






ambari 是大数据平台的管理,部署,运维,监控,配置管控平台,可以实现大数据的自动安装,部署,调试,配置,监控工作,针对ambari 的监控组件聊一下。
ambari 中有单独的组件Metrics,主要是用来进行收集,存储,规则处理,监控数据服务。
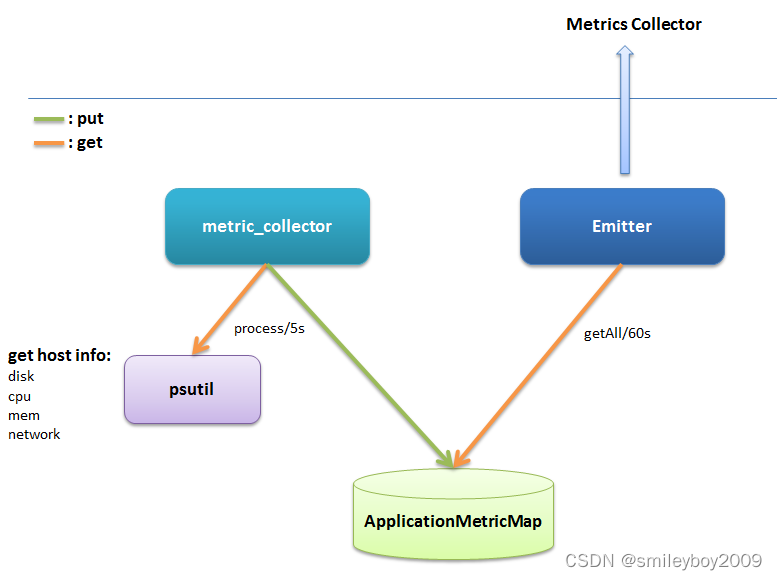
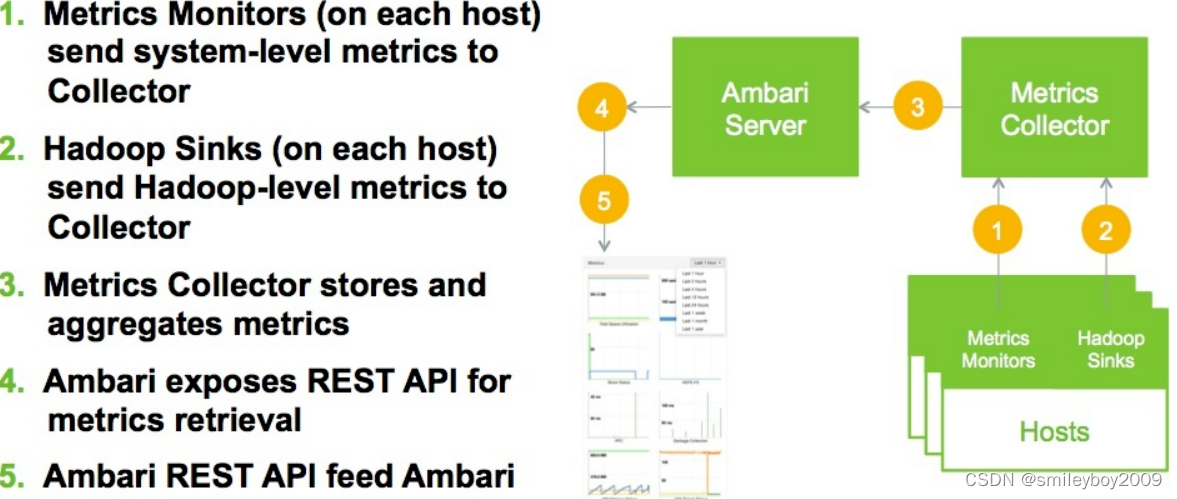
Metrics Monitor 架构图,由图中看,主要有4部分:
psutil:一个跨平台的系统信息采集 Python 模块。
metric_collector:周期性(默认为5s)采集系统信息,并存储到 ApplicationMetricMap 当中。
ApplicationMetricMap:数据容器,本地暂存采集指标。
Emitter:周期性(默认为60s)把 ApplicationMetricMap 中存储的所有监控数据,发送给 Metrics Collector。
简述一下 Metrics Monitor 的工作流程:
metric_collector 每 5s 通过 psutil 采集一次当前系统的信息(如 disk、cpu、memory、network等),并存储到 ApplicationMetricMap 当中;Emitter 每 60s 把 ApplicationMetricMap 中存储的所有监控数据,通过 HTTP POST 接口,发送给 Metrics Collector。
Metrics Sink 和 Metrics Monitor 的架构图大同小异,这里就不再展示 Metrics Sink 的架构图,
仅仅简述一下 Metrics Sink 的工作流程:
根据每个应用的实际情况,采集相应的监控指标,先暂存到本地的数据容器中,然后周期性的通过 HTTP POST 接口,发送给 Metrics Collector。
具体用法:
- 能够通过Ambari Rest API获取Metrics;
- 能够通过Ambari Web浏览Metrics图表;
- 支持自定义配置Metrics图表;
- 支持在Stack 服务里定义Metrics图表。
1.指标收集
指标分三种类型:Cluster级别,Host级别,Component级别
Cluster级别
http://:8080/api/v1/clusters/cluster-name?fields=metrics/metrics_name[time_start,time_end,step]&_=time_now
其中:
1. cluster-name为查询的集群名字;
2. metrics_name为要查询的metrics名字,如3. load,cpu,memory
4. time_start,time_end:查询的时间段起点(精确到秒)、终点,Linux事件戳
5. step:默认的时间点间隔
6. time_now:当前时间,精确到毫秒
Ambari Collector API
Ambari Collector API分为两类:Metrics操作API 和Metrics 元数据API。
Metrics操作 API
提交Metrics数据:
POST http://ambari-metrics-collector:6188/ws/v1/timeline/metrics
{
"metrics": [
{
"metricname": "{MetricsName}",
"appid": "{Unique_appid}",
"hostname": "{hostname}",
"timestamp": {cur_timestamp},
"starttime": {time_stamp},
"metrics": {
"{time_stamp}": {value},
"{next_time}": {time_stamp}
}
}
]
}其中,starttime,timestamp为时间戳,精确到毫秒,一般格式为:
{
"metrics": [
{
"metricname": "AMBARI_METRICS.SmokeTest.FakeMetric",
"appid": "amssmoketestfake",
"hostname": "ambari20-5.c.pramod-thangali.internal",
"timestamp": 1432075898000,
"starttime": 1432075898000,
"metrics": {
"1432075898000": 0.963781711428,
"1432075899000": 1432075898000
}
}
]
}
查询Metrics数据:
GET http://ambari-metrics-collector:6188/ws/v1/timeline/metrics?metricNames=MetricsName&appId=AppId&hostname=HostName&precision=seconds&startTime=StartTime&endTime=EndTime
响应数据格式:
Http response: 200 OK
Http data:
{
"metrics": [
{
"timestamp": 1432075898089,
"metricname": "AMBARI_METRICS.SmokeTest.FakeMetric",
"appid": "amssmoketestfake",
"hostname": "ambari20-5.c.pramod-thangali.internal",
"starttime": 1432075898000,
"metrics": {
"1432075898000": 0.963781711428,
"1432075899000": 1432075898000
}
}
]
}其中precision可为:Seconds(Host Metrics 10s一个点,其他30s),Minutes(5分钟),Hours(1小时),Days(1天)。另外,在获取数据时,可选择Metrics Aggregate函数(如果没有声明,则默认使用AVG),例如:
http://<AMS_HOST>:6188/ws/v1/timeline/metrics?metricNames=regionserver.Server.totalRequestCount._avg,regionserver.Server.writeRequestCount._max&appId=hbase&startTime=14000000&endTime=14200000
http://<AMS_HOST>:6188/ws/v1/timeline/metrics?metricNames=regionserver.Server.readRequestCount,regionserver.Server.writeRequestCount._max&appId=hbase&startTime=14000000&endTime=14200000另外,在Get数据时,MetrimcsName和Hostname支持使用%符进行匹配,获取一系列的Metrics,例如:
http://<AMS_HOST>:6188/ws/v1/timeline/metrics?metricNames=regionserver.Server.%&appId=hbase&startTime=14000000&endTime=14200000
http://<AMS_HOST>:6188/ws/v1/timeline/metrics?metricNames=regionserver.Server.%&hostname=abc.testdomain124.devlocal&appId=hbase&startTime=14000000&endTime=14200000
http://<AMS_HOST>:6188/ws/v1/timeline/metrics?metricNames=master.AssignmentManger.ritCount,regionserver.Server.%&hostname=abc.testdomain124.devlocal&appId=hbase&startTime=14000000&endTime=14200000
http://<AMS_HOST>:6188/ws/v1/timeline/metrics?metricNames=regionserver.Server.%&hostname=abc.testdomain12%.devlocal&appId=hbase&startTime=14000000&endTime=14200000
Metrics 元数据API
获取App id列表及App id下的Metrics列表
Get http://<AMS_HOST>:6188/ws/v1/timeline/metrics/metadata
获取所有主机注册的Hosts列表
Get http://<AMS_HOST>:6188/ws/v1/timeline/metrics/hosts
2.指标配置
Stack里定义Metrics图表
以为Hive添加metrics数据为例。使用的HDP stack版本为2.5。步骤如下:
1)修改metainfo.xml,添加timelineappid值,如在stack 2.5 metainfo中添加定义(覆盖common-services中的默认设置)
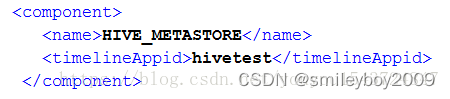
2)编写metrics.json文件

3)编写widgets.json文件

4)编写程序,发送数据到Ambari Metrics Collector中,看sink部分代码。
从Ambari中获取Metrics图表数据,进行调试
获取Service Metrimcs 定义:http://<ambari-server>:<port>/api/v1/stacks/<stackName>/versions/<stackVersion>/services/<serviceName>/artifacts/metrics_descriptor
例如:http://localhost:8080/api/v1/stacks/HDP/versions/2.3/services/HDFS/artifacts/metrics_descriptor
获取Cluster/Host Metrics 定义:http://<ambari-server>:<port>/api/v1/stacks/<stackName>/versions/<stackVersion>/artifacts/metrics_descriptor
例如:http://localhost:8080/api/v1/stacks/HDP/versions/2.3/artifacts/metrics_descriptorSink实现举例
一个简单的Metrics sink,在host上发送metric数据到metrics collector中。
#!/bin/sh
# sh sink.sh node1 test1 hikvis
url=http://$1:6188/ws/v1/timeline/metrics
while [ 1 ]
do
millon_time=$(( $(date +%s%N) / 1000000 ))
random=`expr $RANDOM % 10`
json="{
\"metrics\": [
{
\"metricname\": \"$2\",
\"appid\": \"$3\",
\"hostname\": \"localhost\",
\"timestamp\": ${millon_time},
\"starttime\": ${millon_time},
\"metrics\": {
\"${millon_time}\": ${random}
}
}
]
}"
echo $json |tee -a /root/my_metric.log
curl -i -X POST -H "Content-Type: application/json" -d "${json}" ${url}
sleep 5
done3.指标存储
基础指标存储
AMS采集到的服务指标通过http/https的方式推送到timeline server,timeline server内部嵌入了一个hbase,通过phoenix(nosql之上的sql查询)将指标数据存入到hbase中。
Hbase库中总共有7张表,其相应表名如下表所示。
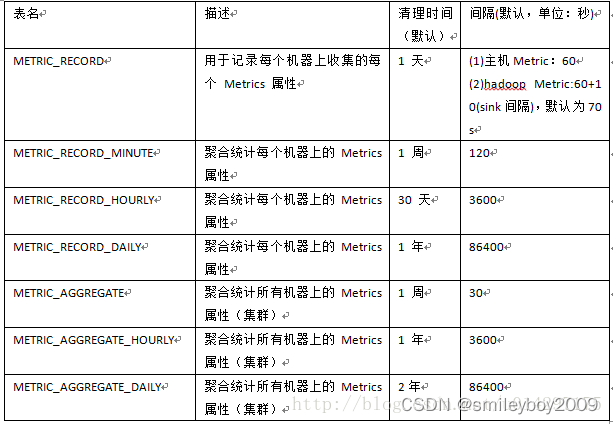
虽然库中一共有7张表,但是实际存储指标数据的只有METRIC_RECORD表,其它各表是在其基础之上做相应的统计及聚合而成的,下表是METRIC_RECORD表详细说明。
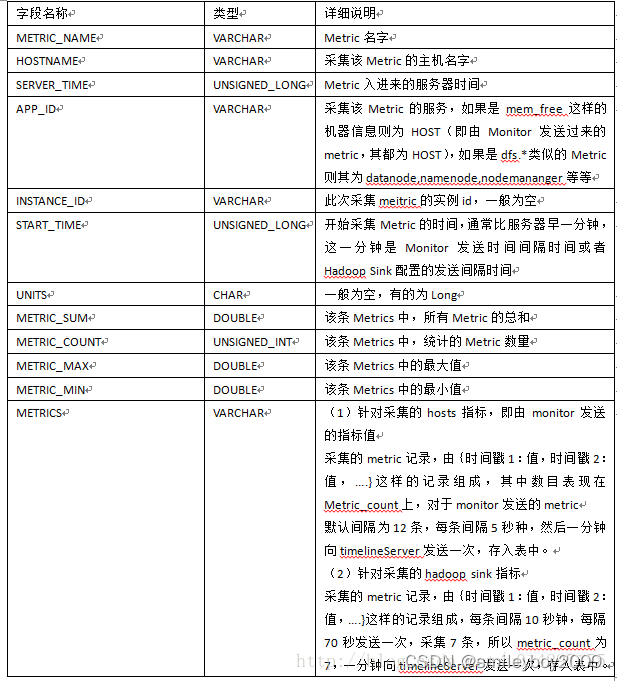
该表是所有表中唯一存储实际metrics数据的表,其它表都是在此表的基础之上进行时间段的相应统计。
(1)针对采集的hosts指标,即由monitor发送的指标值
采集的metric记录,由{时间戳1:值,时间戳2:值,….}这样的记录组成,其中数目表现在Metric_count上,对于monitor发送的metric。为12条,每条间隔5秒种,然后一分钟向timelineServer发送一次,存入表中。
(2)针对采集的hadoop sink指标
采集的metric记录,由{时间戳1:值,时间戳2:值,….}这样的记录组成,每条间隔10秒钟,每隔70秒发送一次,采集7条,所以metric_count为7,一分钟向timelineServer发送一次,存入表中。
表METRIC_RECORD_MINUTE是按分钟进行统计的,默认一次统计时间是5min(可配置),该表实则是以METRIC_RECORD表的数据作为统计的基准。下表对METRIC_RECORD_MINUTE做了详细说明。
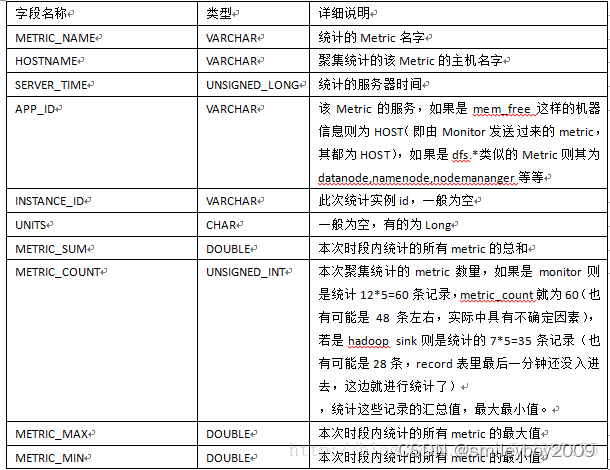
假设5分钟统计一次,以mem_free为例,则本次统计是以主机为单位,假设在metric_record表中,某主机每隔一分钟发送一条mem_free的Record,一条record中有12条metric values,则本次统计共有5条Record,metric_count则为60条。同样的,这五分钟内的最大,最小和总和,只需要比对提取Metric_record中这60条的Record的最大,最小,以及5条总和即能统计出这5分钟内相应的属性。
类似于这样几条语句得以统计:
(1)select hostname,max(metric_max) from metric_record where metric_name='mem_free' and server_time>=1471503845324 and server_time<1471504146520 group by hostname;------统计5分钟内,每台主机上该metric的最大值。
(2)select hostname,min(metric_min) from metric_record where metric_name='mem_free' and server_time>=1471503845324 and server_time<1471504146520 group by hostname; ------统计5分钟内,每台主机上该metric的最小值。
(3)select hostname,sum(metric_sum) from metric_record where metric_name='mem_free' and server_time>=1471503845324 and server_time<1471504146520 group by hostname; ------统计5分钟内,每台主机上该metric值总和。
(4)select hostname,sum(metric_count) from metric_record where metric_name='mem_free' and server_time>=1471503845324 and server_time<1471504146520 group by hostname; ------统计5分钟内,每台主机上统计的该metric数量和。至于METRIC_RECORD_HOURLY以及METRIC_RECORD_DAILY表其原理均是参照MINUTE表的原理,只是时间区间扩大了,已经参照的数据表变更了,METRIC_RECORD_HOURLY以METRIC_RECORD_MINUTE的数据为基准,而METRIC_RECORD_DAILY则以METRIC_RECORD_HOURLY的数据为基准进行统计,在此就不再描述了
AMS指标聚集
上文中所统计的7张表,除了以METRIC_RECORD前缀的表之外,还有METRIC_AGGREGATE作为前缀的表,这就是集群的指标聚集表,在聚集表中不区分host,只是以service(APP_ID)
进行分组统计,其数据来源也是从METRIC_RECORD表中进行查询后然后再进行聚集的,下表是表字段的详细说明。
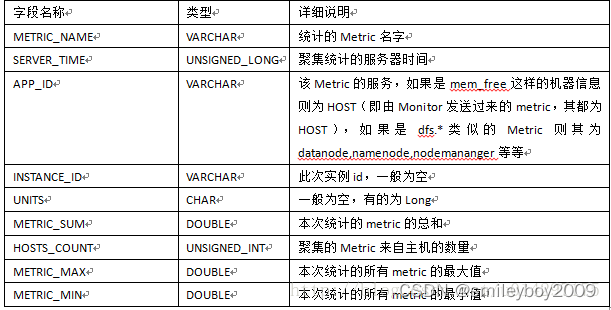
以Metric_Name为主要指标,由于是集群级别的统计,所以不再有HOSTNAME相关字段的说明,在此表中增加了HOSTS_COUNT的字段,即聚集的Metric来自主机的数量。
实际中不存在表METRIC_AGGREGATE_MINUTE,但是在图3-1中可以看到一个单独的TimelineMetricClusterAggregatorMinute聚集线程类,每2分钟聚集一次,其聚集结果采取了分片的方式,30秒一个片区记录,即0-30秒,30-60秒,60-90秒,90-120秒分成4个片区,每个时间段采集的记录分别存到对应的片区记录中,而各个片区记录直接存入到METRIC_AGGREGATE表中,该表间隔记录为30秒一条,是在表METRIC_AGGREGATE_MINUTE的基础之上进行分片的,之所以这么设定,也是为了防止频繁的聚集对AMS造成过大负载。
指标规则配置
指标的配置在ambari 的堆栈里面
堆栈定义可在源树中的处找到/ambari-server/src/main/resources/stacks。安装Ambari-server后,可以在以下位置找到stack的定义结构/var/lib/ambari-server/resources/stacks
结构
Stack definition的目录一般在/var/lib/ambari-server/resources/stacks,定义结构如下
|_ stacks
|_ <stack_name>
|_ <stack_version>
metainfo.xml
|_ hooks
|_ repos
repoinfo.xml
|_ services
|_ <service_name>
metainfo.xml
metrics.json
|_ configuration
{configuration files}
|_ package
{files, scripts, templates}
这里需要配置三个文件:
metainfo.xml, metrics.json和widgets.json
一、metainfo.xml
在 metainfo.xml 文件内的 <componment> 里面增加 <timelineAppid> 标签,如下述代码所示:
<timelineAppid>flink</timelineAppid>
这里需要注意字段 timelineAppId,该值是唯一的,一般用 Service Name 即可,并且不区分大小写。Metrics Collector 中的 Tmeline Server 会通过 timelineAppid 区分各个服务的 Metrics 信息
二、添加自定义监控信息
以 ES服务为例,如果要添加服务监控指标并展示的话,大概分为3步:
- 通过 widgets.json 文件定义服务 widgets 。
- 通过 metrics.json 文件声明服务指标。
将服务指标推送到 Ambari Metrics Collector 中
1、服务仪表板 widgets.json
Ambari 支持 4 种 widget 类型:
-
Graph
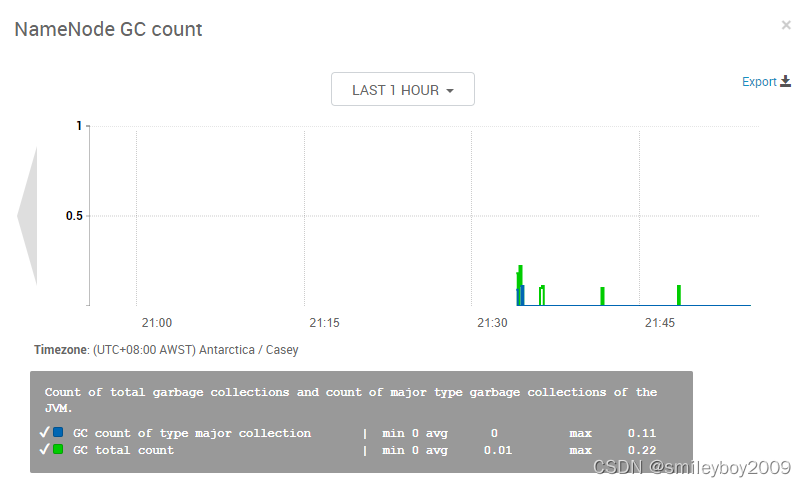
{
"widget_name": "NameNode GC count",
"description": "Count of total garbage collections and count of major type garbage collections of the JVM.",
"widget_type": "GRAPH",
"is_visible": true,
"metrics": [
{
"name": "jvm.JvmMetrics.GcCount._rate", // 数据推送到collector的实际名称。
"metric_path": "metrics/jvm/gcCount._rate", // 这个路径和metrics.json文件的metricKey要保持一致(去掉._rate的部分)
"service_name": "HDFS", // 服务名
"component_name": "NAMENODE", // 组件名
"host_component_criteria": "host_components/metrics/dfs/FSNamesystem/HAState=active" // 可选参数,该值为主机指标,不加这个参数的话,就是服务指标
},
{
"name": "jvm.JvmMetrics.GcCountConcurrentMarkSweep._rate",
"metric_path": "metrics/jvm/GcCountConcurrentMarkSweep._rate",
"service_name": "HDFS",
"component_name": "NAMENODE",
"host_component_criteria": "host_components/metrics/dfs/FSNamesystem/HAState=active"
}
],
"values": [
{
"name": "GC total count", // 该字段仅用于“GRAPH图形”窗口小部件类型。作为放大图例中的标签名称。
"value": "${jvm.JvmMetrics.GcCount._rate}" // 这是用来计算数据集值的表达式。表达式包含对声明的度量名称和作为有效操作数的常量的引用。表达式还包含一组有效的运算符{+、-、*、/},可以与有效的操作数一起使用。表达式中也允许使用括号。
},
{
"name": "GC count of type major collection",
"value": "${jvm.JvmMetrics.GcCountConcurrentMarkSweep._rate}"
}
],
"properties": { // 包含显示单位、阈值标识等等
"graph_type": "LINE",
"time_range": "1"
}
}
Graph 支持单位显示:常用的有 ms,% 等,用 display_unit 定义。
-
Gauge

{
"widget_name": "heap使用内存的百分比",
"description": "heap使用内存的百分比,当值达到75%的时候开始GC",
"widget_type": "GAUGE",
"is_visible": true,
"metrics": [
{
"name": "heap.used.memory",
"metric_path": "metrics/heap/used/memory",
"service_name": "ELASTICSEARCH",
"component_name": "ELASTICSEARCH_SERVICE"
},
{
"name": "heap.max.memory",
"metric_path": "metrics/heap/max/memory",
"service_name": "ELASTICSEARCH",
"component_name": "ELASTICSEARCH_SERVICE"
}
],
"values": [
{
"name": "heap used memory",
"value": "${heap.used.memory/heap.max.memory}"
}
],
"properties": {
"error_threshold": "0.9",
"warning_threshold": "0.75"
}
}
-
Number

{
"widget_name": "Under Replicated Blocks",
"description": "Number represents file blocks that does not meet the replication factor criteria. Its indicative of HDFS bad health.",
"widget_type": "NUMBER",
"is_visible": true,
"metrics": [
{
"name": "Hadoop:service=NameNode,name=FSNamesystem.UnderReplicatedBlocks",
"metric_path": "metrics/dfs/FSNamesystem/UnderReplicatedBlocks",
"service_name": "HDFS",
"component_name": "NAMENODE",
"host_component_criteria": "host_components/metrics/dfs/FSNamesystem/HAState=active"
}
],
"values": [
{
"name": "Under Replicated Blocks",
"value": "${Hadoop:service=NameNode,name=FSNamesystem.UnderReplicatedBlocks}"
}
],
"properties": {
"warning_threshold": "0",
"error_threshold": "50"
}
}
Number 支持单位显示:常用的有 ms,min,d 等,用 display_unit 定义。
- Template

{
"widget_name": "Elasticsearch集群节点的存活占比",
"description": "Elasticsearch集群节点的存活占比,存活个数/总个数",
"widget_type": "TEMPLATE",
"is_visible": true,
"metrics": [
{
"name": "nodes.number._max",
"metric_path": "metrics/nodes/number._max",
"service_name": "ELASTICSEARCH",
"component_name": "ELASTICSEARCH_SERVICE"
},
{
"name": "total.nodes.number._max",
"metric_path": "metrics/total/nodes/number._max",
"service_name": "ELASTICSEARCH",
"component_name": "ELASTICSEARCH_SERVICE"
}
],
"values": [
{
"name": "the number of nodes",
"value": "${nodes.number._max} / ${total.nodes.number._max}"
}
]
}
二,指标的聚合函数
聚合功能只与服务组件级度量相关,不支持主机组件级度量。
共支持四种聚合类型:
- max:所有主机组件的指标最大值
- min:所有主机组件中指标的最小值
- avg:所有主机组件的指标平均值
- sum:所有每个主机组件的度量值总和
组件部署在各节点上,每个节点都要向 metrics collector 发送自己的指标数据,然后展示的时候,就会根据各主机的指标值聚合展示
三,metrics.json

假如我们写好了上面讲述的 widgets.json 和 metrics.json 文件以后,还需要将这两个文件放到 /var/lib/ambari-server/resources/stacks/HDP/3.1/services/ELASTICSEARCH 目录下。然后重启 ambari-server,最后重新安装 Elasticsearch 服务即可。最终效果如下
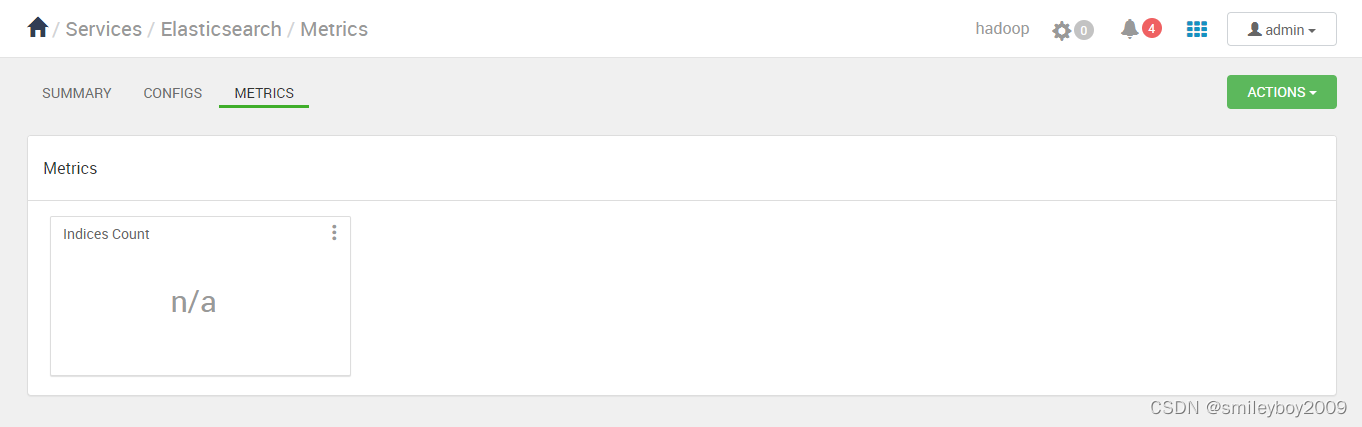
向 Ambari Metrics Collector 发送指标数据
到此,我们就已经看到了预定义的 Indices Count 控件。或许大家会好奇,为什么控件会显示没有可用的数据。很简单,因为我们还没有为该 Elasticsearch Service 实现收集与发送 Metrics 数据。
前面我们已经介绍过,AMS 中有 Metrics Monitor 以及 Hadoop Sinks 收集相关的 Metrics 数据,但这些并不会服务于第三方服务。HDFS Service 之所以可以看到相关的 Widget 数据,也是因为 Ambari 为其实现了对应 Hadoop Sinks。简单点说,Hadoop Sink 就是一个 jar 包,其 Java 代码中会实现一个 Http Client 的线程,定期的收集和发送相关的数据。而 Metrics Monitor 也是 Ambari 在后台通过 Shell 脚本启动的一个 Python 进程,其通过 url 类库实现了 Http 的 Client,定期向 Collector 发送数据。这里我通过 curl 命令向 Collector 发送指标数据。
1)通过 postman 向 metrics collector 发送指标数据:
{
"metrics": [
{
"metricname": "indices.count2",
"appid": "elasticsearch",
"hostname": "hdp2.com",
"timestamp": 1612608282778,
"starttime": 1612608282778,
"metrics": {
"1612608282778": 333
}
}
]
}
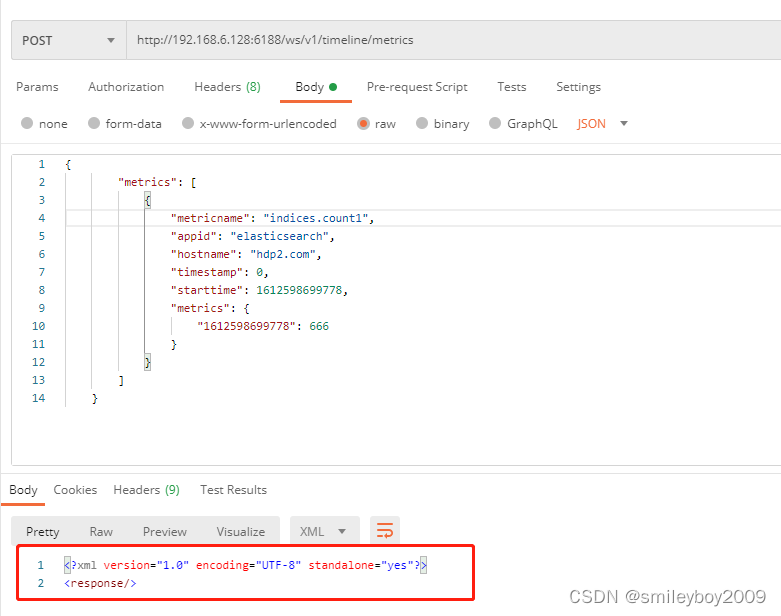
在正式 ELASTICSEARCH 服务里面,我写了一个 python 脚本来做 POST 请求。循环做,每隔多长时间就发送一次请求。
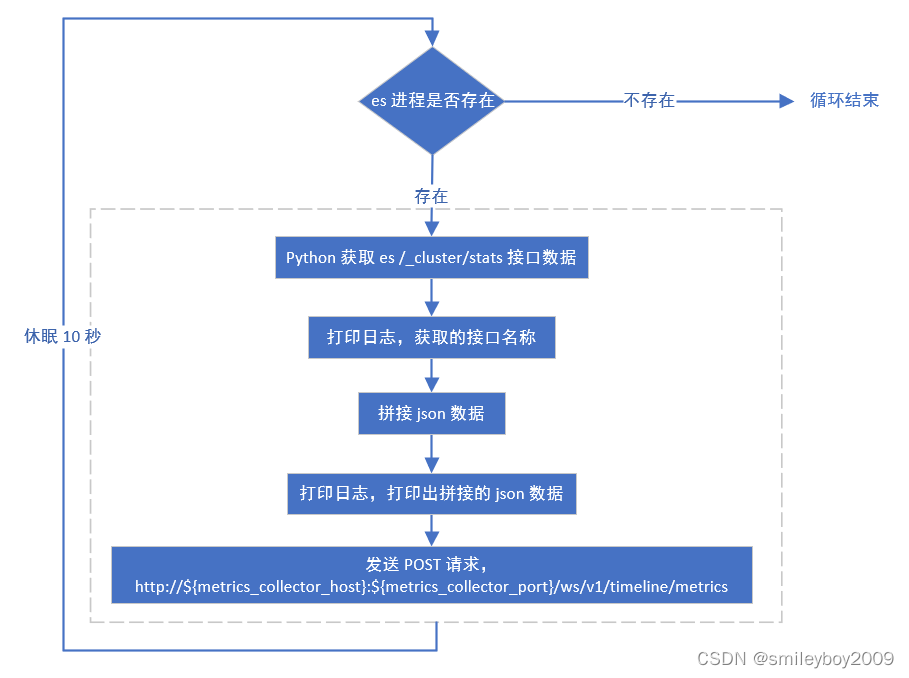
2)根据 api 接口查看指标详情
http://192.168.6.128:6188/ws/v1/timeline/metrics?metricNames=indices.count1&appId=elasticsearch注意大小写,是 appId 。
- indices.count1 为 metrics.json 文件的 metric 属性值。
- elasticsearch 为 metainfo.xml 文件的 component -> timelineAppid 属性值。
- 指标数据发送到 metrics collector 后,到展示,有约4分钟的延时
指标展示
Ambari Web 通过Ambari Server相关的接口,获取Metrics信息并负责显示。其中,具体的显示、管理是通过Widget进行操作的。简单理解,Widget是对Metrics的合并、分析后进行显示,如可在一个Widget图表中显示多个Metrics信息,或者根据Metrics的值决定显示的结果
页面展示:
在页面指标添加组件
可以在下面添加自己的自定义指标组件,支持不同的图标
点击添加小插件

添加表达式:可以根据指标自由组合:
相关数据表
(这里Ambari底层使用的是MySQL数据库)
相关的数据表包括:widget,widget_layout,widget_layout_user_widget。其中,各个数据表存储的数据接口如下所示:
1. widget表 :存储所有的widget定义员数据,包括id,widget_name, 对应的Metrics,widget_values,properties等数据;
2. widget_layout表:记录显示面板元数据。每个服务包括两个大的显示面板,serviceName_summary和serviceName_heatmap。另外,每个用户的又有自己的widget_layout,即每个用户可以自定义自己感兴趣的监控图表。如系统中存储用户admin,test用户,则可能有hdfs_summary和serviceName_heatmap两个section,其中对于hdfs_summary section,存在admin_hdfs_dashboard、test_hdfs_dashboard、admin_hdfs_heatmap和test_hdfs_heatmap (另外,在数据库中,当test用户访问了hdfs heapmap监控区,数据表中才会创建出test_hdfs_heatmap layout这条记录)。在widget_layout数据表中主要存储用户图表监控区的元数据,如id ,layout_name, section_name等。
相关API
查询所有的widget:
get http://ambari_server:port/api/v1/clusters/ClusterName/widgets/
或:
get http://ambari_server:port/api/v1/clusters/ClusterName/widgets?widgetinfo/scope=USER&widgetinfo/author=admin&fields=*根据widge ID 查询某个widget 信息:
get http://ambari_server:port/api/v1/clusters/ClusterName/widgets/widget_id对某个section中的 widget进行变更,保留列表中的Metrics(可用此API 在section中添加、删除metrics:
put http://ambari_server:port/api/v1/clusters/ClusterName/widget_layouts/section_id -d
'{
"WidgetLayoutInfo":{"dispaly_name": "Standard Storm Dashboard",
"layout_name":"layout_name",
"scope":"USER",
"section_name":"STORM_SUMMARY",
"widgets":[{"id":133},{"id":134}]
}
}'
获取某个section中活跃的widget列表
get http://ambari_server:port/api/v1/users/admin/activeWidgetLayouts?WidgetLayoutInfo/section_name=section_name目前Ambari 中hdfs,storm,kafaka,yarn定义了Widget,section_name可为hdfs_summary,yarn_summary,storm_summary,yarn_summary,kafaka_summary,yarn_summary,hdfs_heatmap,yarn_heatmap,storm,yarn_heatmap,kafaka_heatmap,yarn_heatmap
其他
Ambari Metrics 白名单
默认白名单位于/etc/ambari-metrics-collector/conf.目录下,可通过 ams-site 中的配置项 timeline.metrics.whitelist.file =path_to_whitelist_file进行配置
Metrics 数据存储
默认情况下,Metrics数据存储在HBase中,使用的是Metrics内置的HBase,且该HBase是单节点模式。
进入Metrics HBase
在Metrics Collector节点,进入目录/usr/lib/ams-hbase/bin目录下,运行:
./hbase –config /etc/ams-hbase/conf shell即可进入hbase shell。
通过Phoenix连接HBase
在Metrics Collector节点,进入目录/usr/lib/ambari-metrics-collector/bin目录下,运行:
./sqlline.py localhost:61181 即可进入Phoenix。
Ambari Metrics Collector 架构
Metrics Collector 架构图,由图中看,主要有4部分:
TimelineWebServices:是一个Web服务,一方面提供 Metrics Monitor 和 Metrics Sink 汇报监控数据的 POST 接口;另一方面提供 Ambari Server 查询监控数据的 GET 接口。
TimelineMetricStore:周期性聚合数据。
Phoenix:是一个开源工具库,可以把 SQL 语句转换为 HBase 的操作语句。
HBase:存储监控数据的地方,HBase 有两种工作模式:Embedded Mode,单机模式,数据存储在本地文件系统中;Distributed Mode,分布式模式,数据存储在 HDFS 中。目前 Metrics 服务默认是 Embedded Mode,安装之后可通过修改参数进行调整。
简述一下 Metrics Collector 的工作流程:
1、存储监控数据:Metrics Monitor/Sink,通过 POST 接口汇报监控数据,TimelineWebServices 根据收到的监控数据生成 SQL 语句,然后通过 Phoenix 把 SQL 转换为 HBase 的操作语句,把监控数据存储到 HBase 当中(原始监控数据都存储到 METRIC_RECORD 表中)。
2、查询监控数据:Ambari Server 根据 GET 接口查询监控数据,TimelineWebServices 根据查询条件生成 SQL 语句,然后通过 Phoenix 把 SQL 转换为 HBase 的操作语句,查询出符合条件的监控数据。
3、周期性聚合数据:Metrics Monitor 和 Metrics Sink 上传的原始监控数据粒度是秒级的,TimelineMetricStore 通过运行周期任务,可以聚合出分钟级、小时级、天级的监控数据。
Metrics 表分为两类:主机级别和集群级别,然后不同粒度是不同的表,具体如下:
Host 级别:
METRIC_RECORD 秒级
METRIC_RECORD_MINUTE 分级
METRIC_RECORD_HOURLY 时级
METRIC_RECORD_DAILY 天级
Cluster 级别:
METRIC_AGGREGATE 分级
METRIC_AGGREGATE_HOURLY 时级
METRIC_AGGREGATE_DAILY 天级
简单介绍一下 METRIC_RECORD 的表结构,其他表的结构大同小异。
METRIC_RECORD 表结构:
METRIC_NAME 指标名
HOSTNAME 主机名
APP_ID 应用名
INSTANCE_ID 实例ID,如果一台 HOST 安装了多个同样的应用
UNITS 数据类型,如:Number
SERVER_TIME 记录保存时间
START_TIME 本次 METRICS 最小的时间
METRICS 具体指标,如:{"1490605303":"149491.1875","1490605313":"149591.1875"}
METRIC_SUM METRICS value的总数
METRIC_COUNT METRICS 记录的数量
METRIC_MAX METRICS 中最大的 value
METRIC_MIN METRICS 中最小的 value
简单介绍一下 数据聚合 的实现方式,是通过执行如下的 SQL 进行聚合的:
Host 级别数据聚合:
UPSERT INTO 'METRIC_RECORD_MINUTE' (METRIC_NAME, HOSTNAME, APP_ID, INSTANCE_ID, SERVER_TIME, UNITS, METRIC_SUM, METRIC_COUNT, METRIC_MAX, METRIC_MIN) SELECT METRIC_NAME, HOSTNAME, APP_ID, INSTANCE_ID, MAX(SERVER_TIME), UNITS, SUM(METRIC_SUM), SUM(METRIC_COUNT), MAX(METRIC_MAX), MIN(METRIC_MIN) FROM 'METRIC_RECORD' WHERE SERVER_TIME >= 'startTime' AND SERVER_TIME < 'endTime' GROUP BY METRIC_NAME, HOSTNAME, APP_ID, INSTANCE_ID, UNITS
Cluster 级别数据聚合:
UPSERT INTO 'METRIC_AGGREGATE' (METRIC_NAME, APP_ID, INSTANCE_ID, SERVER_TIME, UNITS, METRIC_SUM, METRIC_COUNT, METRIC_MAX, METRIC_MIN) SELECT METRIC_NAME, APP_ID, INSTANCE_ID, MAX(SERVER_TIME), UNITS, SUM(METRIC_SUM), SUM(METRIC_SUM), MAX(METRIC_MAX), MIN(METRIC_MIN) FROM METRIC_RECORD WHERE SERVER_TIME >= 'startTime' AND SERVER_TIME < 'endTime' GROUP BY METRIC_NAME, APP_ID, INSTANCE_ID, UNITS
参考文献:
Ambari Metrics(相关API,底层数据库,widget等)_ambari 的图表怎么自定义-CSDN博客
https://download.csdn.net/blog/column/10495577/117652135















 4203
4203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









