







前言
最近在系统的实战spring cloud,在学习nacos过程,我们知道nacos的底层用到了Raft协议。
在Raft协议之前是一个paxos的协议,但是这个协议有点复杂,于是Stanford的两位教授决定设计一种较简单的一致性算法。
参考自Raft动态演示网站 我们一起来学习一下Raft协议。
Raft前置概念
term:任期,比如新的领导选举时,例如配置初始化或者leader宕机后新的领导选举
大多数原则:假设一个集群有N个节点。那么大多数就是(N/2)+1;例如一个N= 3的集群,里面的大多数就(3/2)+1 =2.
状态:每个节点有三个状态,且每个时刻只能是3个状态中的一种。
- Follwer 追随者
- Candidate 候选人
- Leader 领导者
理解Raft协议 选主/赋值
Leader选举
假设我们有个系统,这个系统是个单节点系统,是一个数据库的server,现在假设我们要传某个值X到该节点,目前这个节点的一致性很简单,就是传什么就存什么,因为这个节点也不需要和其他人协商。
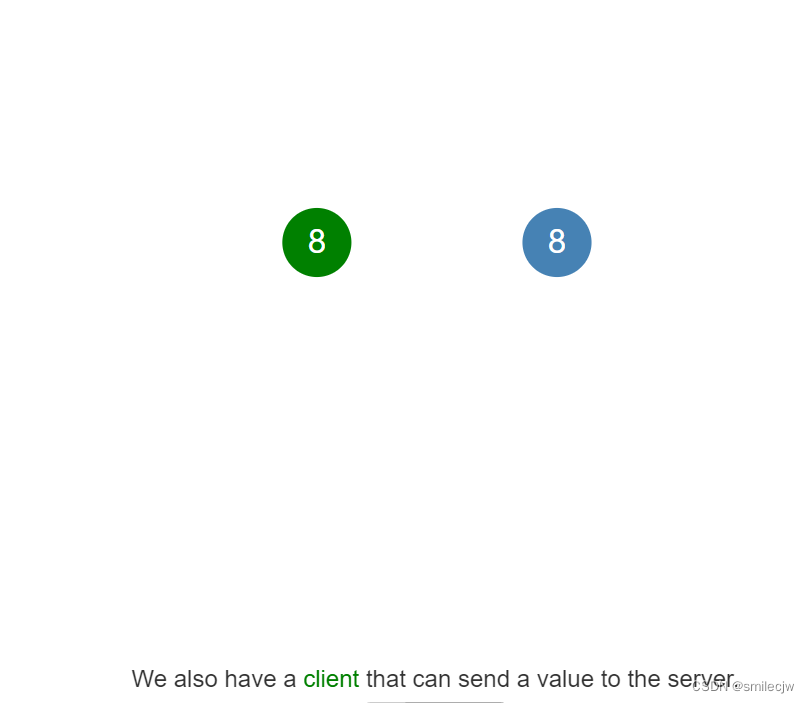
但是如果我们有多个节点,一致性又该如何去处理呢?

由此引出Raft,Raft是一个实现分布式一致性的协议。
在Raft协议里面,一个成员节点有三个状态
- Follwer 追随者
- Candidate 候选人
- Leader 领导者
作为一个Follwer,需要不停的接收Leader的指令或心跳包,如果Follwer没有收到Leader的指令就会转变成一个Candidate

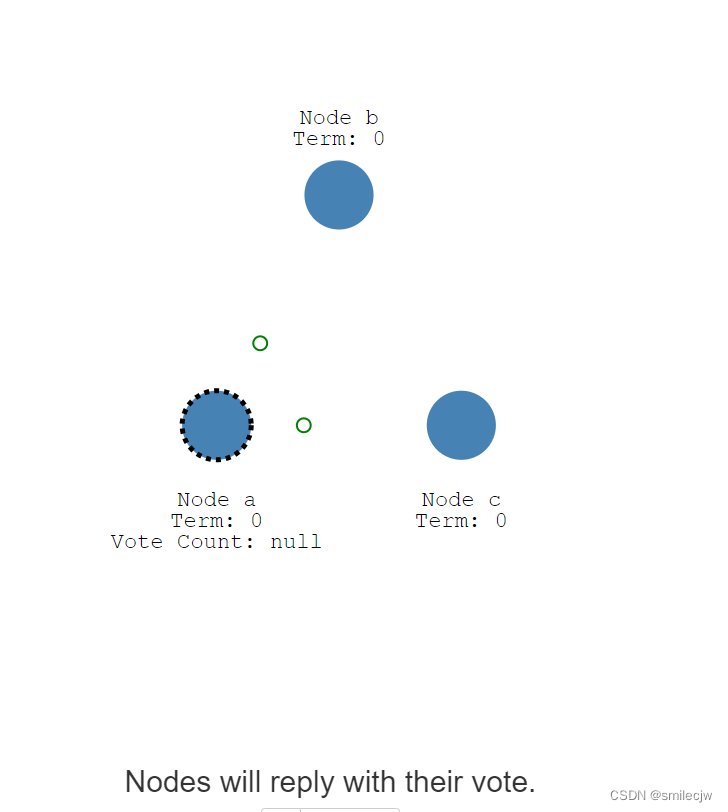
当节点变成一个candidate之后,它就会跃跃欲试,尝试想成为一个Leader,于是乎发起了自身想成为领导的投票,请给我投票

在这里,如果其他candidate还没投过票,那么他们就会自动投票
然后可以看到Node a 因为接收另外两个节点的返回,且是大多数的返回,于是Node a就成为了Leader.
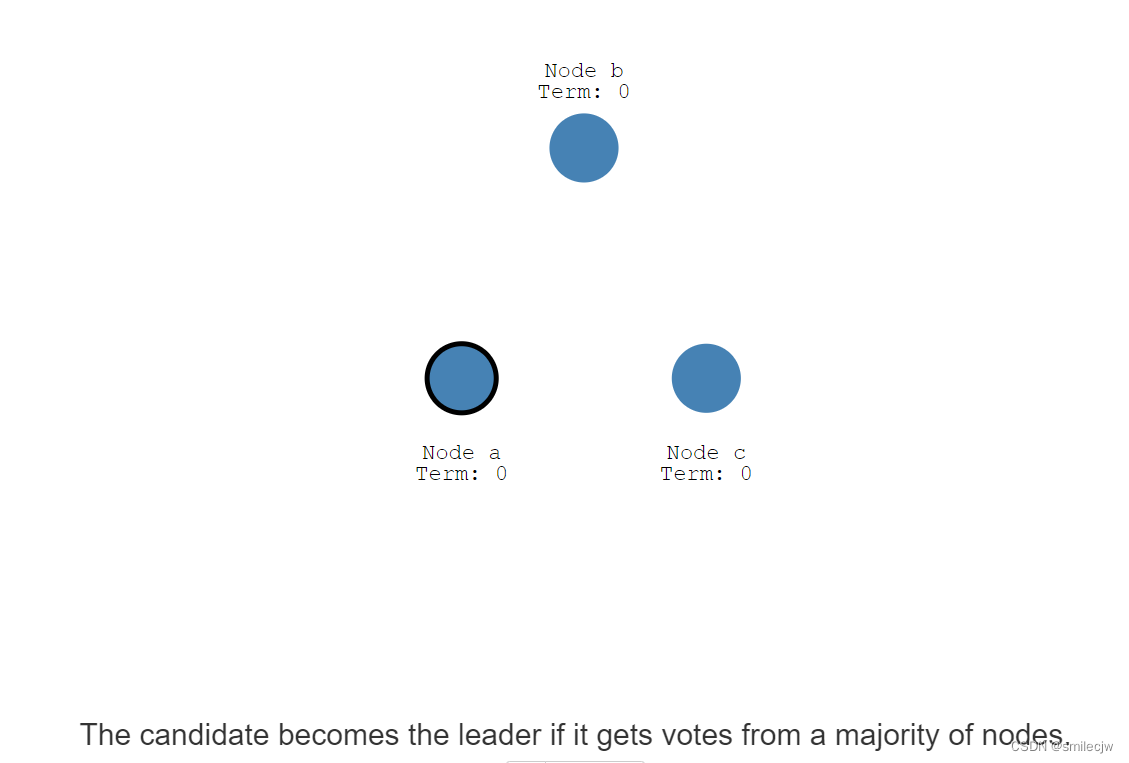
这个过程就叫选主。
经过选主之后,现在系统的所有改动都会经过leader节点。
日志复制(Log Replication)
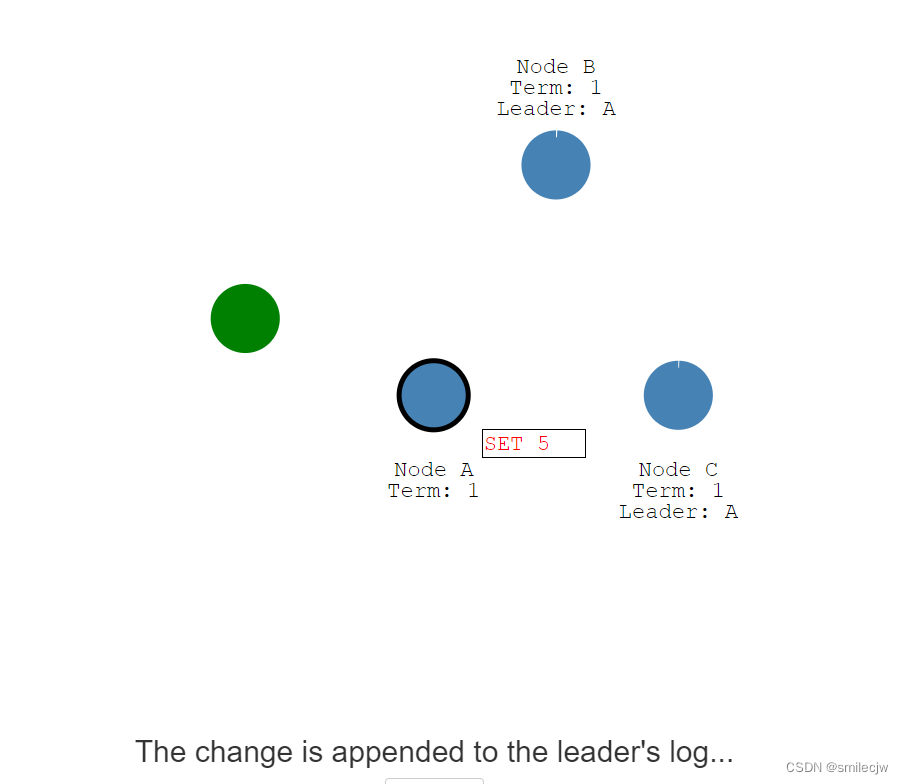
现在我们有一个客户端要写入一个5,每一个写入都是作为一个Entry写入到leader节点Log日志,我们可以看到set 5为标红,为 目前还没提交的状态,因此这个值并不会更新到这个节点的值里面去。
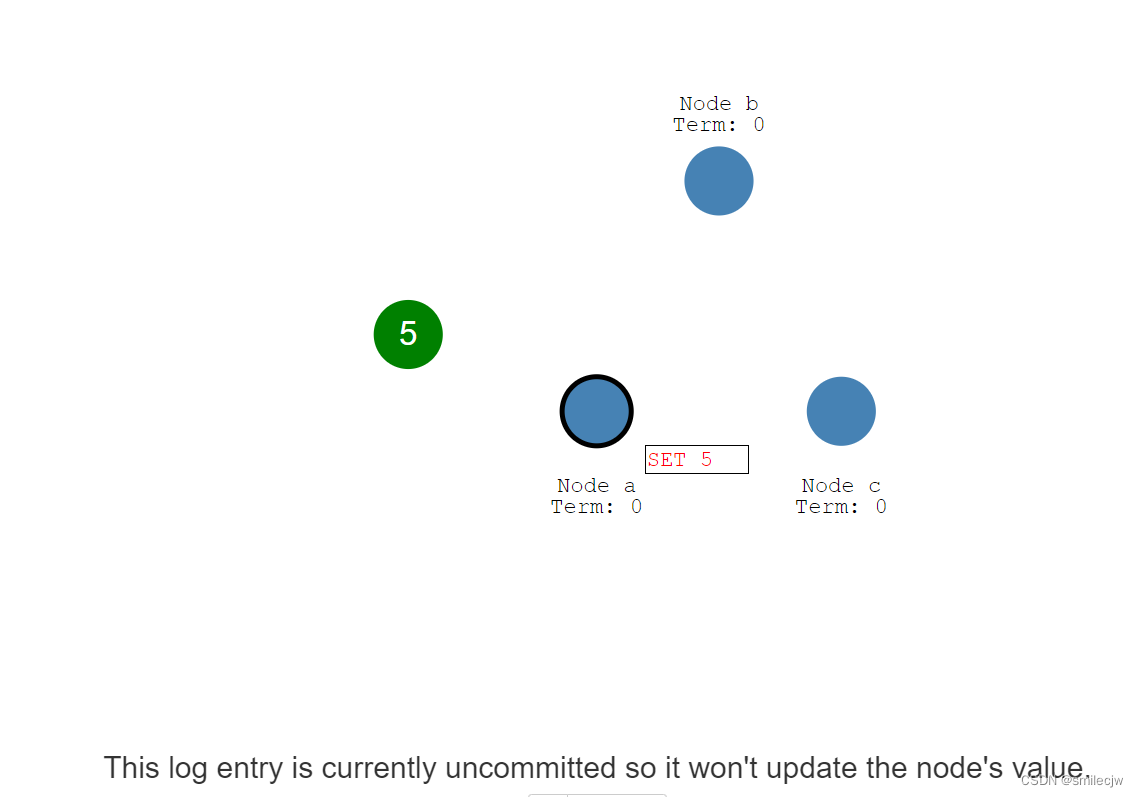
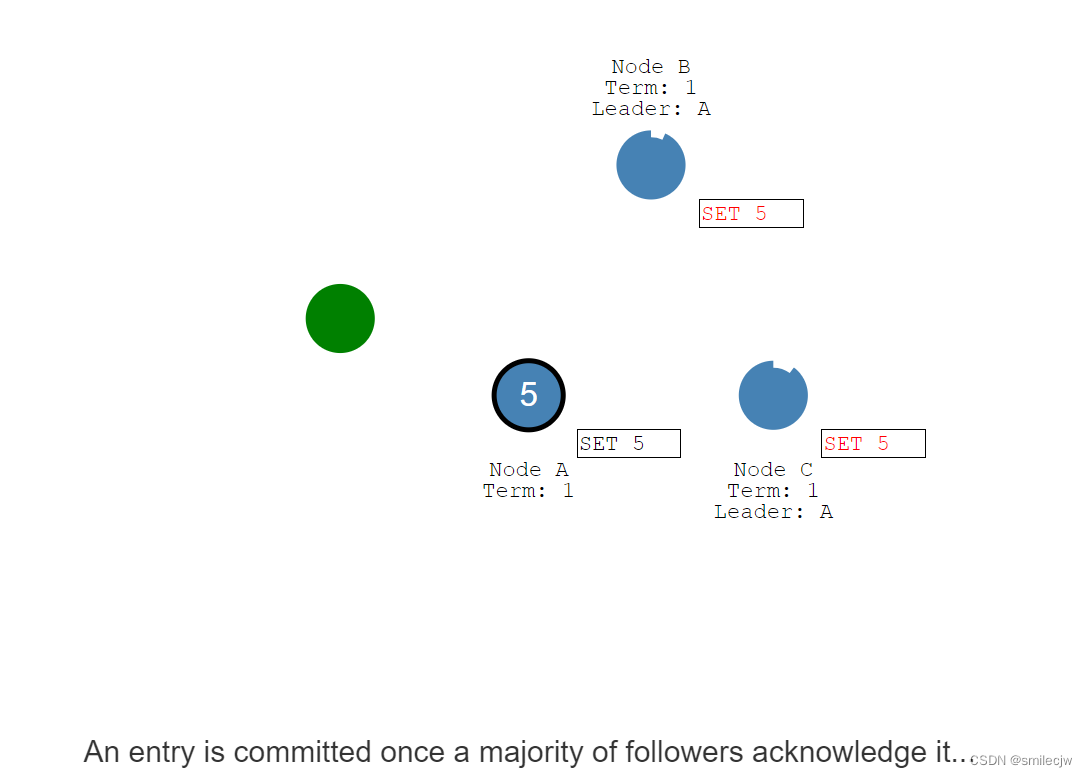
为了提交这个entry,leader节点首先把这个entry复制到其他的follwer上,然后等到大数据的follwer节点回复我已确认收到,但是注意此时其他的follwer上,这个5的entry日志仍是未提交的状态。
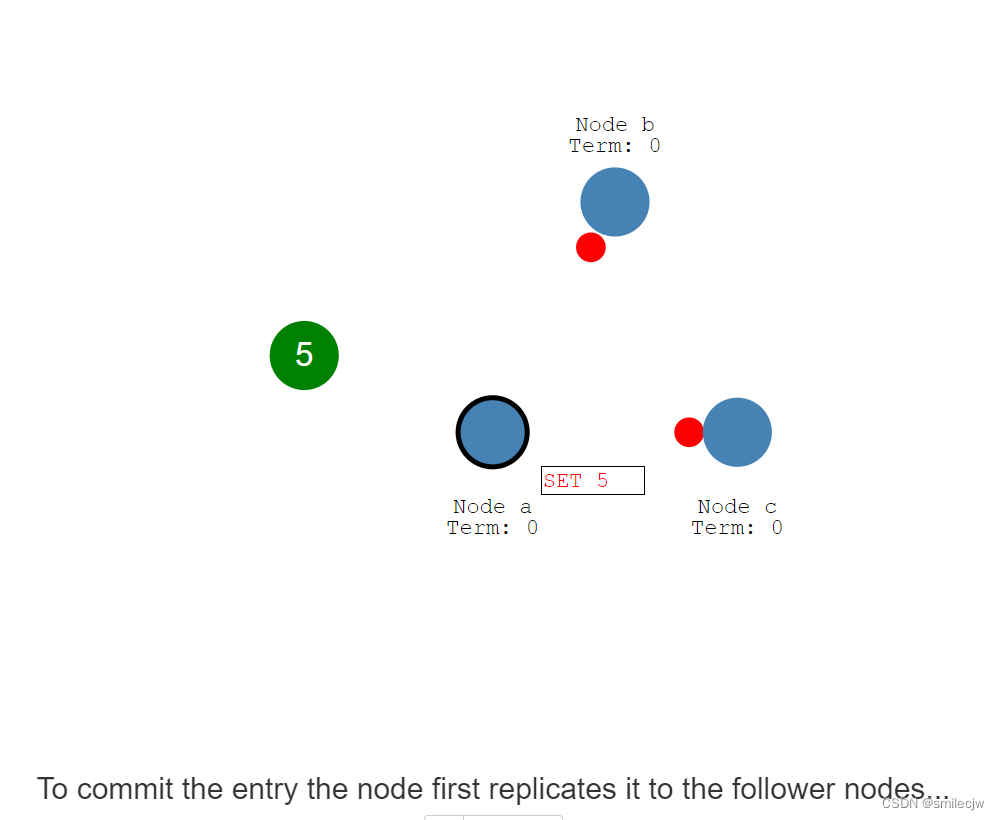
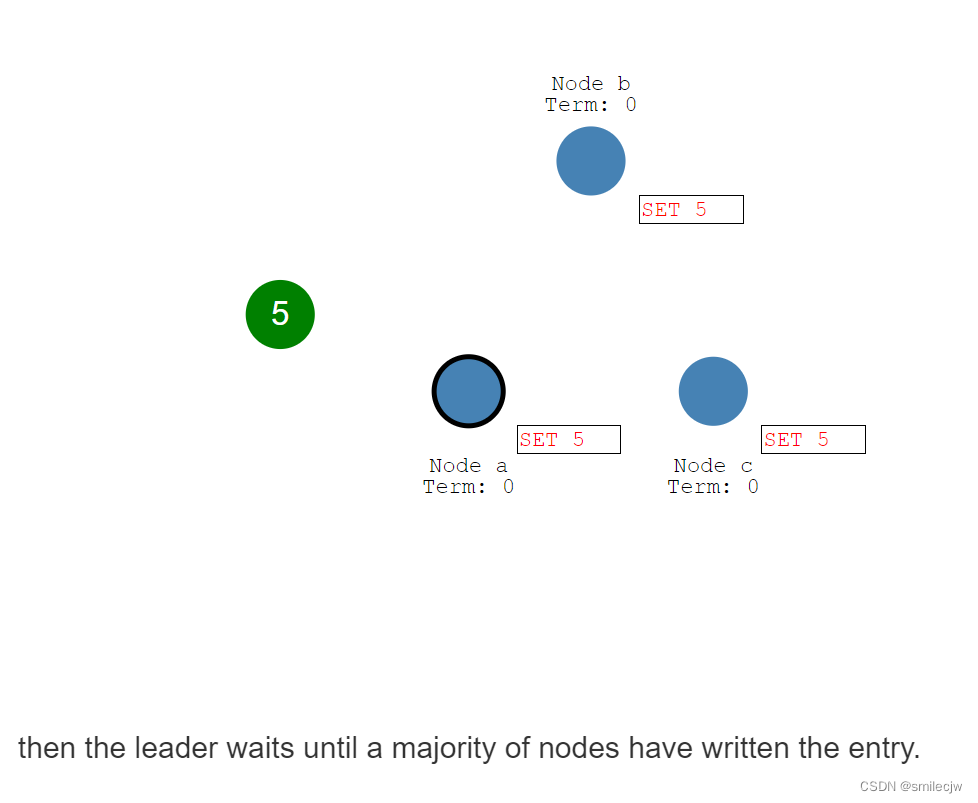
此时leader收到了大多数的回复已收到,这时Leader就commit 5这个entry日志,
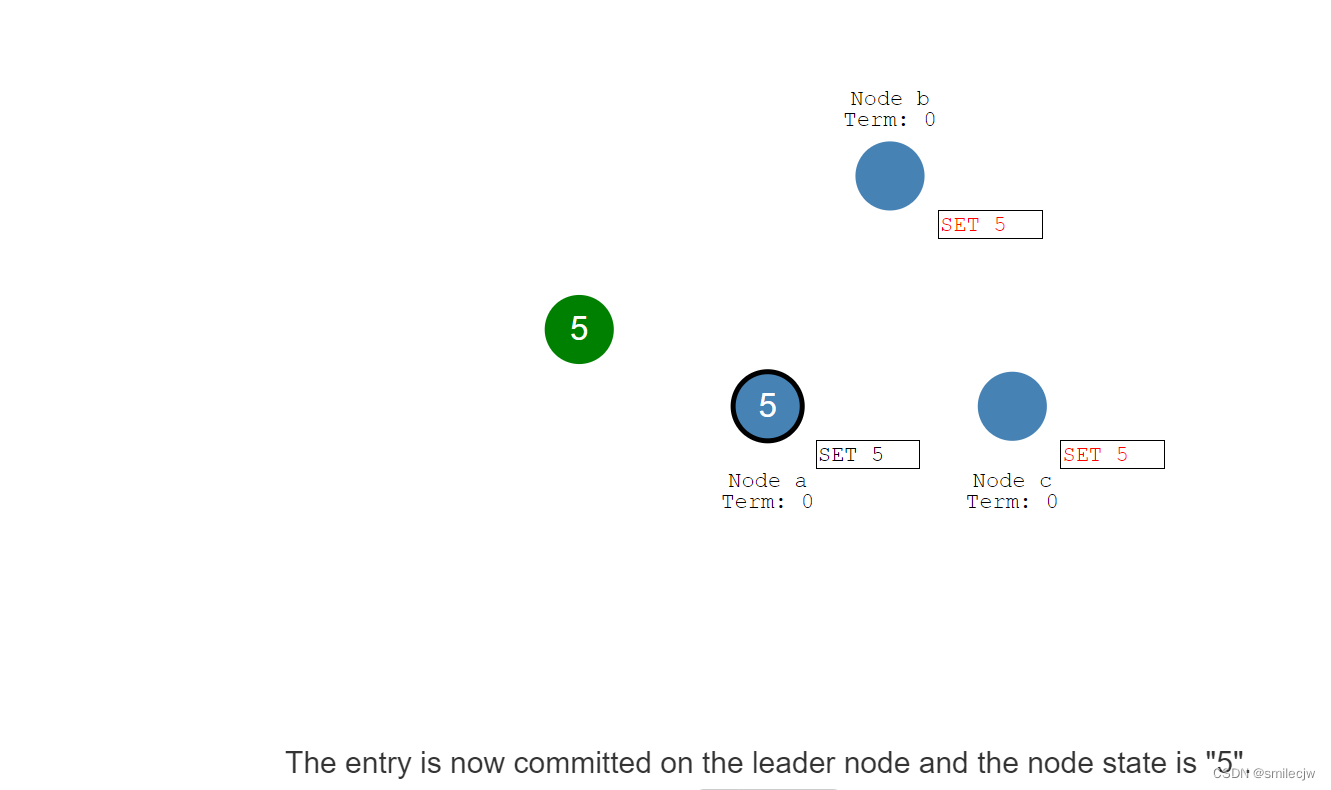
leader commit了这个entry日志,随后通知其余follwer告诉这个entry已处于commited状态,于是follwer将自身的netry设置成committed状态(已提交状态)。现在,集群终于处于分布式一致性状态了
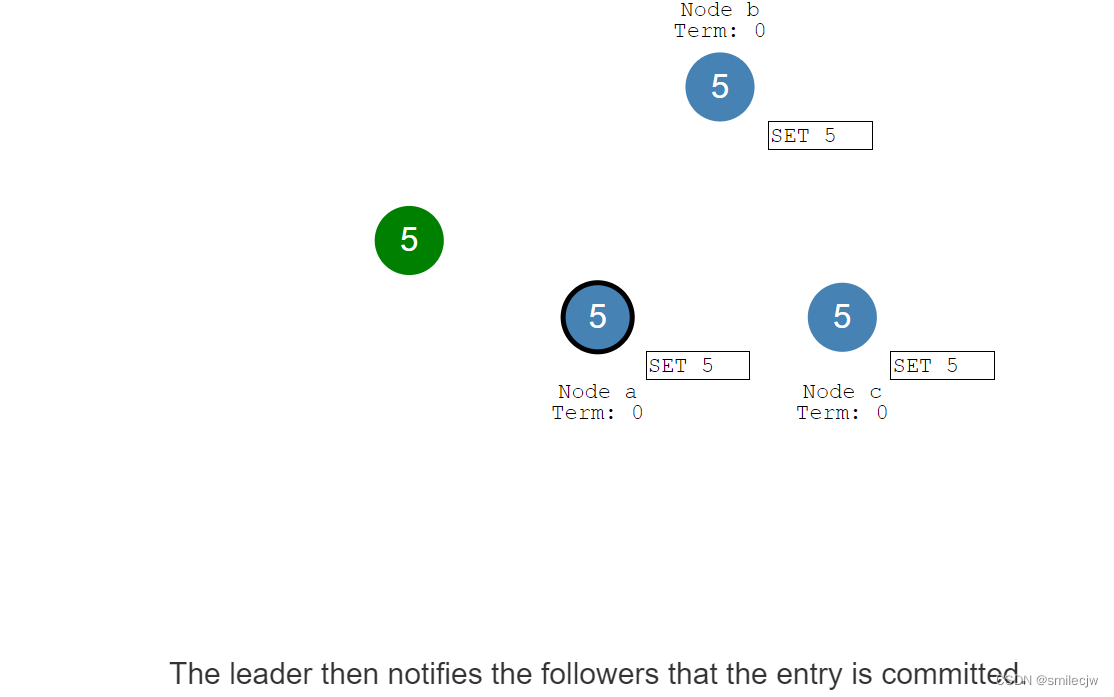
这个过程就叫做日志复制
Leader Election
选举超时时间(election timeout)
在Raft协议里面有两个超时设置。一个叫选举超时时间(election timeout),选举超时时间是follwer转为candidate的超时时间。
选举超时时间是一个150ms到300ms的随机超时时间,在一个多节点集群中,每个节点都有自己的随机的选举超时,可以想象的是选举超时时间最短的节点,最容易从follwer转为candidate,结合上文,就有可能最快发起选举投票,从而变成leader.
在选举超时时间后,可见Node c,最先从follwer转变为candidate从而向其他节点发起选举投票。

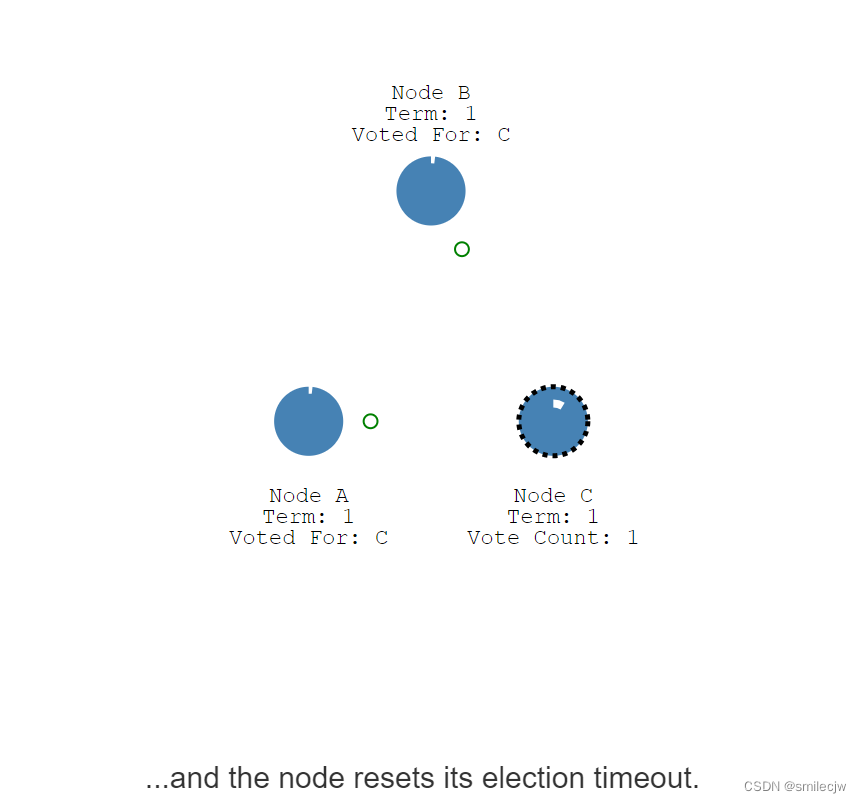
如果接收的节点还没投票的话,就会把票投给发起投票的candidate,并且重置其自身的选举超时时间。

一旦一个candidate(候选人)收到了大数据的投票,它就会变成领导人。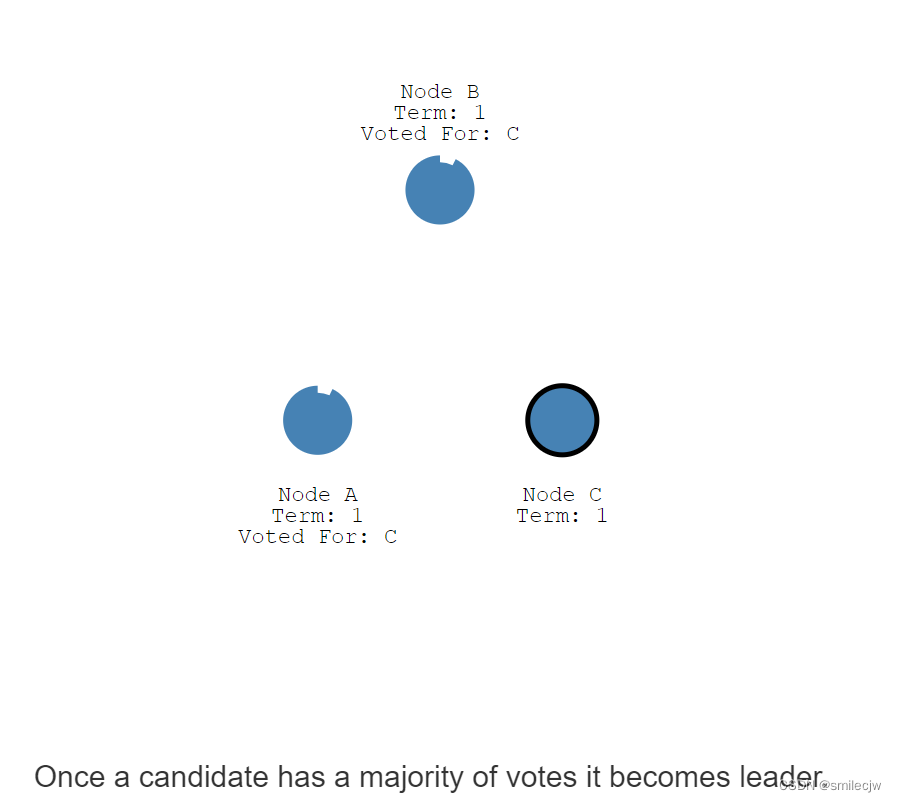
随后leader就开始向follwer发送附加的entry消息。
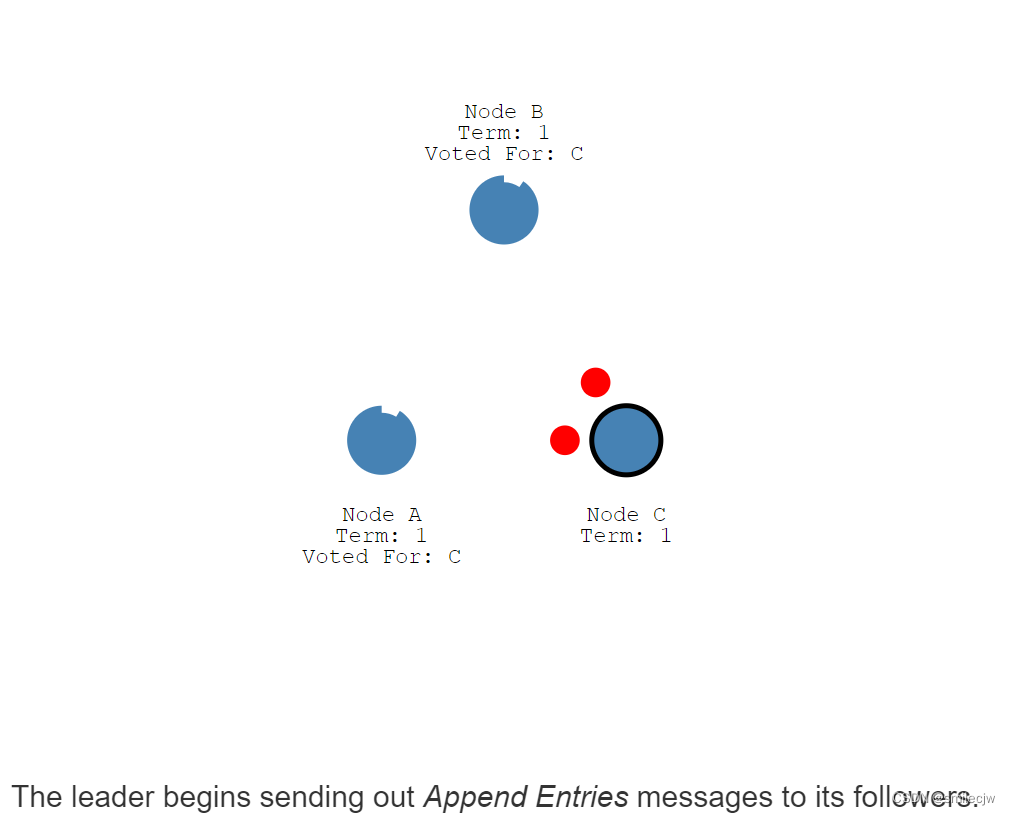
心跳超时时间(heartbeat timeout)
这些消息通过心跳超时时间(heartbeat timeout)间隔的发送
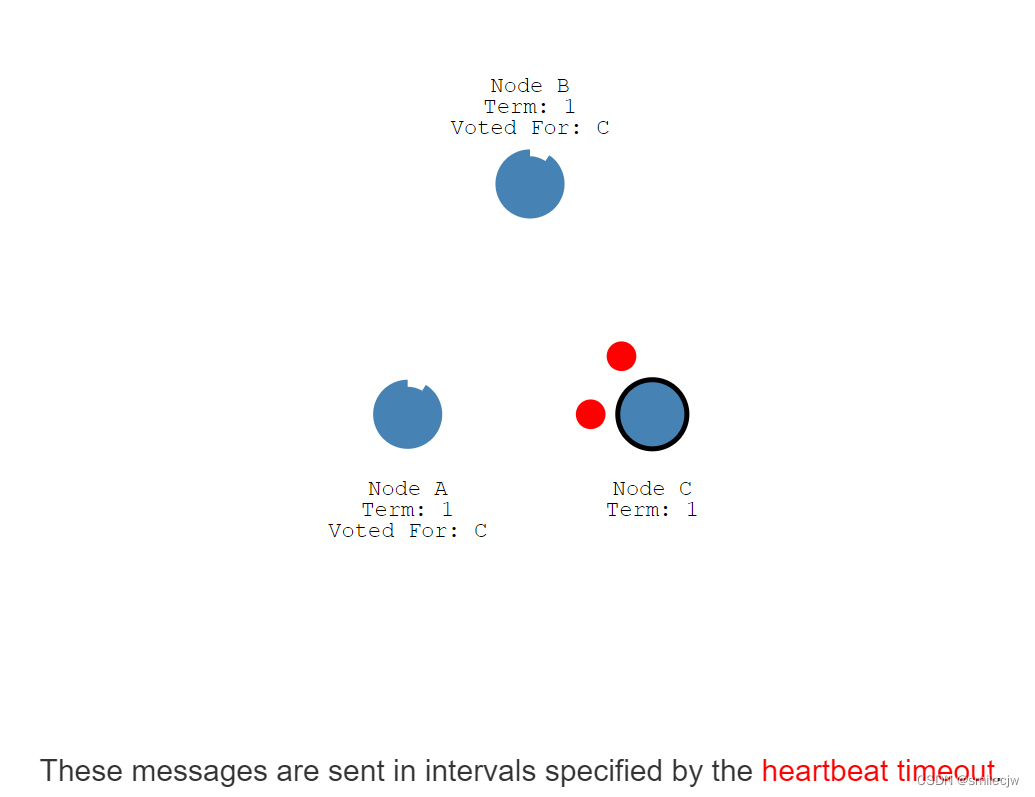
然后follwer们会回复每条消息并重置每个follwer的election timeout时间,这样,leader就能通过心跳一直保证leader的地位。
re-election(重新选举)
但是如果leader停止了,又是如何去重新选举的呢?
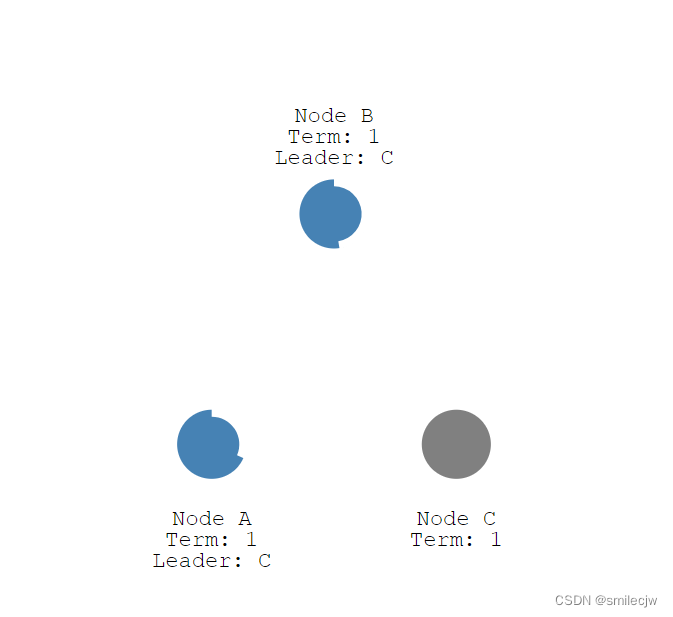
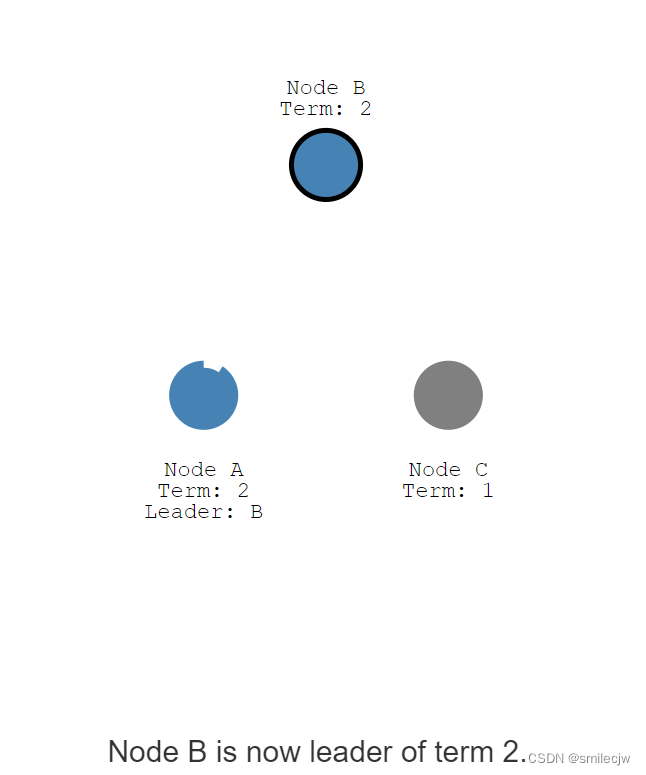
此刻不管Node c是因为宕机,还是网络中断了,因为没有心跳了,此刻Node b因为election timeout 从follwer转为变candidate,因为现在只剩B 和A 了,发消息给A就得到A的投票,B便成为了leader.
election conflict(投票分裂)
如果两个节点同时成为candidate就有可能发生投票分裂。
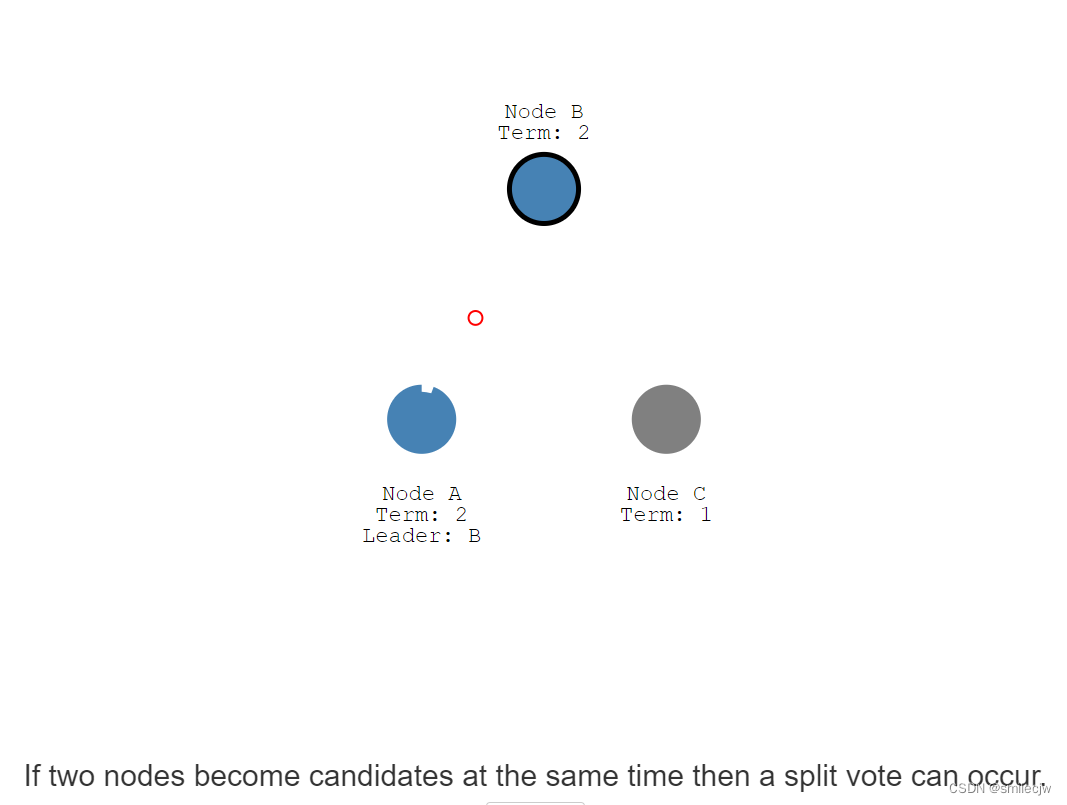
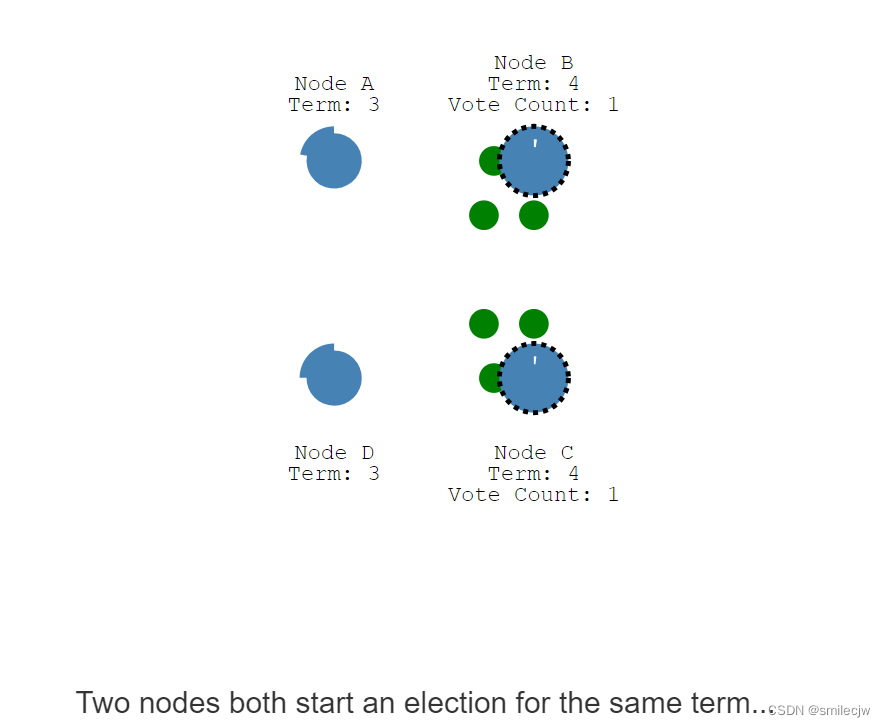
接下来,让我们看一下4个节点投票分裂的例子。两个节点在同一个任期内,同时开启选举投票。且都分别发送先发送到投票其中一个节点。
即Node B 先到的Node D ,所以Node D投票给B;Node C 先到的Node A,所以Node A投票给Node C。
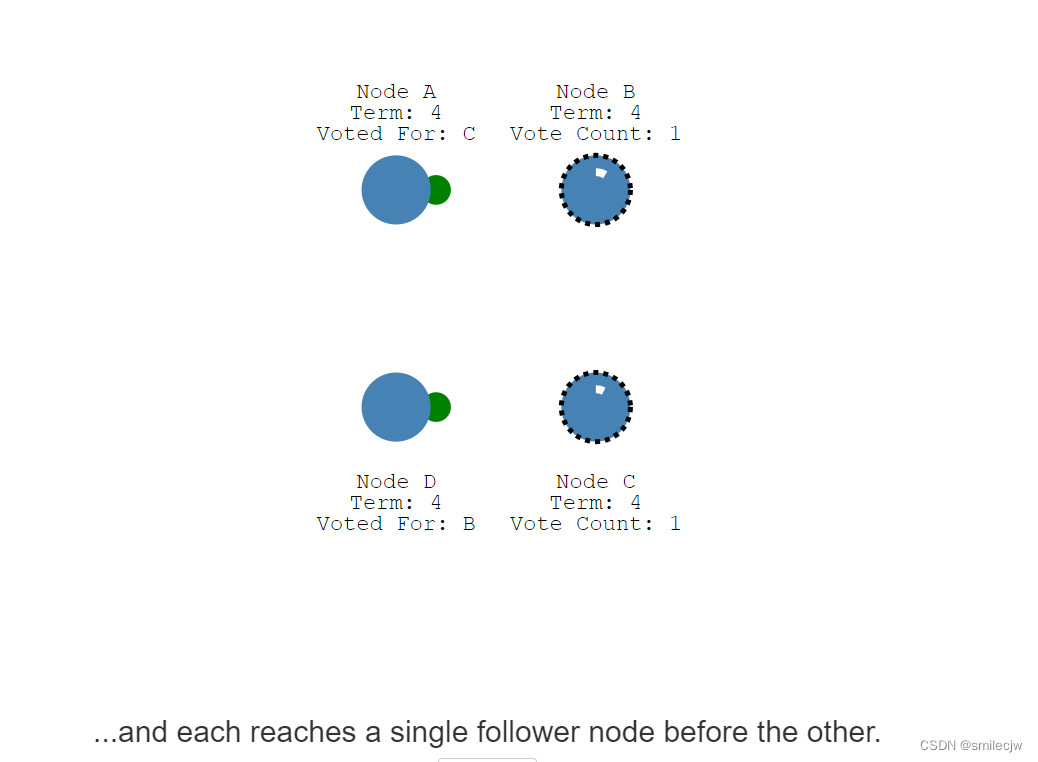 所以此刻Node B 和Node C 都各有两票,这种情况投票就是无效,这里就又重新开始等待election timeout,然后重新开始新一轮选举,直到一个新的node 收到了大多数的投票。
所以此刻Node B 和Node C 都各有两票,这种情况投票就是无效,这里就又重新开始等待election timeout,然后重新开始新一轮选举,直到一个新的node 收到了大多数的投票。


Log Replication
一旦我们有了一个选举出来的leader,我们需要复制所有变化到所有的节点。

这个复制是靠心跳的附加entry来完成的。
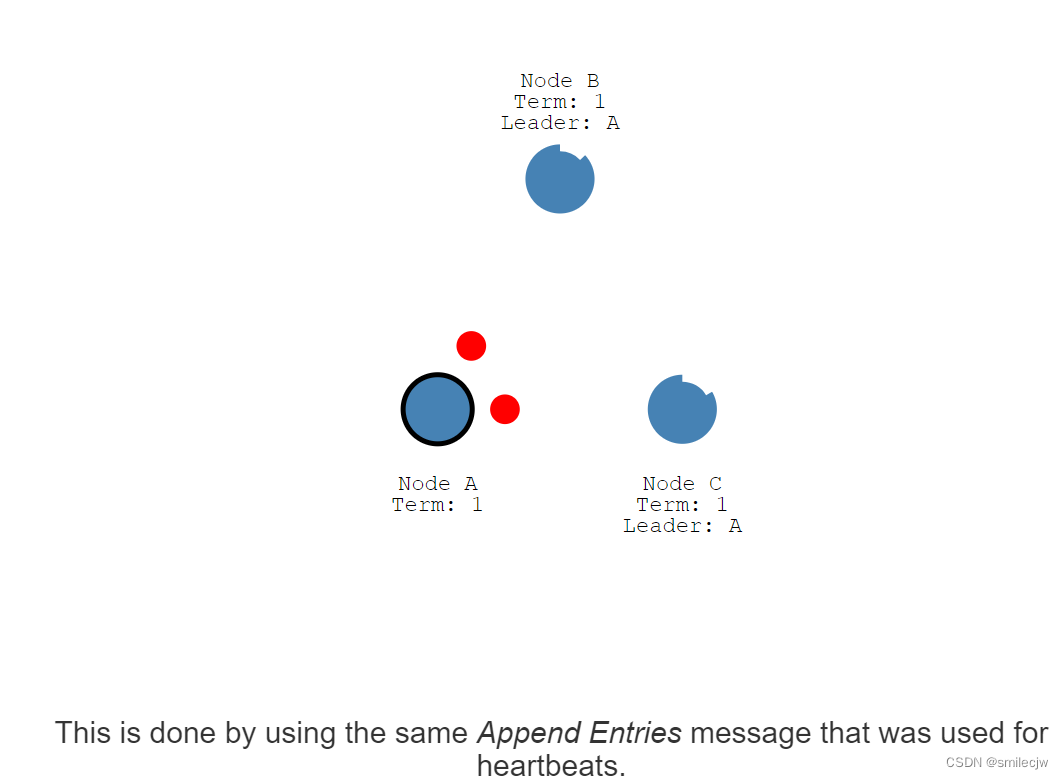
这个设置value为5的消息被添加到了leader的log日志里面去
同时这个改变也会通过下次心跳发送到follwer们去

一旦这个entry被大多数的follwer们回复知道了,这个entry消息便会在leader的日志中提交成committed状态。
这个时候leader就会告诉client(客户端)我已经写入了。
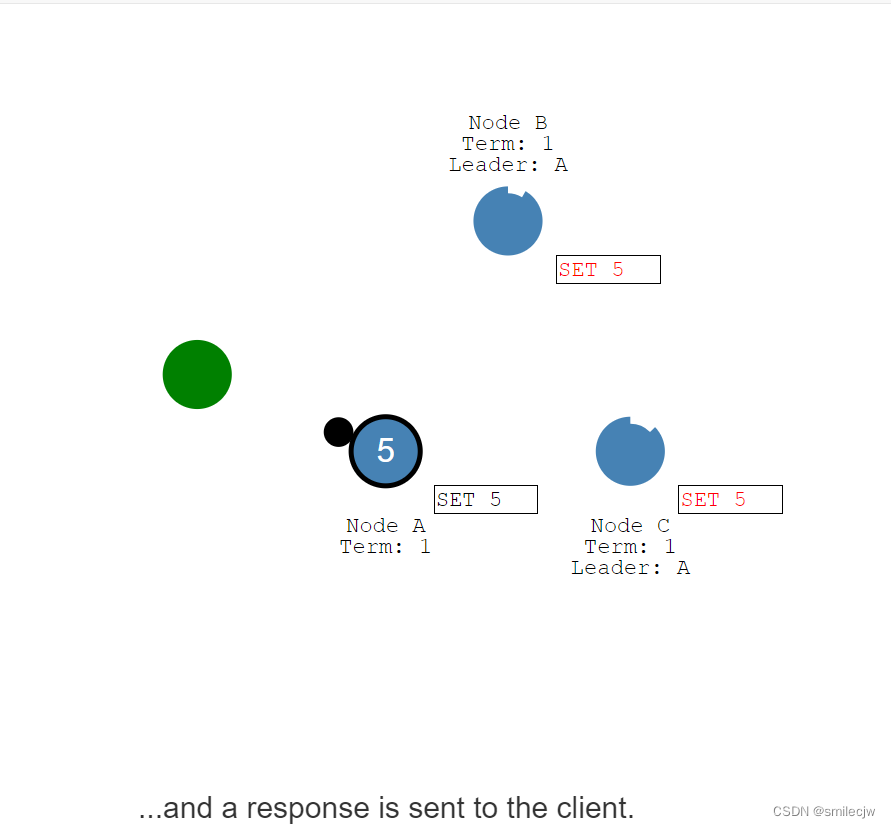
随后leader就会在下一次指令中告诉其他follwer置为committed状态
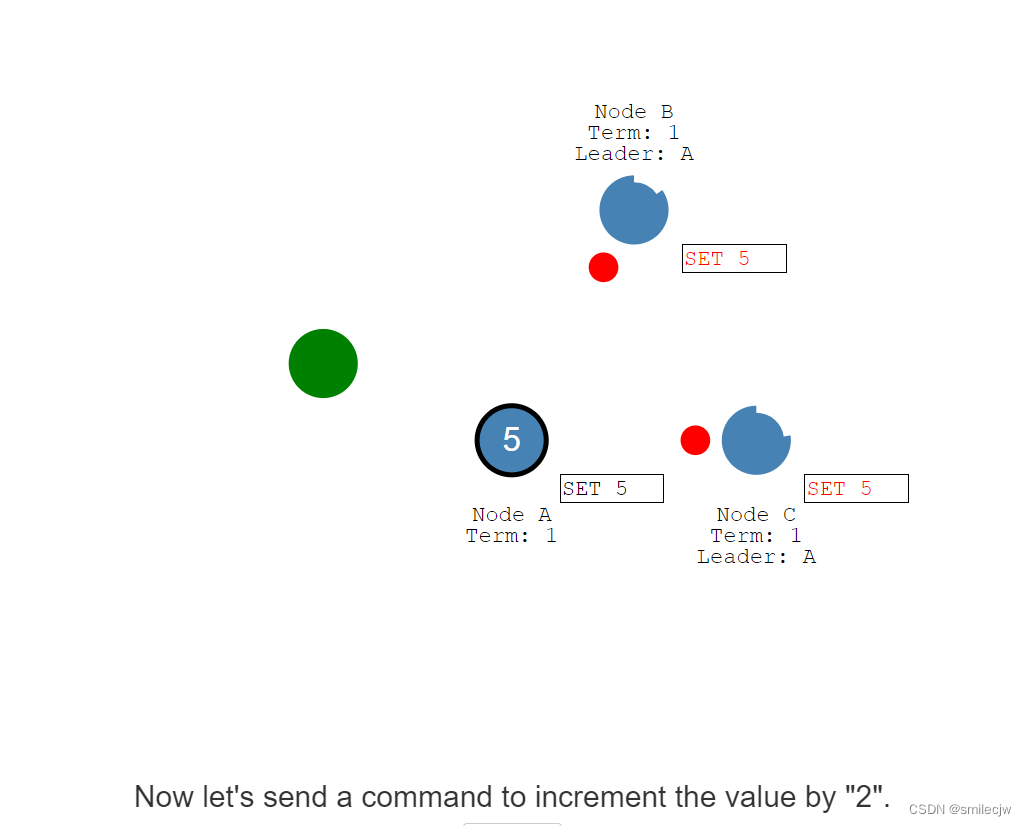
脑裂-网络分区(network partitions)
第一步,让我们先添加A,B,C,D,E5个节点。可以看到此刻Node B通过选举之后他的任期为1,且在选举之后,Leader Node B 也会不停在heartbeat timeout后发送log到各节点A,C,D,E;A,C,D,E接收到包含entry的log日志又会不停的重置其自身的election timeout.按照目前场景,Node B会一直保持leader地位。
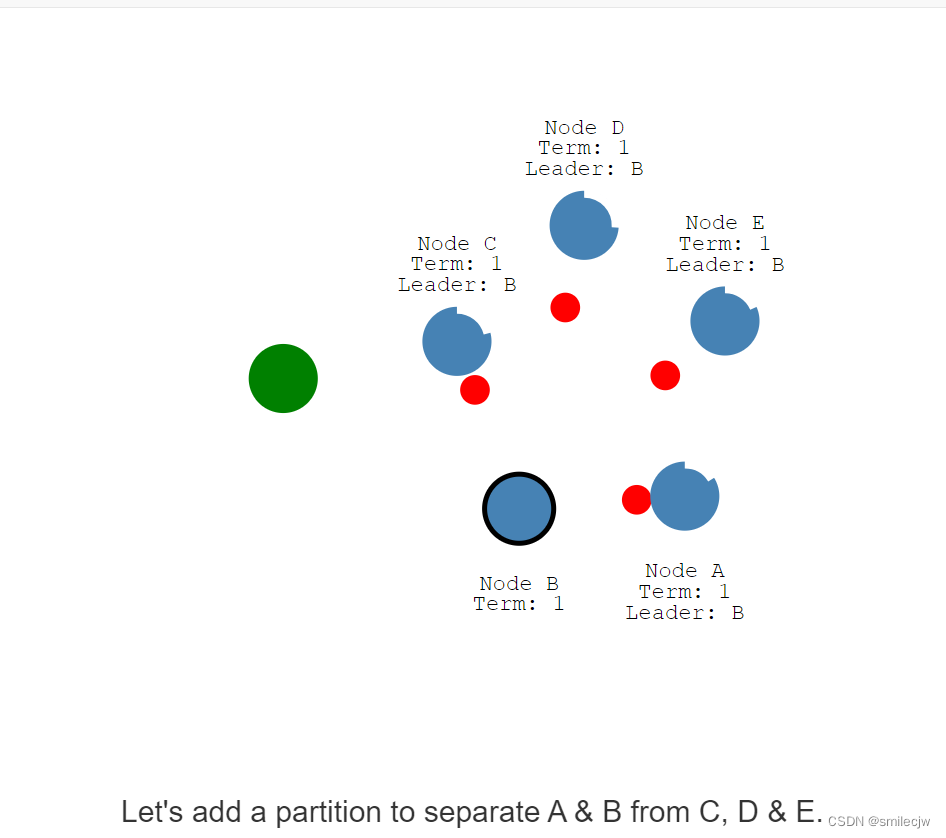
现在让我们A,B和C,D,E之间加入分区

现在因为我们的分区,我们现在会有两个leader,且两个leader在不同的任期里面
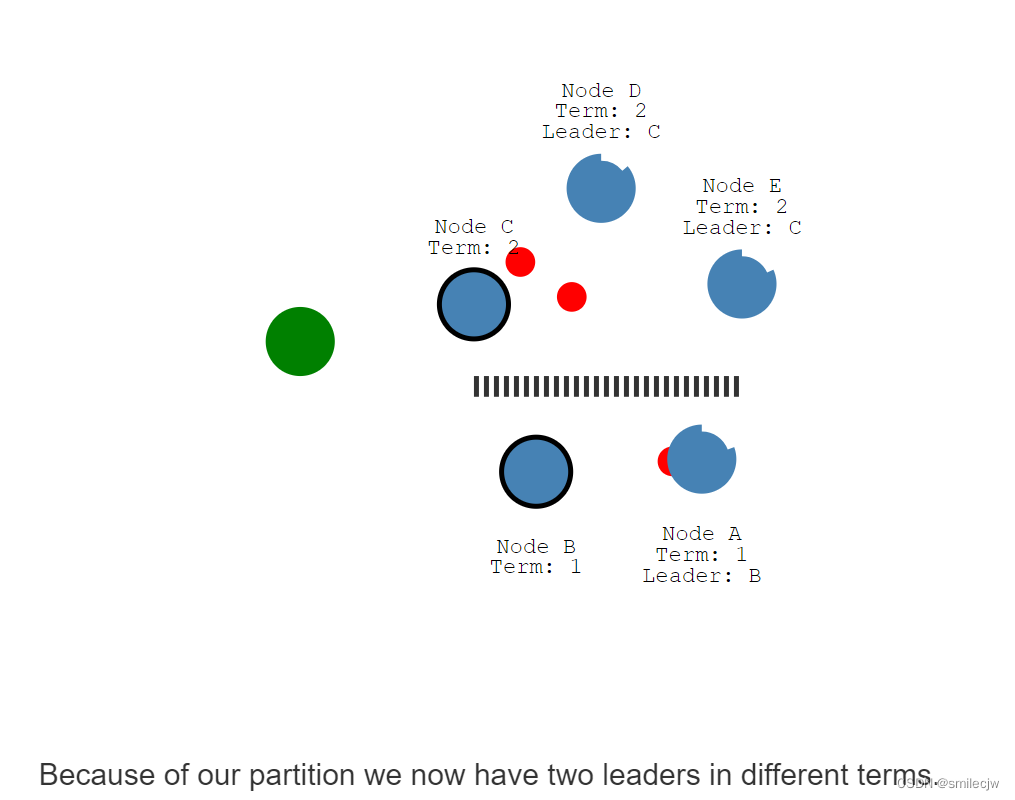
现在假设我们添加多一个客户端尝试去更新两个leader的值
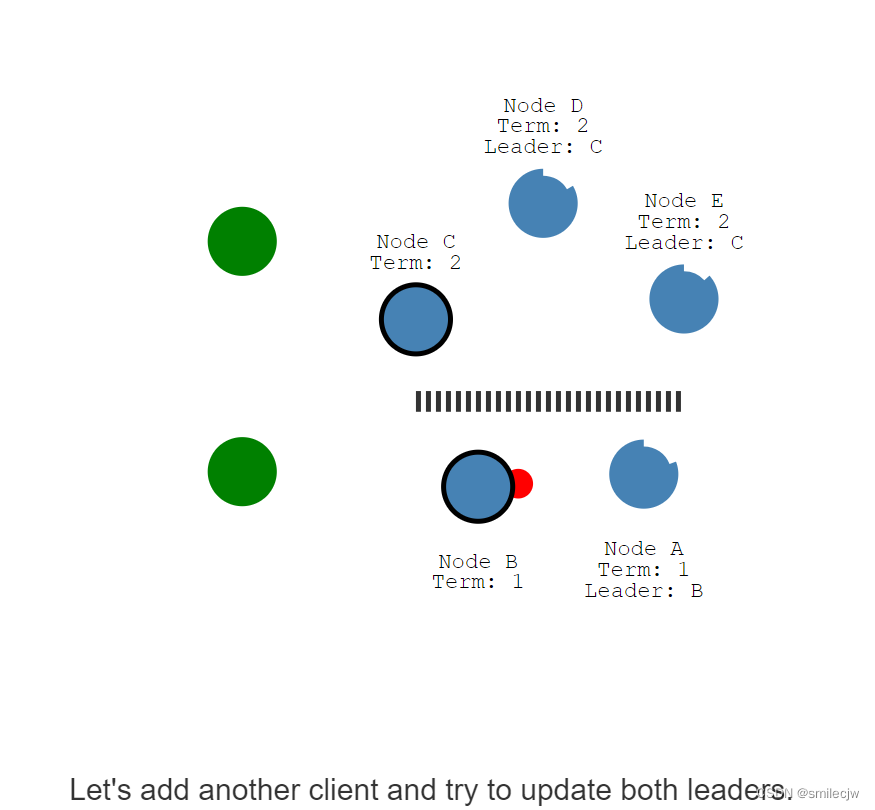
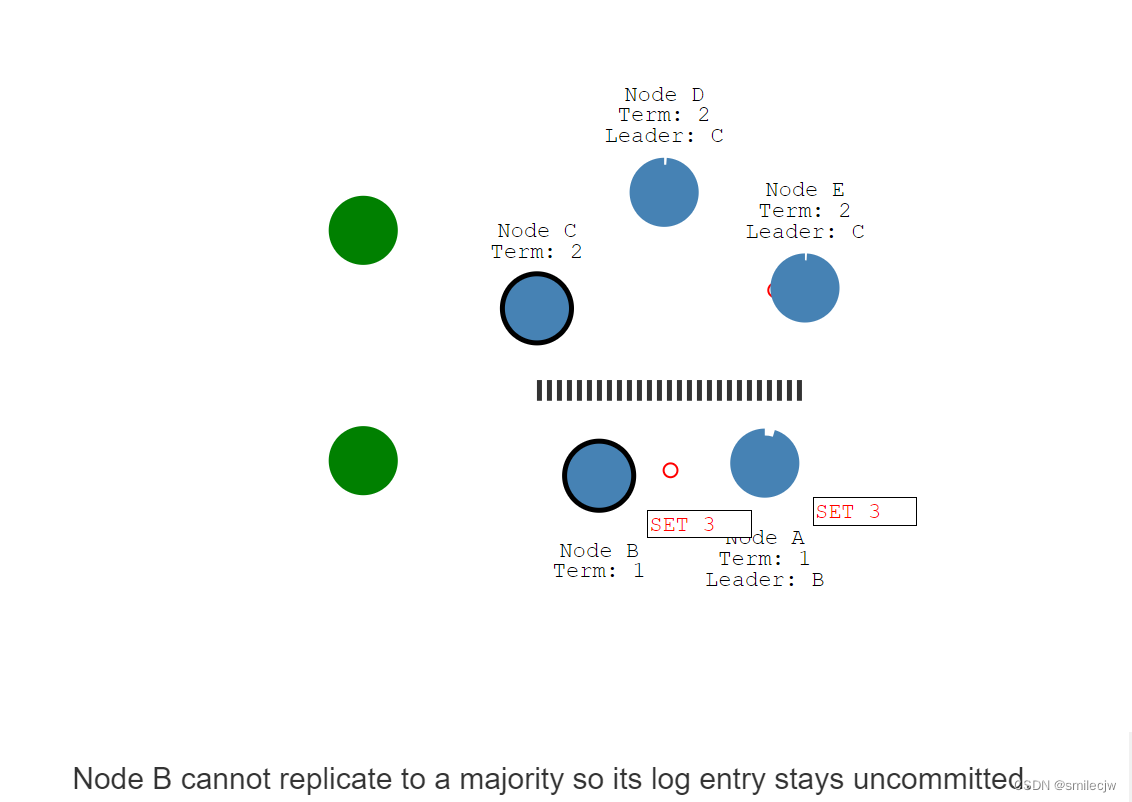
现在其中一个客户端开始尝试给Node B赋值3.
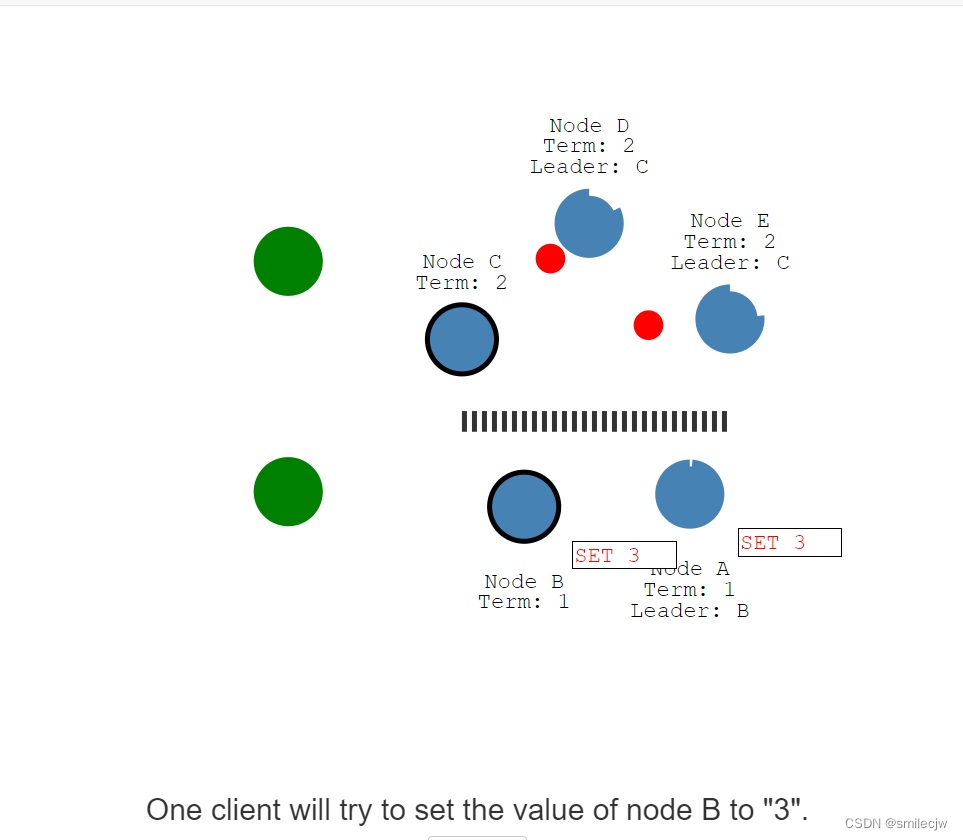
但是Node B获取不到大多数的回复,会导致这个entry 日志保持在uncommitted的状态。
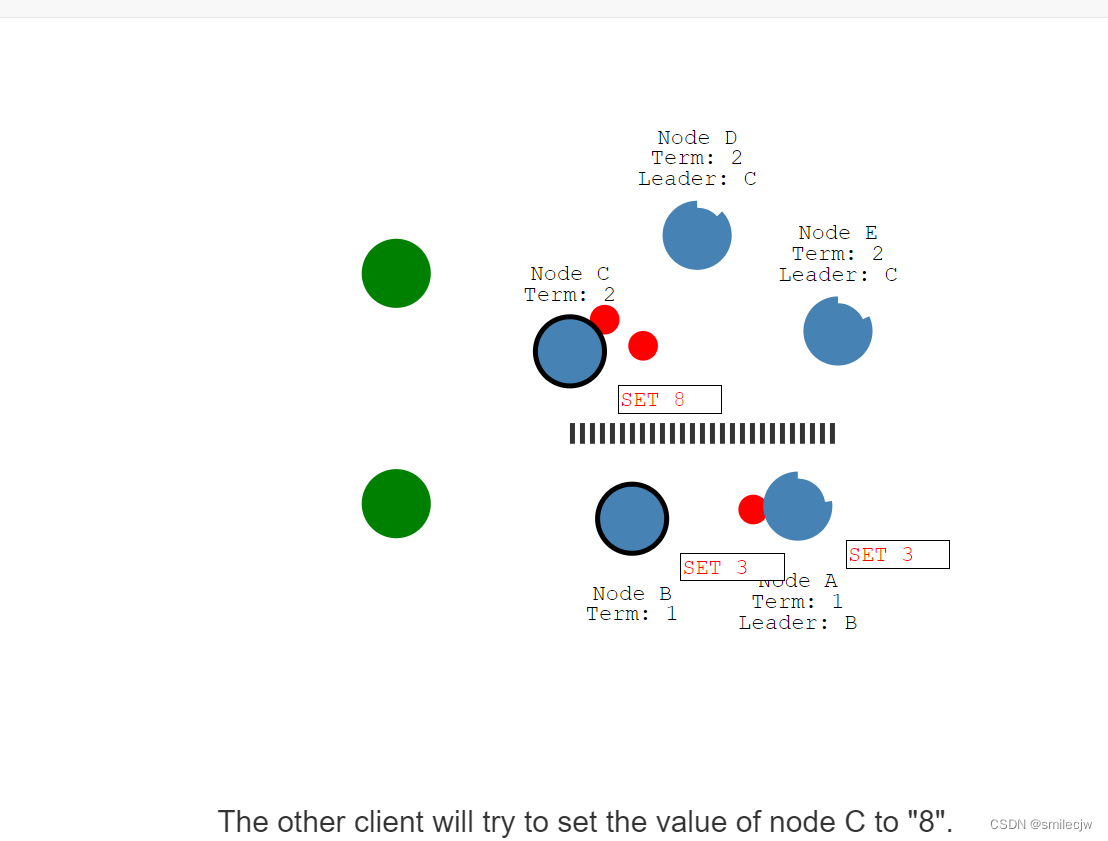
而此时另一个客户端给leader Node C赋值8,此时Node C会在下一次heartbeat操作中把entry 日志set 8发送给Node D,Node E。Node D,和Node E收到后回复我知道了告诉Node C.Node C将回复客户端已写入,并在下次的heartbeat中通知到Node D,Node E提交日志。在这次里面Node C终于写入了8的值。
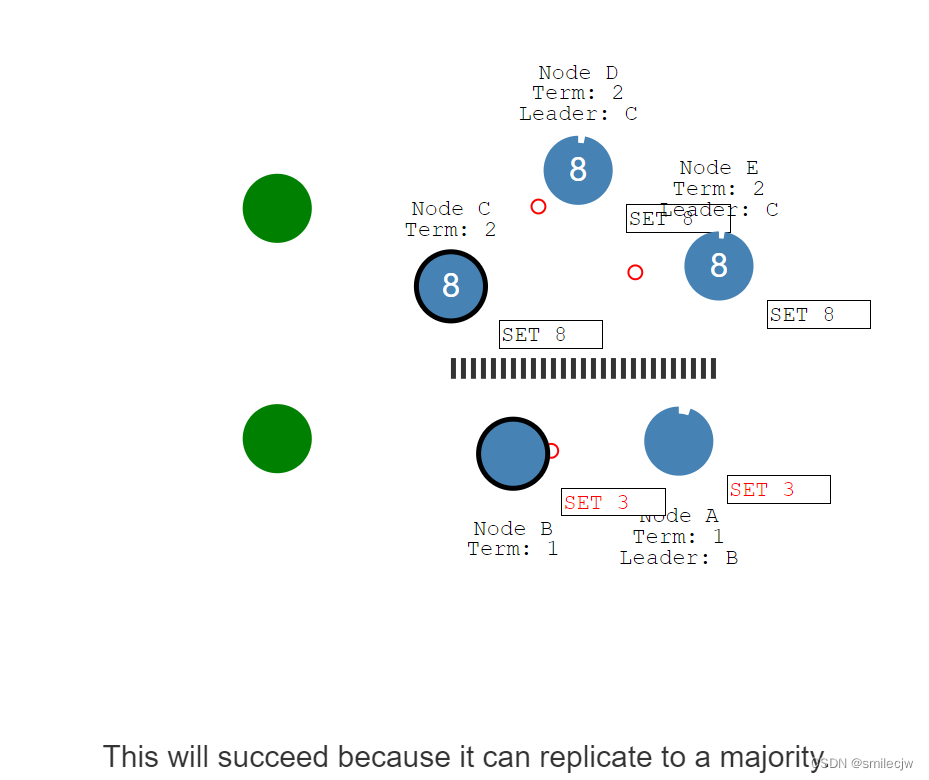
现在让我们修复这个网络分区看看会发生什么
网络修复,Node B就会在集群中看到任期更高的Leader Node C,随后Node B就会停止任期。NodeA 和Node B回滚未提交日志并接收Node C的日志信息,随后和Node C的日志内容同步。
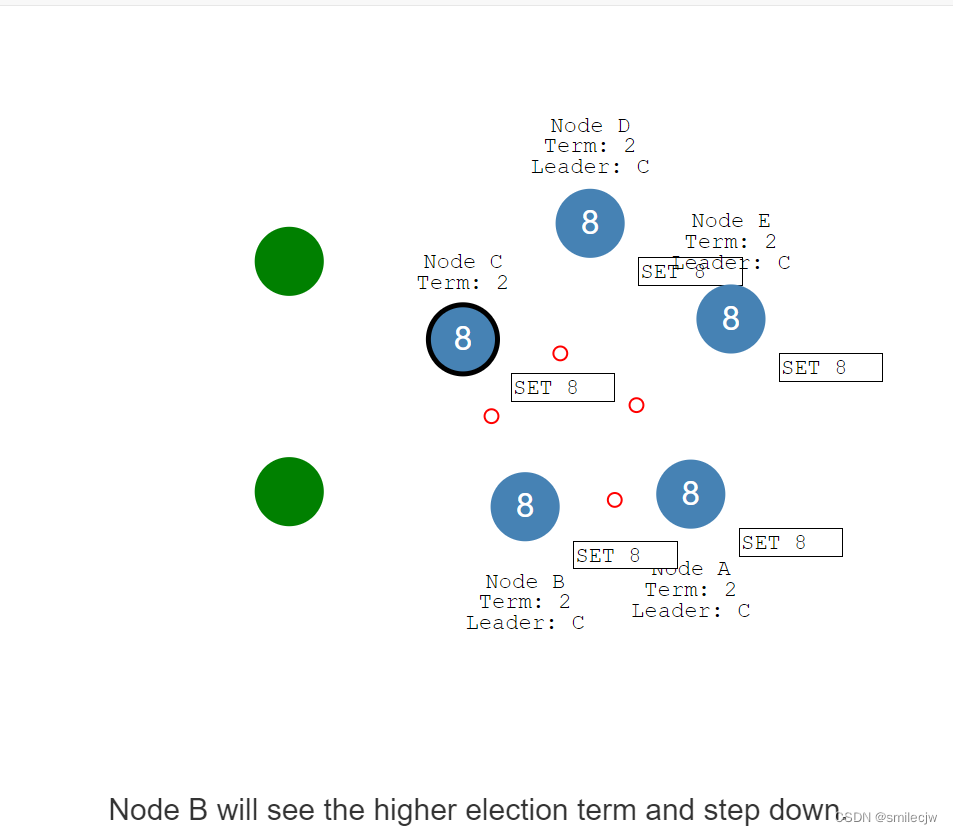
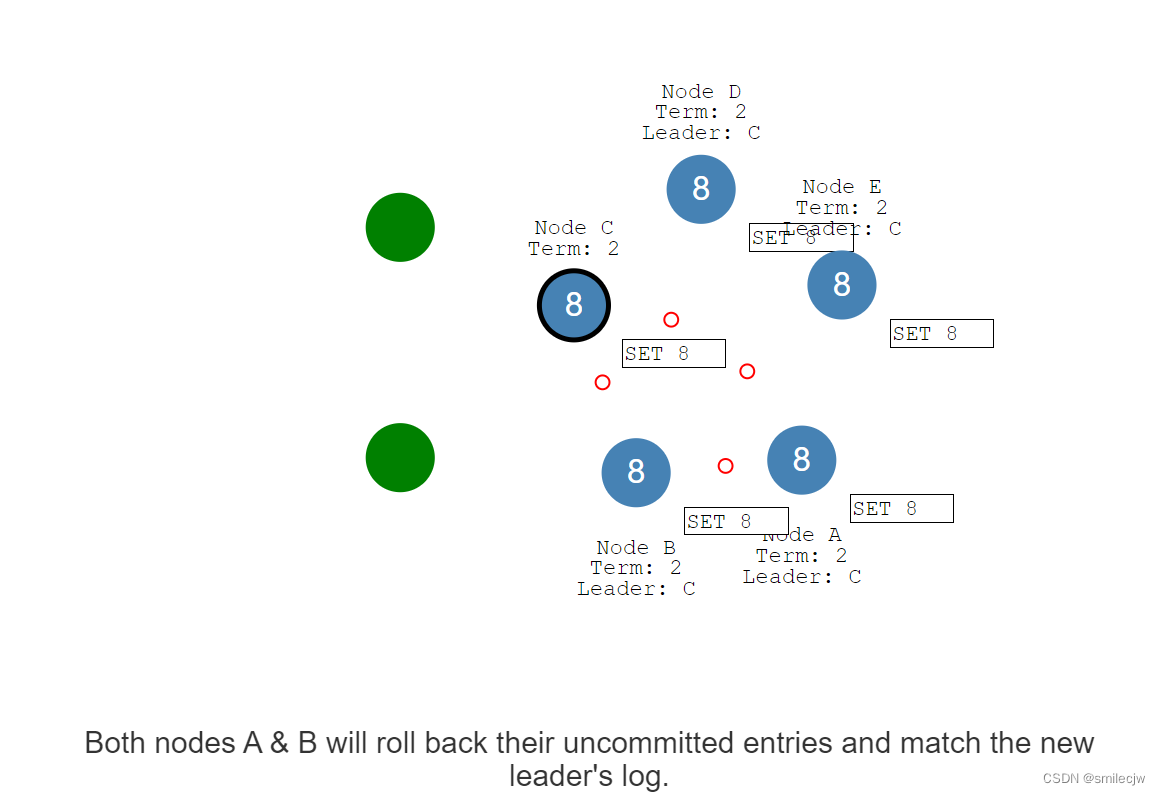
最终,我们就达到了一致性了。















 1053
1053











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









