






背景
环境
- Windows
- python
- selenium
目标
- 打开店铺连接获取商品信息
问题
- 店铺地址:店内搜索页-半岛国际酒店用品-淘宝网 (taobao.com)
- 无法找到价格
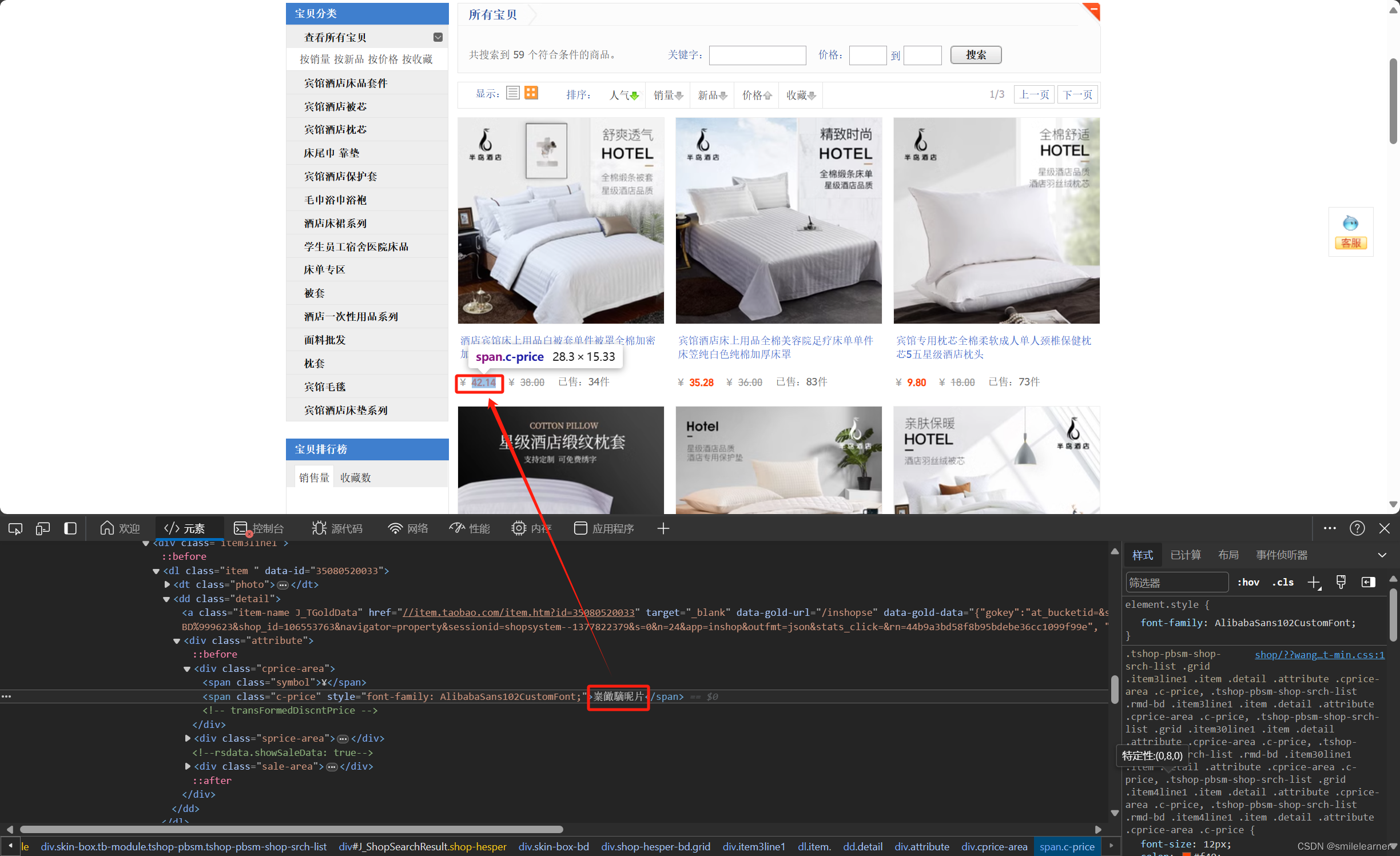
- 页面价格 42.14,HTML文件中展示的是 : 嶪䭛䮰昵片
解决过程
什么是字体反爬
字体反爬简介
在 CSS3 之前,Web 开发者必须使用用户计算机上已有的字体。目前的技术开发者可以使用@font-face为网页指定字体,开发者可将心仪的字体文件放在 Web 服务器上,并在CSS 样式中使用它。用户使用浏览器访问 Web应用时,对应的字体会被浏览器下载到用户的计算机上。
注:使用自动化selenium也无法获取正常的数据
- 在页面源代码中搜索
font-face关键字,可以发现字体文件在网页源代码中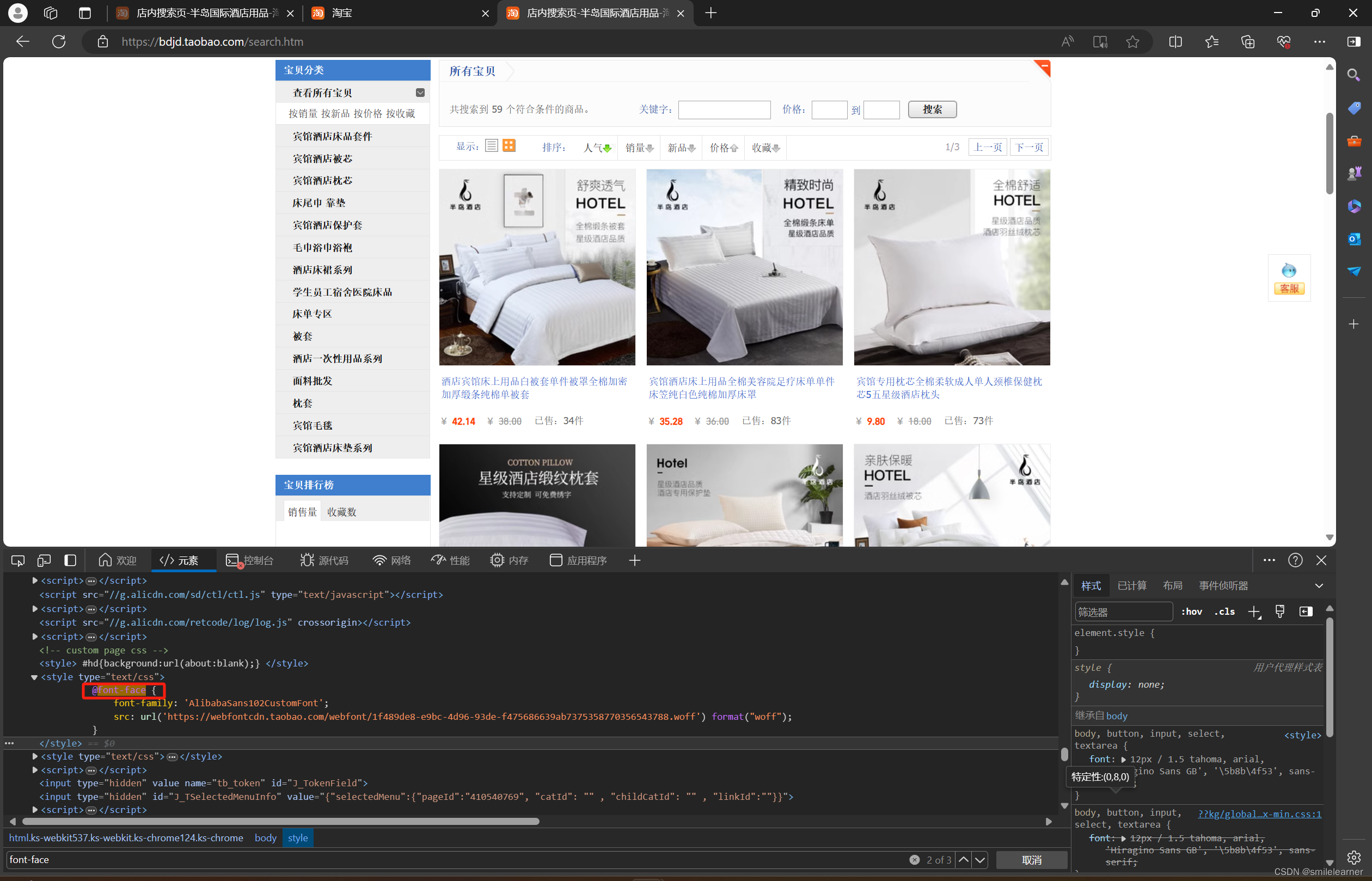
- 可以在网络抓包里面进行筛选,可以发现这里面有对应的字体文件加载地址,由后端返回
如何解决
确定反爬方式
字体反爬
寻找字体文件
即网站定义了字体文件,然后进行相应的查找替换,在前端看起来,是没有任何差异的。其实从审查元素的也是可以看到的:
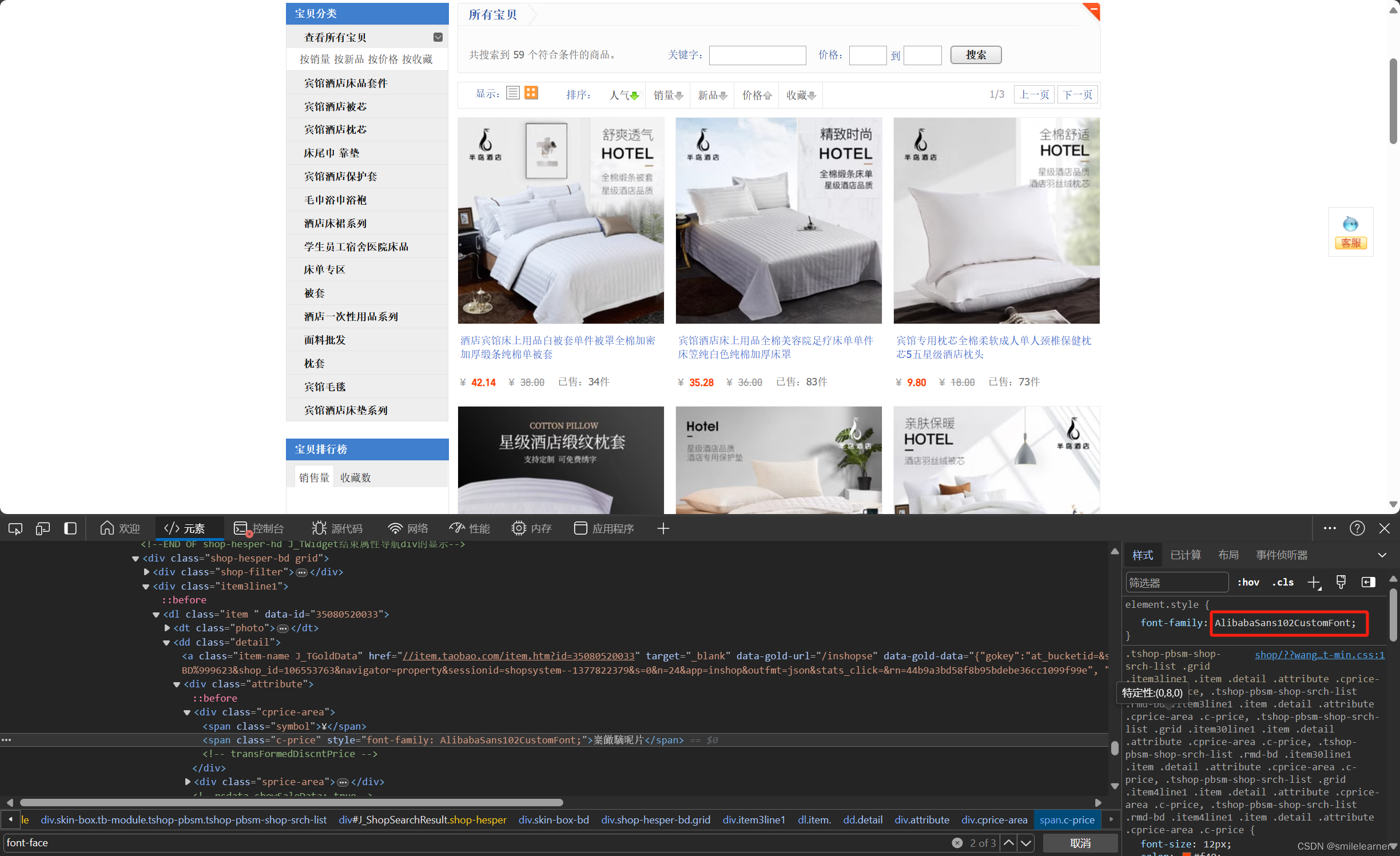
在源代码中搜索 AlibabaSans102CustomFont
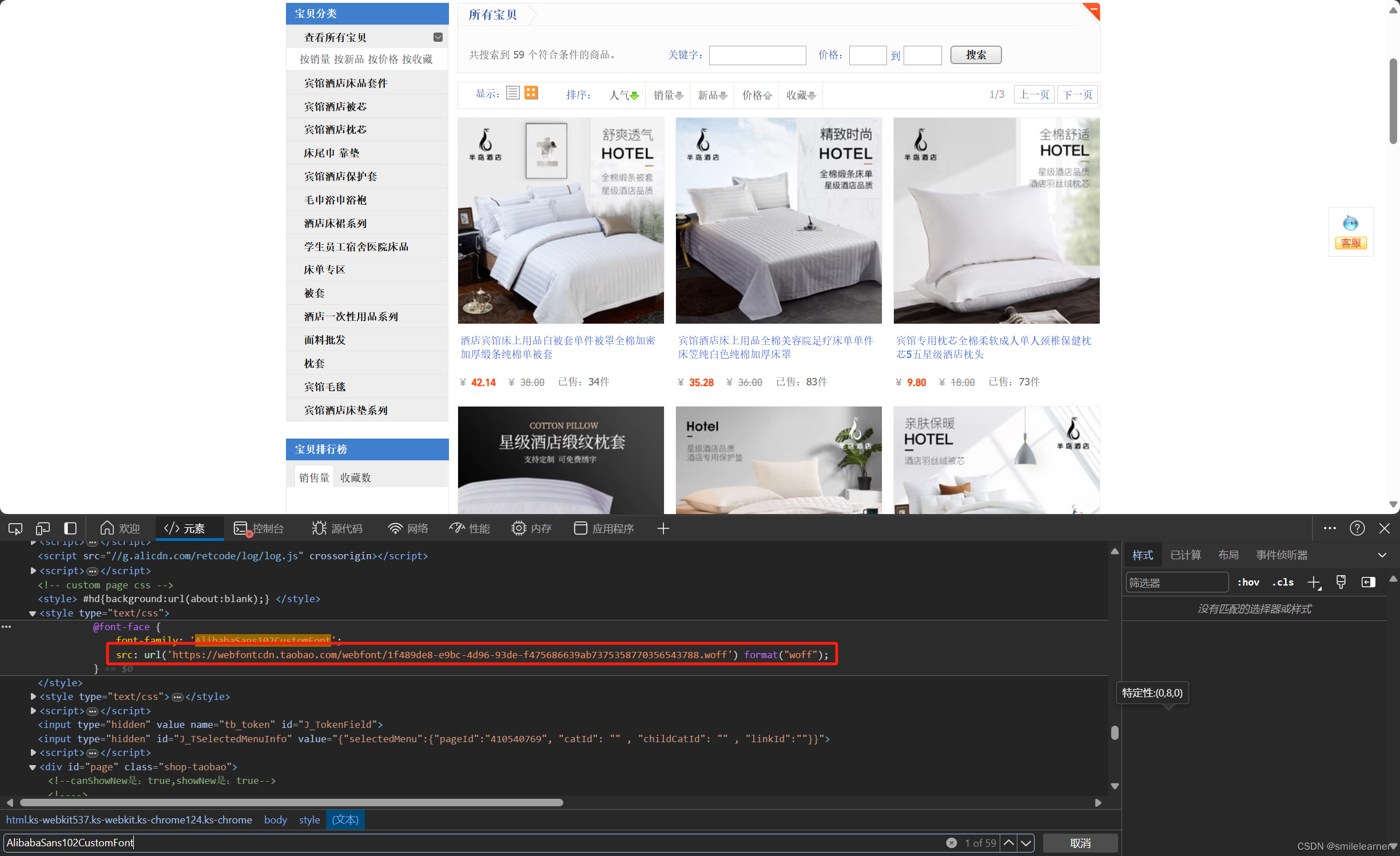
@font-face {
font-family: 'AlibabaSans102CustomFont';
src: url('https://webfontcdn.taobao.com/webfont/1f489de8-e9bc-4d96-93de-f475686639ab7375358770356543788.woff') format("woff");
}下载字体文件
字体文件地址:https://webfontcdn.taobao.com/webfont/1f489de8-e9bc-4d96-93de-f475686639ab7375358770356543788.woff
在浏览器中可以直接下载字体文件.woff

研究字体文件
因为我们要对字体进行研究,所以必须将它打开
- 方式一:使用软件 FontCreator 打开字体文件
软件下载地址:Download FontCreator (high-logic.com) 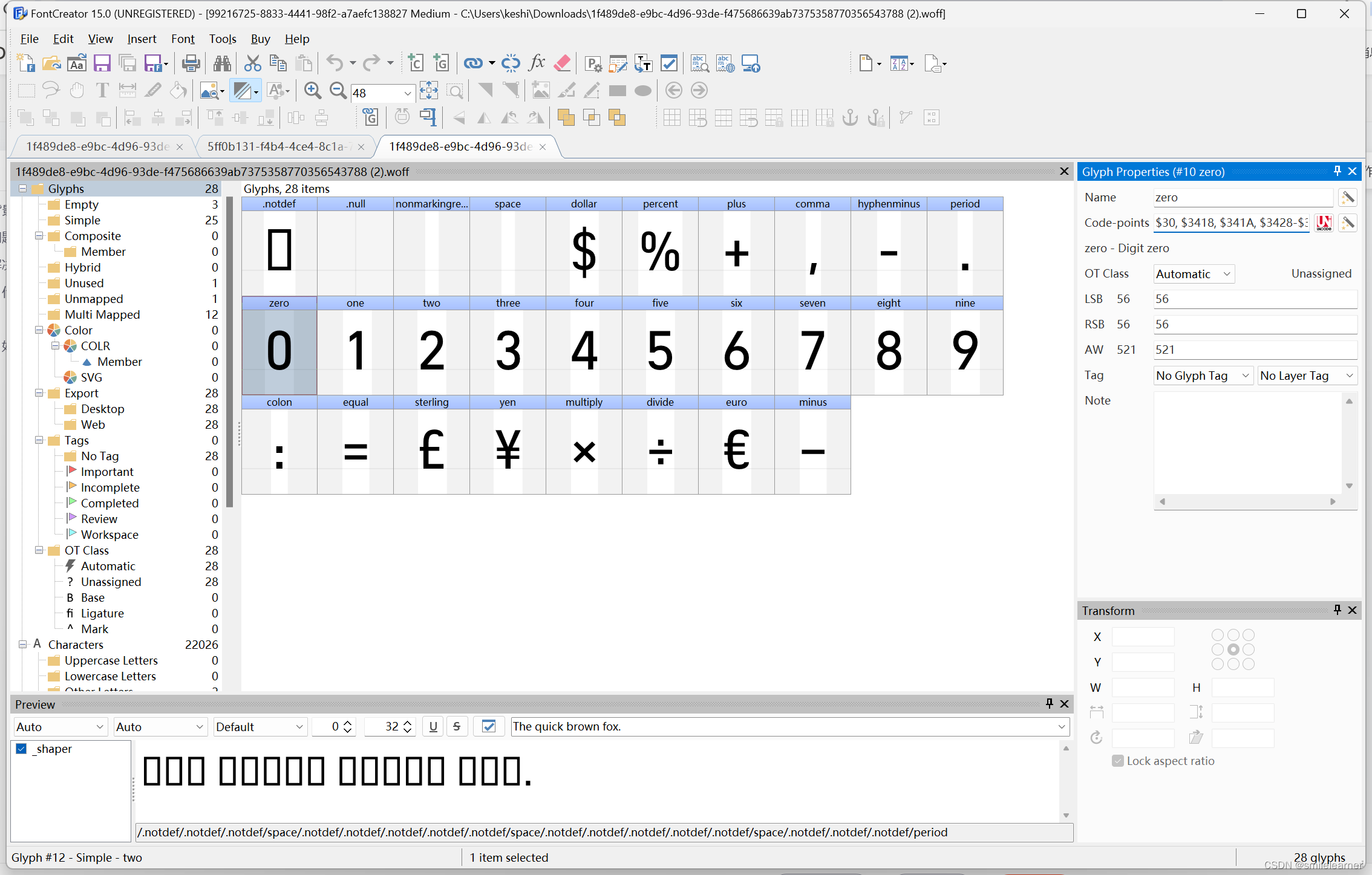
- 方式二:使用在线工具解析
- 在线地址:在线字体编辑器-JSON在线编辑器
- 使用方式:访问在线工具网站,点击左上角打开,找到本地目录字体文件即可
很明显,每个字可以看到字形和字形编码

字形:1
字形编码:one
字体解析工具
工具安装
pip install fontTools # 使用这个包处理字体文件字体读取
from fontTools.ttLib import TTFont
# 加载字体文件:
font = TTFont('1f489de8-e9bc-4d96-93de-f475686639ab7375358770356543788 (2).woff')
# 转为xml文件:
font.saveXML('file.xml')
file.xml 预览
<tableVersion version="0"/>
<cmap_format_4 platformID="3" platEncID="1" language="0">
<map code="0x0" name="NULL"/><!-- ???? -->
<map code="0xd" name="nonmarkingreturn"/><!-- ???? -->
<map code="0x20" name="space"/><!-- SPACE -->
<map code="0x24" name="dollar"/><!-- DOLLAR SIGN -->
<map code="0x25" name="percent"/><!-- PERCENT SIGN -->
<map code="0x2b" name="plus"/><!-- PLUS SIGN -->
<map code="0x2c" name="comma"/><!-- COMMA -->
<map code="0x2d" name="hyphen"/><!-- HYPHEN-MINUS -->
<map code="0x2e" name="period"/><!-- FULL STOP -->
<map code="0x30" name="zero"/><!-- DIGIT ZERO -->
<map code="0x31" name="one"/><!-- DIGIT ONE -->
<map code="0x32" name="two"/><!-- DIGIT TWO -->
<map code="0x33" name="three"/><!-- DIGIT THREE -->
<map code="0x34" name="four"/><!-- DIGIT FOUR -->
<map code="0x35" name="five"/><!-- DIGIT FIVE -->
<map code="0x36" name="six"/><!-- DIGIT SIX -->
<map code="0x37" name="seven"/><!-- DIGIT SEVEN -->
<map code="0x38" name="eight"/><!-- DIGIT EIGHT -->
<map code="0x39" name="nine"/><!-- DIGIT NINE -->
<map code="0x3a" name="colon"/><!-- COLON -->
<map code="0x3d" name="equal"/>在xml文件中可以看到 <map code="0x31" name="one"/><!-- DIGIT ONE -->
分析
自此已知的条件:
- 页面展示的价格:价格 42.14
- HTML文件中展示的价格 : 嶪䭛䮰昵片
- 字体文件中:字形‘1’对应的字形编码是‘one’
- 字体文件转换的xml文件中:name="one" code="0x31"
依据条件可以做出的分析:
- 数字:1 对应 汉字:昵 ;字形‘1’对应code="0x31"
- 一个数字对应一个汉族
- 字形 字形编码 和 code 存在某种对应关系
尝试的可能的方法:
- 既然是汉族数字一一对应,例如数字1,对应的汉族找出来,形成字典即可。十个数字加一个小数点
结果:多个汉族对应 同一个 数字。无法获取到全部数字对应的汉字,就无法整理全 - selenium截图,对价格就行截图,再进行OCR
- 找出对应关系
解决方案
在xml文件中直接查询《name="one"》有2004个,说明有2004个编码对应数字1
一直没有头绪,就直接百度《0x31是什么字符》,发现:0x31是字符'1'的ASCII编码
百度《汉族 昵 对应的编码》发现:“昵”的Unicode编码(通常是UTF-16编码格式):U+662D
在xml文件中搜索《662D》发现:<map code="0x662d" name="one"/>
终于发现了:汉族“昵”的编码是“U+662D”,编码“U+662D”对应name="one",name="one"就对字形“1”
只需获取汉字对应的Unicode编码,就可以在xml文件中找到对应的数字了。
代码
import unicodedata
from fontTools.ttLib import TTFont
'''
实际价格:42.14
显示汉字:嶪䭛䮰昵片
'''
def get_unicode_code_point(characters):
'''
返回十六进制Unicode编码
'''
return ''.join(f'U+{ord(c):04X}' for c in characters)
# print(get_unicode_code_point('洛'))
def get_unicode_code(characters):
'''
返回十进制Unicode编码
'''
return [ord(c) for c in characters]
# print(get_unicode_code('嶪䭛䮰昵片'))
# 加载字体文件:
font = TTFont('1f489de8-e9bc-4d96-93de-f475686639ab7375358770356543788 (2).woff')
# 转为xml文件:
# font.saveXML('file.xml')
# 获取字体映射关系
font_cmap = font['cmap'].getBestCmap()
base_dict = {
'period': '.',
'zero': '0',
'one': '1',
'two': '2',
'three': '3',
'four': '4',
'five': '5',
'six': '6',
'seven': '7',
'eight': '8',
'nine': '9',
}
if __name__ == '__main__':
price_str = ''
price_str_s = '嶪䭛䮰昵片'
unicode_codes = get_unicode_code(price_str_s)
for unicode_code in unicode_codes:
name = font_cmap[unicode_code]
price_str += base_dict[name]
print(price_str)
输出:42.14
总结
参考了众多网友写的文章,表示感谢
如果本文对您有帮助,请给我点赞吧

















 2005
2005

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









