







当大家遇到小数据的时候,大家可能想着在where后面多加点约束条件;当数据在大点的时候,大家可能就开始考虑给这添加索引了;当大家遇到百万级千万级数据的时候,大家就可能开始添加表分区了。
so,我就开始了我的分(keng)区(die)之旅。
一开始,由于我的这张大表有100多万数据量,就单单一个存储过程居然执行了一个多钟,于是,我便把这张大表改成分区表,并在ID上给这添加索引,优化存储过程。改成分区表之后,效果果然斐然,从1个多钟优化到了一分半钟。可惜啊,好景不长,才过了2天,测试姐姐就把我啦过去看问题,说我的存储过程把整个过程卡住了,700多万的数据,存储过程居然执行了将近4个小时没执行完,我嘴上笑嘻嘻,心里妈卖批。自己挖的坑,含着泪也要把它搞定。
我首先查了下是不是分区表的索引失效了,但经过排查,发现并不是(心中一万头草拟马跑过),然后,我就执行一乐该id下的700多万数据的存储过程,果然很慢,难怪他被卡死了,一查下去发现是select语句查询很慢,奇怪点就在当我用另一个也是拥有700多万的id数据执行存储过程的时候,奇迹发现了,居然3分多钟就完成。
为什么同样是700多万的数据,一个执行了4个多钟还没完成,一个执行了3分多钟就完成了。
抱着疑问,我一步一步排查这个分区表下不同id表有什么区别呢,最终发现执行快的id,在该分区表下global_stats=YES,而另一个的global_stats则=false。
于是我查到了以下的信息
"分区表里global_stats=YES的全局统计信息是否准确关系到optimizer能否选择较优的执行计划,对分区表执行全局统计会不可避免的产生FTS加重系统负担,尤其对于DW环境里规模较大的分区表而言更是如此。"
而global_stats这个代表该分区表是否对该分区进行了统计分析,一般情况下,系统在不知道什么时候都会对这分区就行统计分析的。而对这个分区进行统计分析又包含了两种方式,非incremental方式,incremental方式,而非incremental方式会进行全量扫描分区表中所有的分区,incremental方式则会增量扫描分区表中的分区。
incremental statistics collect正是在这一背景下应运而生,简单的说incremental statistics collect会实时记录分区表里每个partition每列值的更新情况,这一信息保存在SYSAUX表空间里,后续根据这一信息在执行全局统计时仅会针对有变化的partition进行statistics collect,并将收集的结果与没有变化过的partition原有的统计信息进行整合,计算出准确的global stats,省去了必须去扫描每一个partition的步骤。
非incremental方式下新加分区后对整个分区表收集统计信息,会全量扫描分区表中所有的分区,即使那些没有改变过的分区也会被重新扫描一遍
//查看分区表下有多少个分区
select table_name,count(*) from dba_tab_partitions group by table_name order by 2 desc;
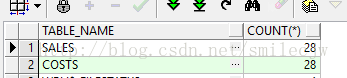
//查看该表统计偏好
select dbms_stats.get_prefs('granularity','system','SALES') from dual;
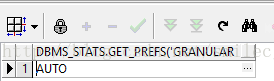
//查看分析后global与partition级的统计信息
select num_rows,blocks,last_analyzed from dba_tables where table_name='SALES';
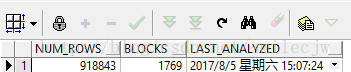
//重新收集global统计
exec DBMS_STATS.gather_table_stats(ownname=>'SYSTEM',tabname => 'SALES');















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









