







 该博客介绍了如何使用ArcGIS将矢量地图转换为栅格,并通过Python处理栅格文件以生成EFDC所需的cell.inp、dxdy.inp和lxly.inp文件。涉及的操作包括数据格式转换、特定值替换以及文件整理,为水动力学模型的预处理提供了详细步骤。
该博客介绍了如何使用ArcGIS将矢量地图转换为栅格,并通过Python处理栅格文件以生成EFDC所需的cell.inp、dxdy.inp和lxly.inp文件。涉及的操作包括数据格式转换、特定值替换以及文件整理,为水动力学模型的预处理提供了详细步骤。
一. EFDC网格文件的格式说明
(这部分以后有时间再补充)
二. ArcGIS操作
1.矢量地图转栅格
给shp文件增加一列属性,命名为value,值为5;
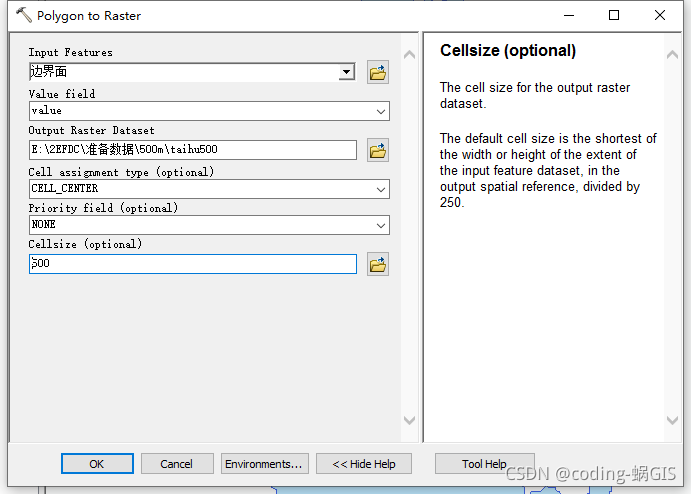
工具:Conversion Tools - To Raster - Polygon to Raster
将Cellsize设置为你需要的栅格大小,我设置了500m。
before&after


备注:我所使用的坐标系
投影坐标系:Krasovsky_1940_Transverse_Mercator
地理坐标系:GCS_Krasovsky_1940
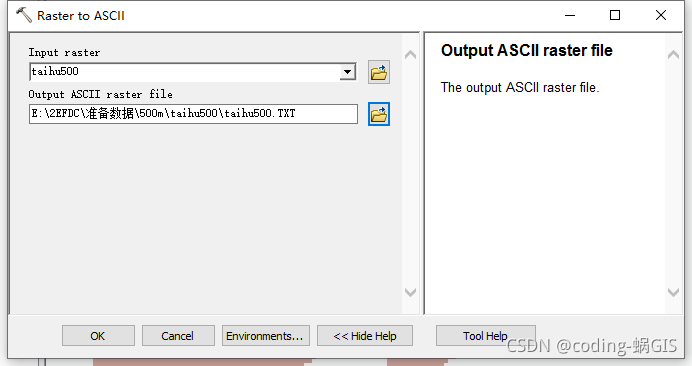
2.栅格导出为TXT
工具:Conversion Tools - From Raster - Taster to ASCII
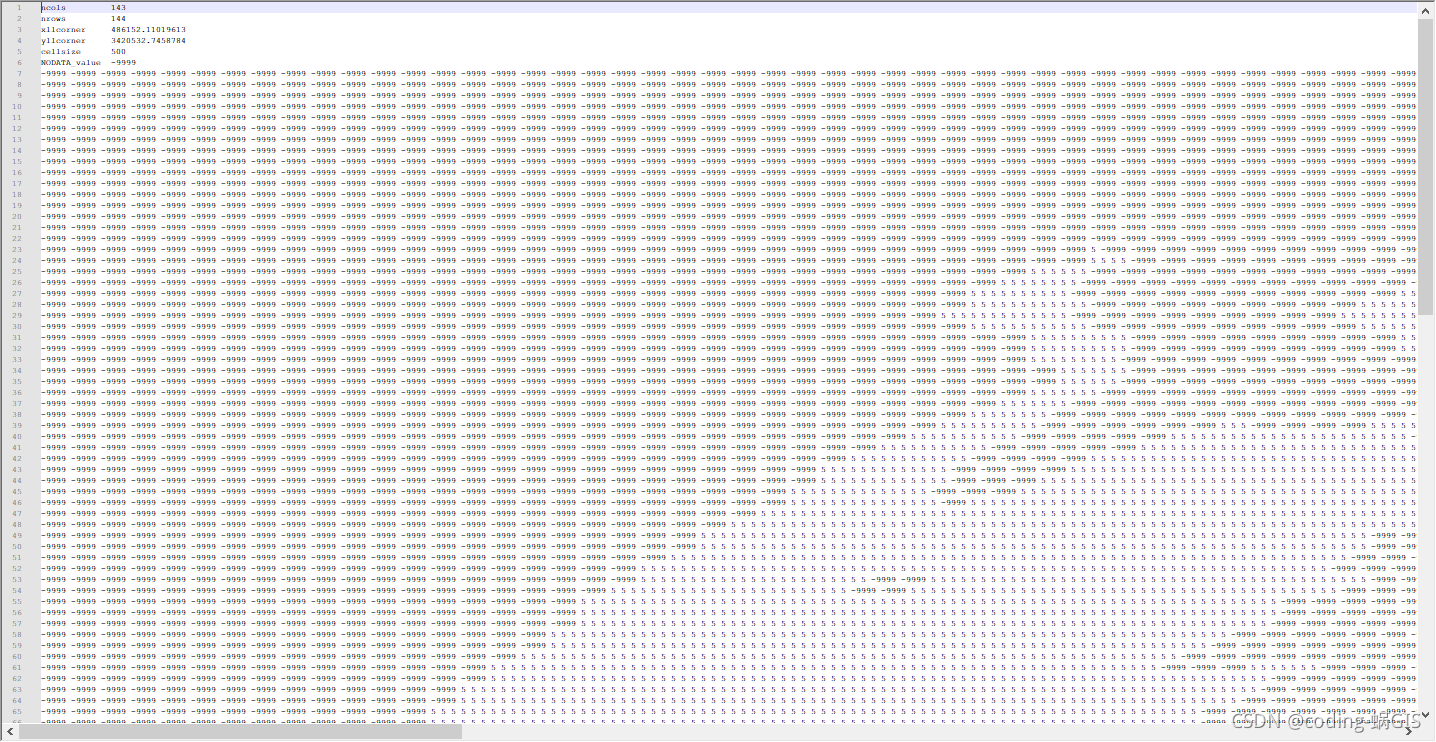
打开taihu500.txt查看一下数据格式,局部如图所示。NoData的部分为-9999,与EFDC不同。
三. 制作EFDC所需文件(Python)
1. cell.inp
①手动删除前六行。提前记录一下,后面可能会用到。

②将5和-9999交界处(包括角)的-9999替换为9,其它-9999替换为9
代码如下:
f = open("taihu500.txt", "r")
f2 = open("cell-init.txt", "wt")
lines = f.read()
data = lines.split('\n')
row = len(data)
for i in range(1, row-2):
line0 = data[i-1].split()
line = data[i].split()
line1 = data[i+1].split()
col = len(line)
for j in range(1, col-1):
'''
if line[j].strip('\n') == '-9999' and line[j+1].strip('\n') == '5':
line[j] = '9'
elif line[j].strip('\n') == '-9999' and line[j-1].strip('\n') == '5':
line[j] = '9'
elif line[j].strip('\n') == '-9999' and line0[j].strip('\n') == '5':
line[j] = '9'
elif line[j].strip('\n') == '-9999' and line1[j].strip('\n') == '5':
line[j] = '9'
elif line[j].strip('\n') == '-9999':
line[j] = '0'
'''
if line[j].strip('\n') == '-9999':
if line[j+1].strip('\n') == '5':
line[j] = '9'
if line[j-1].strip('\n') == '5':
line[j] = '9'
if line0[j].strip('\n') == '5':
line[j] = '9'
if line1[j].strip('\n') == '5':
line[j] = '9'
# corner
if line0[j - 1].strip('\n') == '5':
line[j] = '9'
if line0[j + 1].strip('\n') == '5':
line[j] = '9'
if line1[j - 1].strip('\n') == '5':
line[j] = '9'
if line1[j + 1].strip('\n') == '5':
line[j] = '9'
for j in range(1, col-1):
if line[j].strip('\n') == '-9999':
line[j] = '0'
f2.write(str(line[j]))
f2.write(' ')
f2.write('\n')
f2.close()
f.close()结果,局部如图所示:(顶部手动加了两行0缓冲,不为什么,想加)

整体如图所示:注意不要有空行(像我图里这样最后有一行空行是错的,手动检查一下就行)

③整理成cell.inp格式
代码:
f = open("cell-init.txt", "r")
f2 = open("input_cell.txt", "wt")
f2.write('C Cell.inp\n')
f2.write(
'C 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21\n')
f2.write(
'C 12345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012\n')
f2.write('C\n')
lines = f.read()
data = lines.split('\n')
row = len(data)
print(row)
for i in range(0, row):
# print(i)
f2.write('%3d ' % (row - i))
line = data[i].split()
col = len(line)
for j in range(0, col):
f2.write(str(line[j]))
f2.write(' %d ' % (row - i))
f2.write('\n')
f2.write('C\n')
f2.write(
'C 12345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789012\n')
f2.write(
'C 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21\n')
f2.close()
f.close()
结果如图所示:


2. dxdy.inp
DX和DY是Cellsize = 500;
DEPTH,BOTTOM ELEV等目前写成了固定的,其具体赋值方法有待探索。
代码:
f = open("cell-init.txt", "r")
f2 = open("input_dxdy.txt", "wt")
f2.write('C dxdy.inp file, in free format across columns\n')
f2.write('C\n')
f2.write('C I J DX DY DEPTH BOTTOM ELEV ZROUTH VEG TYPE\n')
f2.write('C\n')
lines = f.read()
data = lines.split('\n')
row = len(data)
for j in range(0, row): # Y方向-行-文件第二列
line = data[row-1-j].split()
col = len(line)
for i in range(0, col): # X方向-列-文件第一列
if line[i].strip('\n') == '5':
f2.write(' %3d %3d 500.0 500.0 5.0 -5.0 0.02 0\n' % (i+1, j+1))
f2.write('C\n')
f2.write('C I ARRAY INDEX IN X DIRECTION\n')
f2.write('C J ARRAY INDEX IN Y DIRECTION \n')
f2.write('C DX CELL DIMENSION IN X DIRECTION, METERS \n')
f2.write('C DY CELL DIMENSION IN Y DIRECTION, METERS\n')
f2.write('C DEPTH INITIAL WATER DEPTH, METERS \n')
f2.write('C BOTTOM ELEV BOTTOM BED ELEVATION, METERS\n')
f2.write('C ZROUGH LOG LAW ROUGHNESS HEIGHT, ZO, METERS \n')
f2.write('C VEG TYPE VEGETATION TYPE CLASS, INTEGER VALUE\n')
f2.close()结果如下图所示:
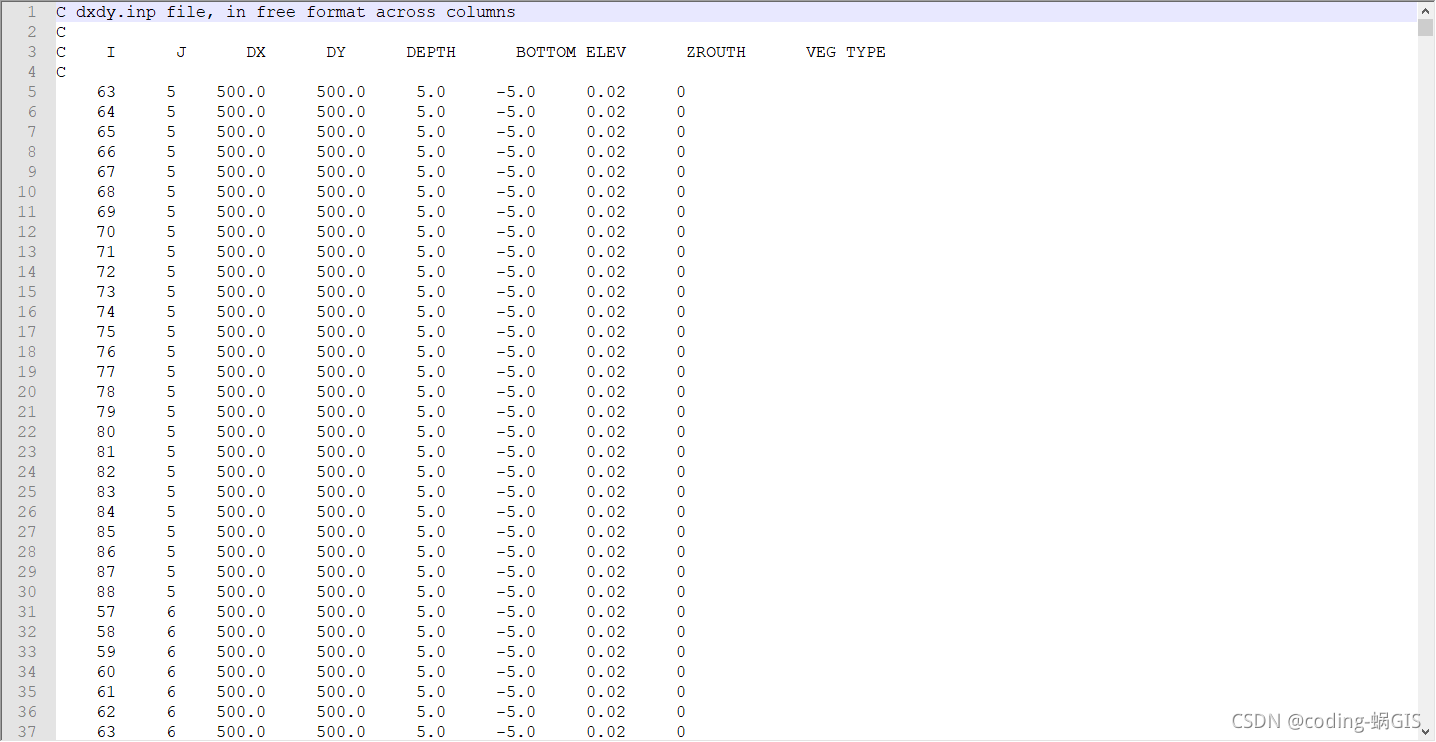
3. dxdy.inp
注意XLNUTME和YLNUTME的计算(有待考证);
CCUE等目前写成了固定的,其具体赋值方法有待探索。
代码:
f = open("cell-init.txt", "r")
f2 = open("input_lxly.txt", "wt")
f2.write('C lxly.inp file, in free format across columns\n')
f2.write('C\n')
f2.write('C I J XLNUTME YLNUTME CCUE CCVE CCUN CCVN TMPVAL\n')
f2.write('C\n')
lines = f.read()
data = lines.split('\n')
row = len(data)
for j in range(0, row): # Y方向-行-文件第二列
line = data[row-1-j].split()
col = len(line)
for i in range(0, col): # X方向-列-文件第一列
if line[i].strip('\n') == '5':
f2.write(' %3d %3d %7.1f %7.1f 1.0 0.0 0.0 1.0 -0.5000000\n' % (i+1, j+1, (i+1)*500+250, (j+1)*500+250))
# 有待讨论:上一句有错误,实际情况中不应该+250,还要结合坐标系原点
f2.write('C\n')
f2.write('C I ARRAY INDEX IN X DIRECTION\n')
f2.write('C J ARRAY INDEX IN Y DIRECTION \n')
f2.write('C XLNUTME X CELL CENTER COORDINATE, LONGITUDE, METERS,OR KM \n')
f2.write('C YLTUTMN Y CELL CENTER COORDINATE, LONGITUDE, METERS,OR KM \n')
f2.write('C CCUE ROTATION MATRIX COMPONENT \n')
f2.write('C CCVE ROTATION MATRIX COMPONENT \n')
f2.write('C CCUN ROTATION MATRIX COMPONENT \n')
f2.write('C CCVN ROTATION MATRIX COMPONENT \n')
f2.close()四. 总结
最后生成了3个网格文件
修改文件名和后缀

















 521
521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









