreaming读取kafka的消息进行数据实时处理,统计当前的最新动态到推荐原料。
(5)推荐引擎
将推荐结果导入到业务数据库,web推荐引擎根据数据库进行推荐。
(6)可视化显示
根据业务数据库的推荐信息,前端显示推荐结果。
3、总结
个性化产品推荐
推荐系统帮助理解每一位访问者的喜好和意图,并及时地展示相关的推荐类型和商品。随着引擎对每位访问者了解到更多,推荐系统也就得到了提升。
网站个性化
允许以实时区分和定位用户的个性化消息与提醒来增加销量和转化。
及时通知
这样的引擎帮助品牌建立与用户之间的信任,并在顾客访问网站时通过及时展示通知构造一种存在感和紧迫感。
个性化的客户忠诚度项目和服务
研究表明,与千篇一律的内容相比,人们对提供个性化服务的项目更感兴趣,与客户忠诚度有关的项目更是如此。这样的引擎基于与用户的实时交互能够定制推荐内容。数据分析算法运用不同的购买行为并整合上下文信息来关注不同的产品策略,这也提升了推荐的质量。
<link rel="stylesheet" href="https://csdnimg.cn/release/phoenix/production/markdown_views-68a8aad09e.css">
</div>















 1245
1245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









