









 本文深入探讨Redis的高级使用,包括分布式锁实现、缺陷优化、分布式唯一ID生成、缓存穿透与雪崩应对策略,以及Redis的键空间通知、持久化机制、内存回收策略和管道技术,旨在全面掌握Redis在高并发场景下的应用与调优。
本文深入探讨Redis的高级使用,包括分布式锁实现、缺陷优化、分布式唯一ID生成、缓存穿透与雪崩应对策略,以及Redis的键空间通知、持久化机制、内存回收策略和管道技术,旨在全面掌握Redis在高并发场景下的应用与调优。
文章目录
1 前言
上篇内容互联网缓存利器-Redis的使用详解(基础篇)中,介绍了Redis的一些基础使用,本文将介绍一些,Redis的高级使用。
本系列文章,笔者准备对互联网缓存利器Redis的使用,做一下简单的总结,内容大概如下:
| 博文内容 | 资源链接 |
|---|---|
| Linux环境下搭建Redis基础运行环境 | https://blog.csdn.net/smilehappiness/article/details/107298145 |
| 互联网缓存利器-Redis的使用详解(基础篇) | https://blog.csdn.net/smilehappiness/article/details/107592368 |
| Redis基础命令使用Api详解 | https://blog.csdn.net/smilehappiness/article/details/107593218 |
| Redis编程客户端Jedis、Lettuce和Redisson的基础使用 | https://blog.csdn.net/smilehappiness/article/details/107301988 |
互联网缓存利器-Redis的使用详解(进阶篇) | https://blog.csdn.net/smilehappiness/article/details/107592336 |
| 如何基于Redis实现分布式锁 | https://blog.csdn.net/smilehappiness/article/details/107592896 |
| 基于Redis的主从复制、哨兵模式以及集群的使用,史上最详细的教程来啦~ | https://blog.csdn.net/smilehappiness/article/details/107433525 |
| Redis相关的面试题总结 | https://blog.csdn.net/smilehappiness/article/details/107592686 |
2 基于Redis实现分布式锁
2.1 什么是分布式锁
-
什么是分布式锁
关于锁,我们并不陌生,比如Java语言有线程锁,比如:synchronize / Lock等,锁的目的很简单,即在多线程环境下,对共享资源的访问造成的线程安全问题,通过锁的机制来实现资源访问互斥。什么是分布式锁呢?为什么我们需要分布式锁?
其实最根本原因就是锁(互斥)的范围发生了改变,因为在分布式架构中,所有的应用都是集群部署多份并且部署在多个不同的机器上,这些应用(进程)是隔离的,在多进程访问共享资源的时候我们需要满足互斥性,就需要一个所有进程都能看得到的范围,而这个范围可以使用Redis本身或者zookeeper或者数据库等外部设施,所以我们才需要把锁构建到Redis或者zookeeper或者数据库中。
2.2 基于Redis实现分布式锁
Redis里面提供了一些能够实现互斥特性的命令,比如SETNX (在key不存在的情况下为key设置值,key存在的话就不设置值),那么我们可以基于这些命令来去实现锁。
利用Redis实现分布式锁主要用到三个命令:
- SETNX设置key及key的值,如果key存在就设置失败,key不存在就设置成功
- EXPIRE设置key的过期时间
- DEL 删除key
基于Redis实现分布式锁,因为Redis有三个常用的客户端,笔者将以三个客户端为例,分别介绍下,如何基于Jedis实现分布式锁、基于Lettuce实现分布式锁、基于Redisson实现分布式锁。
限于篇幅,这部分内容笔者整理到了另一篇博客中,有需要的童鞋们,可以参考我的另一篇博文中的实现:如何基于Redis实现分布式锁
3 分布式锁的缺陷与高并发下的优化
3.1 分布式锁的缺陷
分布式系统应用中,在进行一些数据安全性要求比较高,用户访问量又比较大的一些场景,比如说商品的减库存操作,肯定需要分布式锁,那么只是简单地使用分布式锁,还是存在一些小问题的。
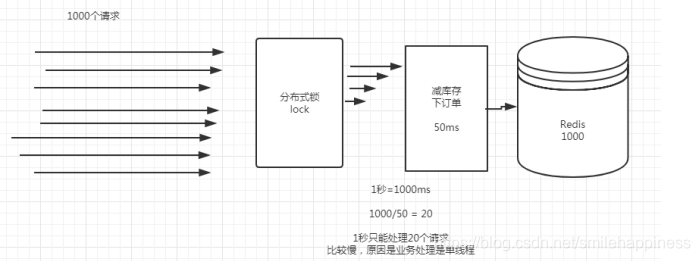
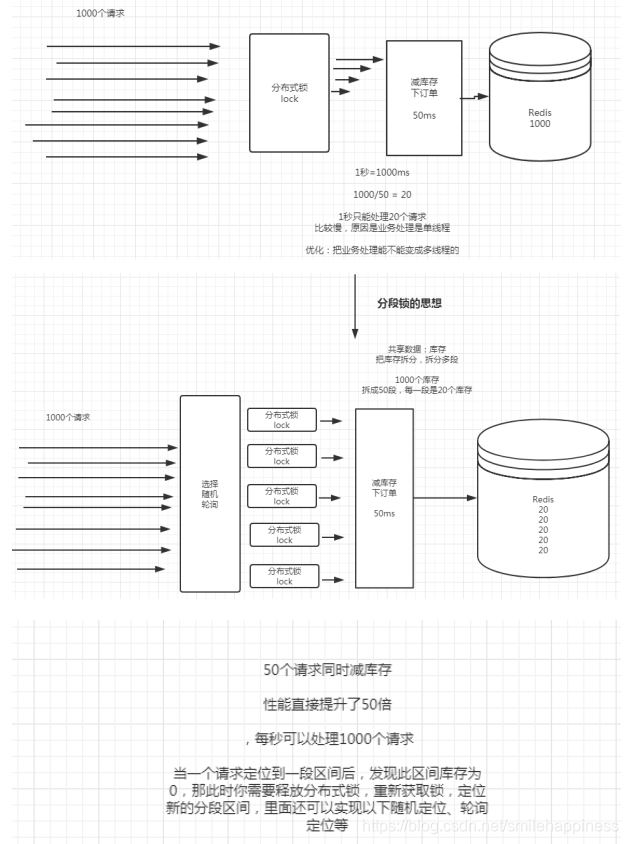
上图中,假如说在同一时间,有1000个用户需要下订单,这时候需要进行商品的减库存操作。如果减库存操作需要50ms才能完成,那么系统每秒只能处理20个请求,这样对于系统来说,远远不够的,系统处理的慢,全部处理完1000个下订单请求需要50秒(20/s),1000个客户中好多客户都要等待下订单,这样对于用户来说不是很友好,那么有什么办法可以优化吗?答案是肯定的
3.2 高并发下分布式锁的优化
为了解决以上分布式锁应用时的小缺陷,引入分段锁思想。
还是上面那个场景,假设刚好有1000个库存,可以够刚才那1000个客户并发请求下单
分段锁优化思想如下:
- 1000个库存,可以分成50段,每段20个库存
- 随机或轮询算法定位分段
- 支持同时50个并发下单
假设每个下单耗时50ms,那么50ms就可以支持50个用户下单。
1s可以下单数 = 1000ms下单=1000/50=20 * 50=1000个,这样就显著增加了下单系统的吞吐量。
核心思想就是: 根据业务情况分段,每个分段都有一把分布式锁,这样用户可以同时请求不同的分段,从而处理不同分段对应的库存,从而达到高并发下的高吞吐量。
设计图大概如下:
4 分布式唯一ID
实际开发中,很多时候需要用到全局唯一性id。常见的生成全局唯一标识的需求,支付、订单、红包、优惠券、跟踪号、银行申请信用卡等等,有很多场景。
如何基于Redis实现分布式全局唯一Id?
基于Redis实现分布式全局唯一Id,目前互联网公司使用这种方案的还是比较多的。
简单说下思路:
通过Redis原子操作命令INCR和INCRBY(redis自增)实现递增,同时可使用Redis集群提高吞吐量,集群后每台Redis的初始值为1,2,3,4,5,步长为5
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
可以使用时间戳 + 业务前缀 + redis自增返回的id ,这样实现的全局唯一Id,可以保证唯一。
5 分布式缓存Redis有哪些使用场景
6 缓存有什么用
缓存就是数据的缓冲,当需要读取数据时,首先从缓存中查找需要的数据,找到了直接执行,找不到则再从其他介质(比如磁盘、数据库等)中查找。一般缓存数据存储在RAM内存中,故从缓存中获取数据,速度极快、效率极高,可以大大提高系统应用的吞吐量。
缓存是解决系统性能问题的利器,就像一把瑞士军刀,锋利强大,可以说缓存在计算机领域处处都有它的身影,比如CPU缓存,磁盘缓存,显卡显存,操作系统缓存等。
由于缓存的重要价值,缓存是互联网分布式架构中非常重要、必不可少的一个部分,通过缓存技术来降低后端服务压力,提升系统整体性能,缩短响应时间。特别是在大流量高并发场景下,缓存可以说是解决大流量高并发,优化系统性能首先要考虑的一个因素。
曾经有人说,“缓存是万金油,哪里有问题,就把缓存加哪里“,这反应出缓存的重要价值和作用,当然缓存的使用,有时候也会遇到一些问题(比如说数据一致性问题等等),使用的时候还是需要多考虑一下。
7 缓存有哪些技术方案
-
对于前端而言,有Nginx / squid缓存、CDN缓存
-
对于应用而言,有
开源框架、开源组件实现的缓存,比如:MyBatis一级缓存/二级缓存,Hibernate一级缓存/二级缓存,Guava、Ehcache、OSCache等组件实现的内存缓存(单体应用),google的leveldb等。 -
(分布式下)对于服务器而言,有开源的缓存中间件,比如
Redis、MemCache、Tair(淘宝)等。
8 Redis缓存穿透 && 缓存击穿 && 缓存雪崩
8.1 缓存处理流程
前台请求,后台先从缓存中取数据,取到直接返回结果,取不到时从数据库中取,数据库取到更新缓存,并返回结果,数据库也没取到,那直接返回空结果。
8.2 Redis缓存穿透
缓存穿透是指大量不存在的key请求,由于缓存没有,便开始查询数据库,但数据库也没有查到数据,比如一些恶意攻击、爬虫等造成大量空命中。即:缓存穿透是指缓存和数据库中都没有的数据,而用户不断发起请求,会导致数据库压力过大,甚至宕机。
解决方案:
-
方案一: 缓存空结果,对数据库查询不存在的数据仍然记录在缓存中缓存一条数据,比如缓存一条空值 unknow,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。这样可以防止攻击用户反复用不存在的key暴力攻击,这样能有效的减少查询数据库的次数。(
无论如何,要保证数据库的可用性) -
方案二: 使用布隆过滤器
8.3 Redis缓存击穿
缓存击穿是指缓存中没有但数据库中有的数据(一般是缓存时间到期),这时由于并发用户特别多,同时读缓存没读到数据,又同时去数据库去取数据,引起数据库压力瞬间增大,造成过大压力导致数据库不可用的现象。
高并发条件下,对于热点数据(一般地,80%的情况下都是访问某些热点数据,也就是访问某些热点key,其他key访问会比较少),当数据缓存失效的一瞬间,或者刚开始时缓存中还没有对热点数据进行缓存,所有请求都被发送到数据库去查询,导致数据库被压垮。
解决方案:
-
方案一: 使用全局互斥锁,就是在访问数据库之前都先请求全局锁,获得锁的那个才有资格去访问数据库,其他线程必须等待。由于现在的业务都是分布式的,本地锁没法控制其他服务器也等待,所以要用到全局锁,比如分布式锁。
-
方案二: 对即将过期的数据主动刷新,比如起一个后台定时任务轮询,主动更新缓存数据,保证缓存不会全部失效。
-
方案三: 设置热点数据永远不过期
8.4 Redis缓存雪崩
缓存雪崩是指:比如我们给所有的数据设置了同样的过期时间,然后在某一个历史性时刻,整个缓存的数据全部过期了,然后瞬间所有的请求都落到数据库,数据库被压垮,或者是缓存发生故障,导致所有的请求都落入到数据库,数据库被压垮。
简单来说就是,缓存雪崩是指缓存中数据大批量到过期时间,而查询数据量巨大,引起数据库压力过大甚至宕机。和缓存击穿不同的是,缓存击穿指并发查同一条数据,缓存雪崩是不同数据都过期了,很多数据都查不到从而查数据库,缓存雪崩更加的严重。
缓存雪崩的核心就是你的缓存不能用了,不能用了包含两种情况:
突然有一个高并发请求:
- 我要查的数据都没有缓存,那么都查询数据库,数据库可能被查询宕机
- 缓存本身就不能用了,比如缓存宕机了,那么也导致所有请求都查询数据库,数据库宕机
解决方案:
事前:
- redis要高可用(搭建集群或者主从哨兵),避免redis不可用
- 缓存数据的过期时间设置随机,防止同一时间大量数据过期现象发生
- 如果缓存数据库是分布式部署,将热点数据均匀分布在不同的缓存数据库中
事中:
- 本地ehcache缓存(mybatis二级缓存)+限流&降级(比如返回:系统繁忙,请稍后再试或者网络开小差了等等),避免数据库被压垮
- 也可以使用极端的处理,把热点数据设置为-1,即永远不过期
事后: redis持久化,快速恢复缓存数据

9 Redis的键空间通知
9.1 什么是键空间通知
键空间通知也叫(Redis Keyspace Notifications),是从Redis 2.8.0 就开始引入的一种特性,键空间通知允许客户端订阅发布/订阅通道,以便以某种方式接收影响redis数据集的事件。
比如:
- 当指定的key的数据被操作时,redis将发布通知事件
- 当key过期时,redis将发布通知事件
我们客户端可以订阅通知,当通知发布时候,我们客户端接收到通知,然后以便于我们进行相关业务处理。使用redis的普通pub/sub层传递事件,因此,实现pub/sub的客户机可以使用此功能而无需更多的修改。
Redis目前的订阅与发布功能采取的是发送即忘(fire and forget)策略,比如pub/sub客户端断开连接,并在稍后重新连接,则在客户端断开时发布的所有事件都会丢失。如果您的应用程序需要可靠的事件通知,目前是不支持的。Redis作者表示以后会改进这一功能,以支持更可靠的事件通知。
因为开启键空间通知功能需要消耗一些 CPU , 所以在默认配置下, 该功能处于关闭状态。
9.2 开启Redis的键空间通知
应用步骤:
-
修改 redis.conf 文件,找到
notify-keyspace-events配置项,当 notify-keyspace-events 选项的参数为空字符串时,表示功能关闭,当配置项参数不是空字符串时,表示功能开启。修改了redis配置需要重启一下redis,notify-keyspace-events 的参数可以是以下字符的任意组合, 它指定了服务器该发送哪些类型的通知:
字符发送的通知类型:
K键空间通知,所有通知以__keyspace@<db>__为前缀
E键事件通知,所有通知以__keyevent@<db>__为前缀gDEL 、 EXPIRE 、 RENAME 等类型无关的通用命令的通知
$字符串命令的通知:string类型
l列表命令的通知:list类型
s集合命令的通知:set
h哈希命令的通知:hash
z有序集合命令的通知:zset
x过期事件:每当有过期键被删除时发送
e驱逐(evict)事件:每当有键因为 maxmemory 政策而被删除时发送
A参数g$lshzxe的别名输入的参数中至少要有一个 K 或者 E , 否则的话, 不管其余的参数是什么, 都不会有任何通知被分发,即
至少要有一个键空间通知或者键事件通知。比如:如果只想订阅键空间中和列表相关的通知, 那么参数就应该设为
Kl, 诸如此类设置即可。将参数设为字符串 “
AKE” 表示发送所有类型的通知。注意:所有命令都只在键真的被改动了之后,才会产生通知事件。比如说,当SREM key member [member …] 试图删除不存在于集合的元素时,删除操作会执行失败,因为没有真正的改动键,所以这一操作不会发送通知。 -
通知事件的格式
事件是用__keyspace@DB__:KeyPattern或者__keyevent@DB__:OpsType的格式来发布消息的
参数说明:
DB表示在第几个库,KeyPattern则是表示需要监控的键模式(可以用通配符)
OpsType则表示操作类型,因此,如果想要订阅特殊的Key上的事件,应该是订阅keyspace
keyspace@0:redis:lock*(指的是redis的key,可以使用正则表达式,比如*号表示匹配所有的key)
keyevent@0:del(redis操作类型)
9.3 键通知基础示例
下面,笔者以Jedis客户端为例,看一下如何使用Redis的键通知。
首先定义一个通知监听器:
public class NotifyListener extends JedisPubSub {
/**
* 比如有一个程序把redis里面的一个key删除了,那么此时我这个就收到一个通知
*
* 比如redis里面的一个key过期了,那么此时我这个就收到一个通知
*
* @param pattern
* @param channel
* @param message
*/
@Override
public void onPMessage(String pattern, String channel, String message) {
System.out.println(pattern + "----" + channel + "-----" + message);
//收到了通知,然后开始实现我们的业务处理;
}
}
【测试用例】
public class NotifyTest {
public static void main(String[] args) {
Jedis jedis = JedisPoolInstance.getJedisPoolInstance().getResource();
//程序运行起来之后,让程序订阅一个频道,当该频道有消息的时候,就会回调我们的NotifyListener监听器的onMessage方法
jedis.psubscribe(new NotifyListener(),
"__keyspace@0__:*", "__keyevent@0__:del", "__keyevent@0__:expired", "__keyevent@*__:*");
}
}
以上定义,表示监听键空间通知中的所有key,监听了删除事件,过期事件,最后一个__keyevent@*__:*表示监听所有的事件。
10 Redis的持久化
Redis的数据存储在内存中,内存是瞬时的,如果Linux服务宕机或重启,又或者Redis崩溃或重启,所有的内存数据都会丢失,为了解决这个问题,Redis提供两种机制对数据进行持久化,便于恢复数据。一种是RDB方式、另一种是AOF方式。这两种方式可以结合使用。
10.1 RDB方式实现Redis的持久化
Redis Database(RDB),是指在指定的时间间隔内将内存中的数据集快照写入磁盘,数据恢复时将快照文件直接再读到内存。
10.1.1 RDB方式实现
如何实现:
RDB方式的数据持久化,仅需在redis.conf文件中配置即可。RDB持久化方式默认是开启的,我们安装完Redis后不做配置,它也是会持久化的。
配置文件搜索 SNAPSHOTTING 部分,配置格式:save <seconds> <changes>
save 900 1
save 300 10
save 60 10000
RDB的其它相关配置项:
stop-writes-on-bgsave-error 取值为yes或no,如果后台最新的保存操作失败,那么Redis将停止接收写操作,Redis保存成功之后,再次接收写操作,默认为yes
rdbcompression 取值为yes或no,Redis使用LZF压缩RDB文件,默认为yes
rdbchecksum 取值为yes或no,Redis在RDB文件末尾保存一个校验码,在加载RDB文件之前执行校验,如果RDB校验码不匹配,Redis不启动,默认为yes
dbfilename 设置RDB的文件名,默认为dump.rdb
dir 指定AOF和RDB文件目录
10.1.2 RDB方式的内部实现原理
当满足条件时,Redis会单独创建(fork)一个子进程来进行持久化,会先将数据写入到一个临时文件中,等到持久化过程都结束了,再用这个临时文件替换上次持久化好的文件,整个过程中,主进程是不进行任何关于持久化相关的IO操作的,这就确保了不影响主进程,保证Redis极高的性能。
如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感,那RDB方式要比AOF方式更加的高效,RDB的缺点是最后一次持久化后的数据可能丢失。
Redis会在以下几种情况下对数据进行快照持久化:
- 根据配置时间规则进行自动快照
- 用户执行SAVE或者BGSAVE命令
- 执行FLUSHALL命令
- 执行复制(replication)时
10.1.2.1 根据配置规则进行自动快照
Redis允许用户自定义快照条件,当符合快照条件时,Redis会自动执行快照操作,快照的条件可以由用户在配置文件中配置,配置格式如下
配置格式:save <seconds> <changes>
save 900 1
save 300 10
save 60 10000
每条快照规则占一行,每条规则之间是“或”的关系
10.1.2.2 用户执行SAVE或BGSAVE命令
除了让Redis自动进行快照以外,当我们对服务进行重启或者服务器迁移,我们需要人工去备份内存数据到磁盘上,redis提供了save和bgsave两条命令来完成这个任务 。
-
save命令
当执行save命令时,Redis同步做快照操作,在快照执行过程中会阻塞所有来自客户端的请求。当redis内存中的数据较多时,通过该命令将导致Redis较长时间的不响应,所以不建议在生产环境上使用这个命令,而是推荐使用 bgsave命令 -
bgsave命令
bgsave命令可以在后台异步地进行快照操作,快照的同时服务器还可以继续响应来自客户端的请求,执行BGSAVE后,Redis会立即返回Background saving started表示开始执行快照操作。通过LASTSAVE命令可以获取最近一次成功执行快照的时间。
10.1.2.3 执行FLUSHALL命令
该FLUSHALL命令会清除redis在内存中的所有数据,执行该命令后,只要redis中配置的快照规则不为空,也就是save的规则存在,redis就会执行一次快照操作。不管规则是什么样的都会执行,如果没有定义快照规则,就不会执行快照操作。
与flushall命令类似的,有一个fluashdb命令,fluashdb表示清除当前数据库的数据,该命令不会触发持久化操作。
10.1.2.4 执行主从复制时
该操作主要是在主从模式下,redis会在复制初始化时进行自动快照。
需要注意的是: 当执行复制操作时,即使没有定义自动快照规则,并且没有手动执行过快照操作,它仍然会生成 RDB快照文件。
10.2 Redis的持久化AOF方式
AOF即Append-only File(AOF),Redis每次接收到一条改变数据的命令时,它将把该命令写到一个AOF文件中(只记录写操作,不记录读操作),当Redis重启时,它通过执行AOF文件中所有的命令来恢复数据。AOF是在RDB之后出现的一种技术,这种方式的持久化让redis的数据不会丢失。
当使用Redis存储非临时数据时,一般需要开启AOF持久化来降低Redis故障导致的数据丢失,AOF可以将Redis执行的每一条写命令追加到硬盘文件中,这一过程会降低Redis的性能,但大部分情况下这个影响是能够接受的,另外使用较快的硬盘(固态硬盘)可以提高AOF的性能。
10.2.1 AOF方式实现Redis的持久化
AOF方式的数据持久化,仅需在redis.conf文件中配置即可,搜索配置文件中的APPEND ONLY MODE, appendonly no 默认是no,改成yes即开启aof持久化。
AOF的相关配置选项:
appendonly 默认是no,改成yes即开启了aof持久化
appendfilename 指定AOF文件名,默认文件名为appendonly.aof(该文件要Redis自己启动创建,测试时发现,自己创建该文件时,无法向文件写入持久化命令)
appendfsync 配置向aof文件写命令数据的策略:
- no:不主动进行同步操作,而是完全交由操作系统来做(即每30秒一次),比较快但不是很安全
- always:每次执行写入都会执行同步,慢一些但是比较安全,数据不会丢失
- everysec:每秒执行一次同步操作,比较平衡,介于速度和安全之间
dir 指定AOF和RDB文件的目录
auto-aof-rewrite-percentage 当目前aof文件大小超过上一次重写时的aof文件大小的百分之多少时,会再次进行重写,如果之前没有重写,则以启动时的aof文件大小为依据
auto-aof-rewrite-min-size 允许重写的最小AOF文件大小
最后,我们可以同时使用这两种方式,redis默认优先加载aof文件。
10.2.2 重写是怎么回事
AOF 文件会在操作过程中变得越来越大。比如,如果你做一百次加法计算,最后你只会在数据库里面得到最终的数值(k 100),但是在你的 AOF 里面会存在 100 次记录,其中 99 条记录对最终的结果是无用的。但 Redis 支持在不影响服务的前提下在后台重构 AOF文件,让文件得以整理变小。
10.2.3 AOF的重写原理
重写时,主进程会fork一个子进程出来进行AOF重写,这个重写过程并不是基于原有的aof文件来做的,而是有点类似于快照的方式,全量遍历内存中的所有数据,然后逐个序列到aof文件中。
在fork子进程这个过程中,服务端仍然可以对外提供服务,在重写aof文件的过程中,主进程的数据更新操作,会缓存到aof_rewrite_buf中,也就是单独开辟一块缓存来存储重写期间收到的操作命令,当子进程重写完以后再把缓存中的数据追加到新的aof文件。
当所有的数据全部追加到新的aof文件中后,把新的aof文件重命名,此后所有的操作都会被写入新的aof文件。如果在rewrite过程中出现故障,不会影响原来aof文件的正常工作,只有当rewrite完成后才会切换覆盖原来那个文件,因此这个 rewrite过程是比较稳定可靠的。
11 Redis内存回收策略
Redis中提供了多种内存回收策略,当内存容量不足时,为了保证程序的运行,这时就不得不淘汰内存中的一些对象,释放这些对象占用的空间,那么选择淘汰哪些对象呢?
其中,默认的策略为noeviction策略,当内存使用达到阈值的时候,所有引起申请内存的命令会报错。
首先,需要设置最大内存限制 maxmemory 5120mb
Redis官方:
Setting maxmemory to zero results into no memory limits. This is the default behavior for 64 bit systems, while 32 bit systems use an implicit memory limit of 3GB.
选择的策略类型:
maxmemory-policy noeviction
noeviction: 默认策略,不淘汰,如果内存已满,添加数据时报错
allkeys-lru: 在所有键中,选取最近最少使用的数据淘汰
volatile-lru: 在设置了过期时间的所有键中,选取最近最少使用的数据淘汰
allkeys-lfu: 在所有键中,选取最近最不常访问的数据淘汰
volatile-lfu: 在设置了过期时间的所有键中,选取最近最不常访问的数据淘汰
allkeys-random: 在所有键中,随机淘汰
volatile-random: 在设置了过期时间的所有键,随机淘汰
volatile-ttl: 在设置了过期时间的所有键,存活时间最短的数据淘汰
12 数据库与Redis缓存双写不一致性问题
更新中…
13 Redis使用管道提升性能
13.1 为什么需要使用管道技术
Redis服务是一种C/S模型,即客户端发起请求,服务端处理并返回结果给客户端,如果Redis客户端要发送很多条请求,后面的请求需要等待前面的请求处理完后才能进行处理,而且每个请求都存在往返时间,即使redis性能极高,当数据量足够大,也会极大影响性能,所以Redis为了改进该问题,引入了管道技术。
管道技术
使用管道技术,可以在服务端未及时响应的时候,客户端也可以继续发送命令请求,做到客户端和服务端互不影响,服务端并最终返回所有服务端的响应,大大提高了C/S模型交互的响应速度。(比如批量对Redis操作)
13.2 Redis中如何使用管道技术提升性能
使用方法:
在jedis中使用管道Pipeline
Jedis client中使用管道核心代码如下:
Jedis jedis = new Jedis("10.10.128.10", 6379);
jedis.auth("123456789");
Pipeline pipeline = jedis.pipelined();
//批量操作
for (int i=0; i<10000; i++) {
pipeline.incr("k");
}
pipeline.sync();
在redisTemplate使用管道Pipeline核心代码如下:
List<Object> list = redisTemplate.executePipelined(new RedisCallback<Long>() {
@Override
public Long doInRedis(RedisConnection connection) throws DataAccessException {
connection.openPipeline();
for (int i = 0; i<100000; i++) {
String key = "kkk"+i;
connection.set(key.getBytes(), "1".getBytes());
}
//不能返回非空值
return null;
}
});
list.forEach((Object obj) -> {
System.out.println(obj.toString());
});
14 基于Redis的主从复制、哨兵模式以及集群的使用
使用Redis,当然也要保证服务的高可用性。那么如何保证Redis服务的高可用性?
使用基于Redis的主从复制的哨兵模式,Redis cluster集群都可以实现Redis服务的高可用。限于篇幅,这部分内容笔者整理到了另一篇博客中,有需要的老铁们,可以参考我的另一篇博文中的实现:基于Redis的主从复制、哨兵模式以及集群的使用
好啦,本系列Redis使用的核心内容就介绍这么多,后面再出一篇Redis相关的面试题,如果对老铁们有所帮助,欢迎点个赞支持下,您的支持是笔者创作的最大动力!
参考资料链接: https://blog.csdn.net/kongtiao5/article/details/82771694
写博客是为了记住自己容易忘记的东西,另外也是对自己工作的总结,希望尽自己的努力,做到更好,大家一起努力进步!
如果有什么问题,欢迎大家评论,一起探讨,代码如有问题,欢迎各位大神指正!
给自己的梦想添加一双翅膀,让它可以在天空中自由自在的飞翔!

















 1342
1342

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









