









对话中的情感分析(三)
CAN-GRU: a Hierarchical Model for Emotion Recognition in Dialogue
文献概述
研究背景:
对话中情感识别当前挑战(背景):
1.话语长度:长话语就很难捕捉到上下文信息;
2.长期上下文关系:对话中包含大量话语,导致难以把握话语间的长期语境关系。
3.词语情感多样性:同词不同语境表示不同语义。
研究内容:
本文主要专注于对话文本信息的情感分析。 提出一个分层模型CAN-GRU识别对话中的情感: 第一层:convolutional
self-attention
network(CAN)卷机子注意力网络,提取话语中文本特征。使用卷积捕获n-gram信息,使用attention
mechanism注意力机制捕获话语中词间相关语义信息。 第二层:a GRU-based network捕获上下文信息。
讨论单向和双向网络影响。
研究结论:
1.在Friend数据集和EmotionPush数据集上性能由于所有基线。
2.对比bcGRU和CAN-biGRU情绪识别个例结果更准确。 加入了一个注意力机制,用于更好地捕捉话语的历史信息,结合历史和未来信息计算上下文信息的重要性,可以显著提高模型在处理长文本情感分析任务上的性能。
3.图表中比较了CAN-GRUA和CAN-biGRUA对于对话中第六个话语的情感识别和注意力分布。考虑到历史和未来信息,可以帮助模型做出更好的分类。
研究创新性:
1.第一层的卷积自注意力网络学习话语中的N-gram特征和词语之间的相关语义信息,更好捕获话语间语义关系。
2.第二层则使用基于GRU的网络来建模话语序列,并作出三种变体。
3.注意力机制可以帮助有效捕捉上下文中的长期依赖关系,且引入历史未来信息更好计算上下文信息,考虑语境。
研究不足:
仍有识别错误,特别是处理包含复杂情感和频繁情感转换的对话时,仍需继续改进。
文献相关模型与算法原理
CAN-biGRUA
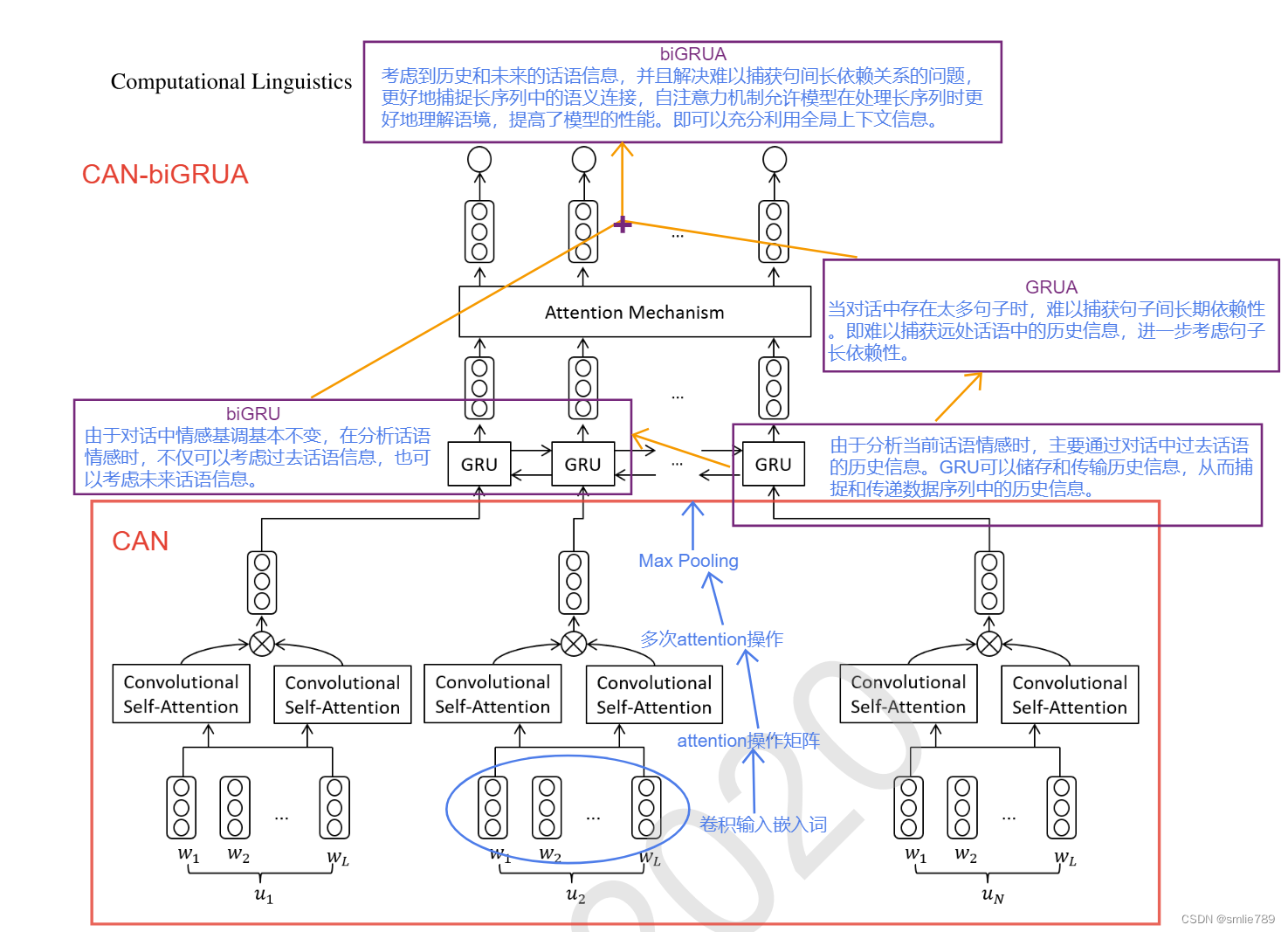
图1:我们提出的CAN-biGRUA的架构。在第一层中,使用卷积神经网络和自注意机制来提取文本特征。在第二层中,顶部具有专注架构的biGRU用于对对话中的话语序列进行建模。
第一层:
主要内容:
1.采用卷积神经网络提取utterance特征
2.采用卷积self-attention网络,即CAN代替CNN,捕获长文本上下文信息。
主要作用:
这种方法结合了卷积操作和注意力机制,用于处理在对话中捕捉语义关系的复杂性。
第一层详细结构。
其中ui表示utterance; wi表示word
步骤:
- Q,K, V embeddings 。
作用:
参与注意力操作的查询嵌入Q、键嵌入K和值嵌入V,它们可能需要不同的有效特征。在不同的卷积操作中可以提取出不同的有效信息。
操作:
对输入词嵌入进行卷积操作,代替之间使用词嵌入作为K,Q,V的嵌入。
该操作的作用:
1.参与注意力操作的查询嵌入Q、键嵌入K和值嵌入V,它们可能需要不同的有效特征。
2.在不同的卷积操作中可以提取出不同的有效信息。
公式相关解释:
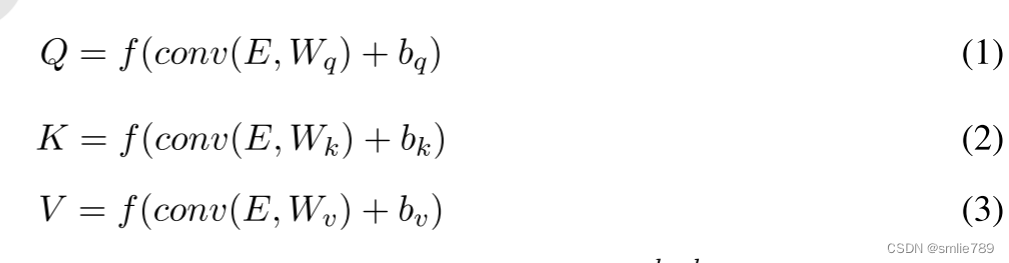
(1).E是输入词嵌入,输入词嵌入维度为(l×d),l表示句子长度,d表示嵌入维度;
(2).卷积核的维度为(w×n×d),其中w为滤波器的窗口大小,n为滤波器的特征映射数;
(3).conv为卷积操作,f为激活函数。
- 计算话语间词的语义关系,即attention操作矩阵Z
作用:计算话语内单词之间的语义关系。
操作:
缩放点积注意力操作来计算话语内单词之间的语义关系。
1.对于生成的Q和K,执行点积操作,得到权重矩阵。
2.将该权重矩阵缩放(scaled),通过√d对这个权重矩阵进行缩放。
3.Softmax操作,得到标准化的权重矩阵,该矩阵用于表示句子中单词之间的注意力程度。
4.将标准化的权重矩阵与V相乘,得到attention操作的结果矩阵Z ∈ Rl×d。
该操作的作用:
标准化的权重矩阵,用于表示句子中词与词之间的关注程度。
公式:

- 多次Attention 操作
作用:捕获更复杂的交互。
目的:
由于attention mechanisms是为创建加权平均值设计的,不能捕获复杂的交互。
操作:
1.重复(1)~(3)两次,得到Qa,Ka,Va和Qb,Kb,Vb。
2.分别对Qa,Ka,Va和Qb,Kb,Vb执行了注意力操作,得到了Za和Zb(每个都是l×d的矩阵)。
3.对Za和Zb进行逐元素级别的乘法运算,得到U(l×d)。
其中,逐元素相乘:
在矩阵或向量运算中,逐元素相乘指的是两个矩阵或向量中的相应元素一一相乘,得到一个新的矩阵或向量,其中每个元素是原始矩阵或向量中对应元素的乘积。
公式:
- 最大池化Max-Pooling操作 。
作用:
对话中的每个单词生成上下文相关的嵌入(eui),这些嵌入反映了单词与其他单词之间的语义关系。
操作:
对于U中的每个ui(1 ≤ i ≤ N),在其中的上下文单词嵌入上执行最大池化操作,得到具有最大值的维度单词级别嵌入eui。
第二层:
CAN-GRU:
采用原因:
由于分析当前话语情感时,主要通过对话中过去话语的历史信息。GRU可以储存和传输历史信息,从而捕捉和传递数据序列中的历史信息。
优点:
作为原始递归神经网络的改进模型,具有记忆和传递历史信息的能力,可以更好的利用历史信息,计算简单,性能良好。
架构:
引入重置门Rt和更新门Zt,在每个时间步(timestep)t,模型使用这两个门来控制当前隐藏状态(St)的计算。
重置门Rt:决定了需要遗忘多少过去的信息。 更新门Zt:决定了需要将多少新信息纳入计算。
这种机制允许GRU有选择性地记住或遗忘之前时间步的信息,从而能够捕捉到数据中的长程依赖关系。
计算:
在时间步t,它使用重置门Rt和更新门Zt来计算当前隐藏状态St。
输入为话语嵌入eut和前一个时间步骤的隐藏状态st−1。
其中W、b是可训练参数,⊗表示逐元素乘法。
公式:
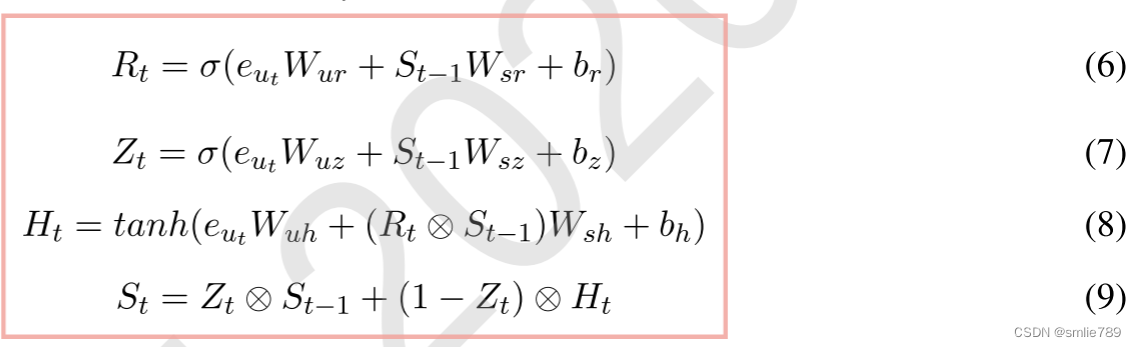
eut:作为输入,即从第一层模型得到的话语嵌入。
式子(6):Rt是重置门。它通过使用输入话语嵌入(eut)与相应的权重(Wur)、前一个时间步的隐藏状态(St−1)与相应的权重(Wsr),以及偏置项(br)进行加权求和,并通过sigmoid激活函数(σ)压缩到0和1之间。这个门控制着在当前时间步,模型需要从前一个时间步的隐藏状态中遗忘多少信息。式子(7):Zt是更新门。
类似于重置门,它也是通过输入话语嵌入、前一个时间步的隐藏状态和相应的权重,以及偏置项进行加权求和,然后通过sigmoid激活函数压缩到0和1之间。这个门控制着在当前时间步,模型需要将多少新的信息纳入计算。式子(8):Ht是当前隐藏状态。
它通过输入话语嵌入与相应的权重、重置门乘以前一个时间步的隐藏状态与相应的权重,以及偏置项进行加权求和,然后通过tanh激活函数得到。这个公式表示在考虑了重置门的情况下,模型计算的当前状态。式子(9):St是最终隐藏状态。
它通过使用更新门控制前一个时间步的隐藏状态和当前计算得到的隐藏状态的加权组合。如果更新门(Zt)接近1,模型将主要保留前一个时间步的信息。如果更新门接近0,模型将主要采纳当前计算得到的隐藏状态,这样就实现了在长时间依赖情况下的信息传递和遗忘。
CAN-GRUA:
采用原因:
当对话中存在太多句子时,难以捕获句子间长期依赖性。即难以捕获远处话语中的历史信息。
优点:
进一步考虑到句子间的长期依赖性。
架构:
在GRU上连接一个attention层。
作用:
捕获历史信息对当前话语情感的影响程度。
原理:
若attention mechanism权重趋于大,则表明先前话语对当前话语有重要影响,应该更关心先前话语。
公式:
式子(10)Attention Calculation for Current Hidden State:
这个公式计算了当前隐藏状态的attention结果(˜St)。 Si 表示时间步 i 的先前隐藏状态,αi 是权重,用来表示 Si
对当前状态的影响程度。 αi 的计算采用了下面的公式。 式子(11)Attention Weight (αi) Calculation:
αi 是注意力权重,用来衡量先前隐藏状态 Si 对当前隐藏状态 St 的影响程度。它是通过先前隐藏状态 Si 和当前隐藏状态 St
的内积进行计算。这个内积的结果被输入到指数函数中,并被归一化,以确保所有权重的总和为1。这样,权重越大的 Si
表示该句子对当前情感状态的影响越大。
CAN-biGRU:
采用原因:
由于对话中情感基调基本不变,在分析话语情感时,不仅可以考虑过去话语信息,也可以考虑未来话语信息。
优点:
从历史和未来两方面考虑,可以捕获到更丰富的上下文信息。
架构:
引入双向GRU(biGRU),同时向前和向后提取上下文特征。
CAN-biGRUA:
采用原因:
上一模型没有解决难以捕获长序列之间的语义连接的问题。
优点:
考虑到历史和未来的话语信息,并且解决难以捕获句间长依赖关系的问题,更好地捕捉长序列中的语义连接,自注意力机制允许模型在处理长序列时更好地理解语境,提高了模型的性能。即可以充分利用全局上下文信息。
架构:
biGRU的隐藏状态的顶部连接了一个自我注意层。
作用:引入自注意力机制,模型可以根据全局上下文中每个句子的重要性,有选择性地关注句子之间的语义关系。有助于模型更好地捕捉长序列中的语义连接,自注意力机制允许模型在处理长序列时更好地理解语境,提高了模型的性能。
原理: 同公式(10)(11)
公式:

St∈Rm 表示当前的隐藏状态, Si∈Rm 表示时间步 i 的隐藏状态, N 是对话中句子的数量, St~∈Rm 是时间步 t
的注意力计算结果。
情感分类
结构:
全连接层+softmax层。
输入:话语最终表示时间步t的经过自注意力计算的隐藏状态˜st;

式子(14)Compute Intermediate State: ft 是中间状态,通过对经过自注意力计算的隐藏状态 ˜St
应用权重矩阵 Wf 和偏置项 bf
进行线性变换,然后经过tanh激活函数计算得出。这个中间状态捕捉了在注意力计算后隐藏状态的更高级别的特征。 式子(15)Compute
Output State : ot 是输出状态,通过对中间状态 ft 应用权重矩阵 Wo 和偏置项 bo
进行线性变换,然后经过softmax激活函数得到。这个输出状态表示每个可能情感类别的概率分布。 式子(16)Predicted
Emotion (yˆt): yˆt 表示在时间步 t 预测的情感类别。它是在 ot
中选择概率最高的类别对应的索引,即通过argmax操作得到的。这样,模型在每个时间步都会输出一个情感类别的预测结果。
损失函数设定
问题:
情感类别不平衡。
方法:
引入加权交叉熵损失作为模型中参数优化的目标。
原理:
通过给予少数类别更高的权重,模型更加关注这些类别,从而提高了对这些类别的分类准确性。
计算公式:
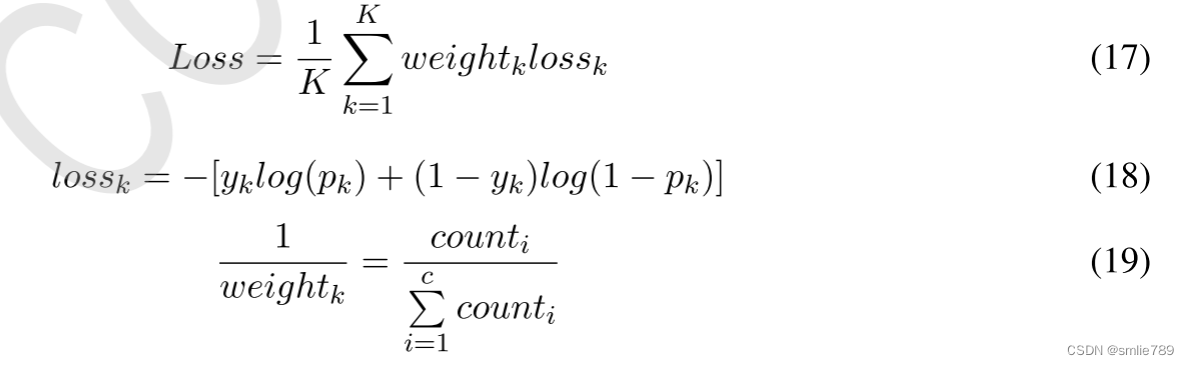
式子(17) : Weighted Cross-Entropy Loss:
损失函数的计算是通过对所有样本(从1到K)的加权损失进行平均。其中,K 是样本的总数,weightk
是样本k的损失权重,lossk是样本k的损失函数。 式子(18) : Binary Cross-Entropy Loss (lossk):
lossk是二元交叉熵损失函数的计算,用于计算单个样本k的损失。该损失函数是由实际标签yk和softmax层计算到的预测概率pk之间的交叉熵损失组成。
式子(19) : Weight Calculation (1/weightk): 1/weightk
是样本k的损失权重的倒数。它的计算取决于与样本k属于相同类别的样本总数(counti)的倒数,其中i表示样本k所属的类别,c是类别的总数。
实验
实验数据集和基线
数据集:

基线:

实验参数相关
1.Word Embeddings: 使用了预训练的300维GloVe2(Pennington等人,2014年)词嵌入。这种词嵌入是从网络数据中训练得到的。
2.卷积层(Convolutional Layers): 使用了三个不同尺寸的卷积核:分别是3、4和5。 每个卷积核的特征图数量为100。这意味着每个卷积核都会生成100个特征图,用于捕捉文本中不同尺寸的特征。
3.GRU(Gated Recurrent Unit): GRU的隐藏状态维度被设置为300。这意味着GRU层的隐藏单元有300个。
4.优化器(Optimizer): 使用了Adam优化器(Kingma和Ba,2015年)。 初始学习率设置为1.0 × 10^(-4)。 在训练期间,学习率每20个epochs减半一次。这种策略通常被称为学习率衰减,有助于模型在训练后期更精细地调整参数。
5.Dropout: Dropout概率被设置为0.3。Dropout是一种正则化技术,有助于减少过拟合风险。在每个训练步骤中,以0.3的概率随机丢弃神经元。
评价指标
UWA代替UA

使用UWA而不是WA的原因是合理的。如果数据集中存在大量的中性情绪(或任何类别),使用未加权准确度可以在不受类别分布影响的情况下,更清晰地比较不同模型或方法的性能。这在类别不平衡存在时尤为重要,因为加权准确度可能会受到较大类别的影响,导致评估结果偏斜。
通过使用UWA,可以确保一个更公平的评估,不受数据集中类别分布的影响,从而更有意义地比较不同模型的性能。
实验结果具体分析
1.在Friend数据集和EmotionPush数据集实验
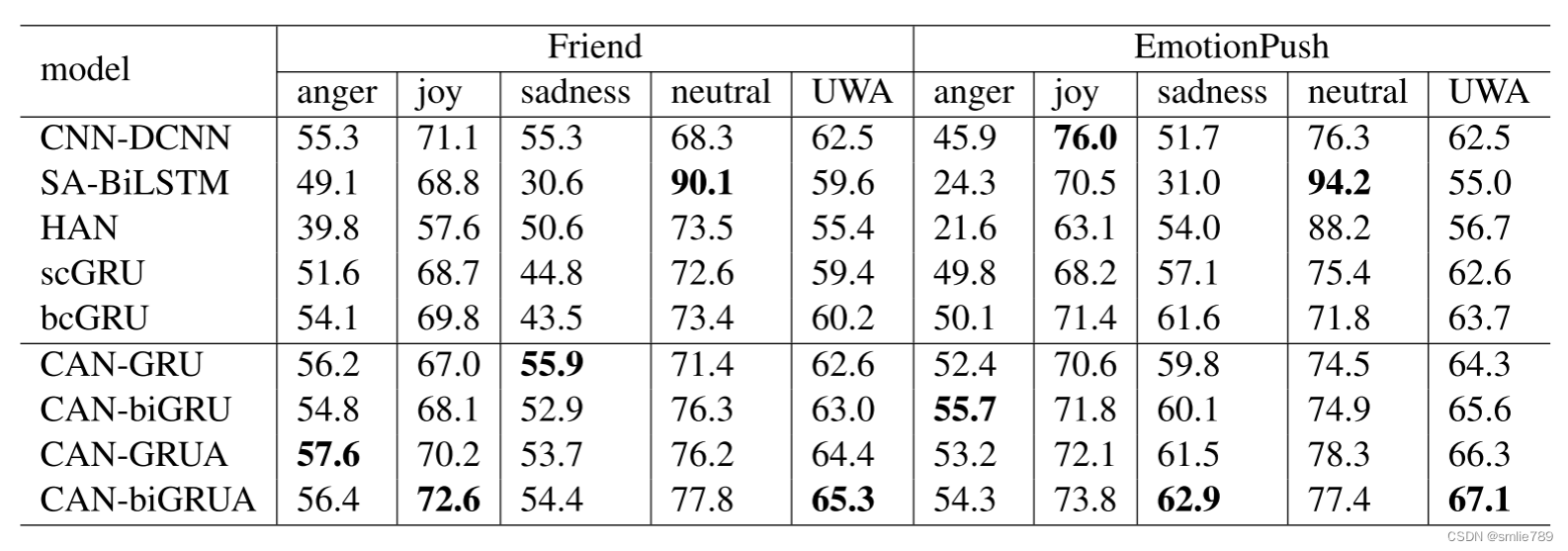
CAN-GRU:
第一层使用了卷积自注意力机制,用于提取话语(utterance)特征。这意味着模型能够自动关注每个输入序列的不同部分,这在处理长文本时特别有用。
第二层使用了GRU,用于建模话语序列。GRU是一种适合处理序列数据的循环神经网络(RNN)变体。
在Friend数据集和EmotionPush数据集上,与scGRU相比,CAN-GRU分别取得了3.2%和1.7%的性能提升。
CAN-biGRU:
与CAN-GRU相比,CAN-biGRU在第二层使用了双向GRU(biGRU)。双向GRU能够更好地捕捉输入序列的上下文信息,因为它同时考虑了过去和未来的信息。
在Friend数据集和EmotionPush数据集上,CAN-biGRU分别取得了2.8%和1.9%的性能提升,相对于bcGRU(可能是baseline模型的一种)。
这都表明这表明卷积自注意力机制能够有效地捕捉长文本中的上下文信息。
CAN-GRUA:
在CAN-GRU的基础上,加入了一个注意力机制,用于更好地捕捉话语的历史信息,并且为重要的历史信息赋予更高的权重。
在两个数据集上,CAN-GRUA分别取得了1.8%和2.0%的性能提升,相对于CAN-GRU。
这表明在GRU层之上加入注意力机制可以帮助模型更好地理解和利用历史信息。
CAN-biGRUA:
在biGRU的顶部加入了一个自注意力机制,用于在分析当前话语情感时,结合历史和未来信息计算上下文信息的重要性。
这个模型在两个数据集上都取得了最好的结果,分别提高了2.8%和4.6%相对于基线模型。
这表明在双向GRU的基础上引入自注意力机制,可以显著提高模型在处理长文本情感分析任务上的性能。
相较于BERT,性能更好,可以在BERT基础上进一步改进。
2.对比bcGRU和CAN-biGRU情绪识别结果
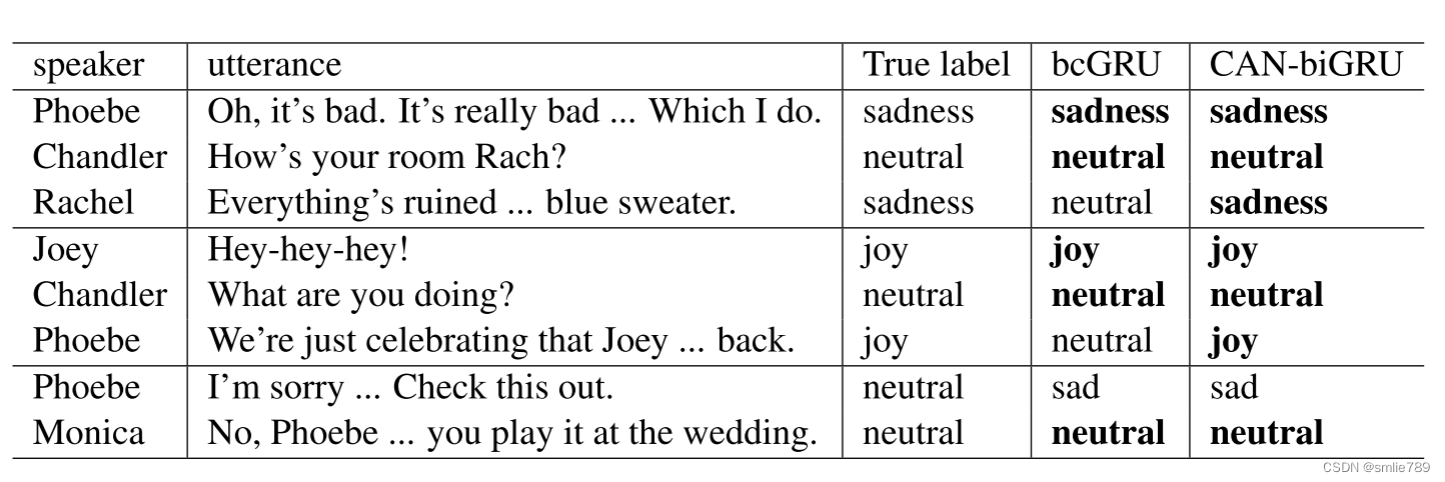
在第三种情况下,两个模型都对Phoebe所说的话语做出错误的预测,因为“对不起”这个词表达了强烈的悲伤情绪。这表明CAN在复杂的语义环境中仍然是有限的。
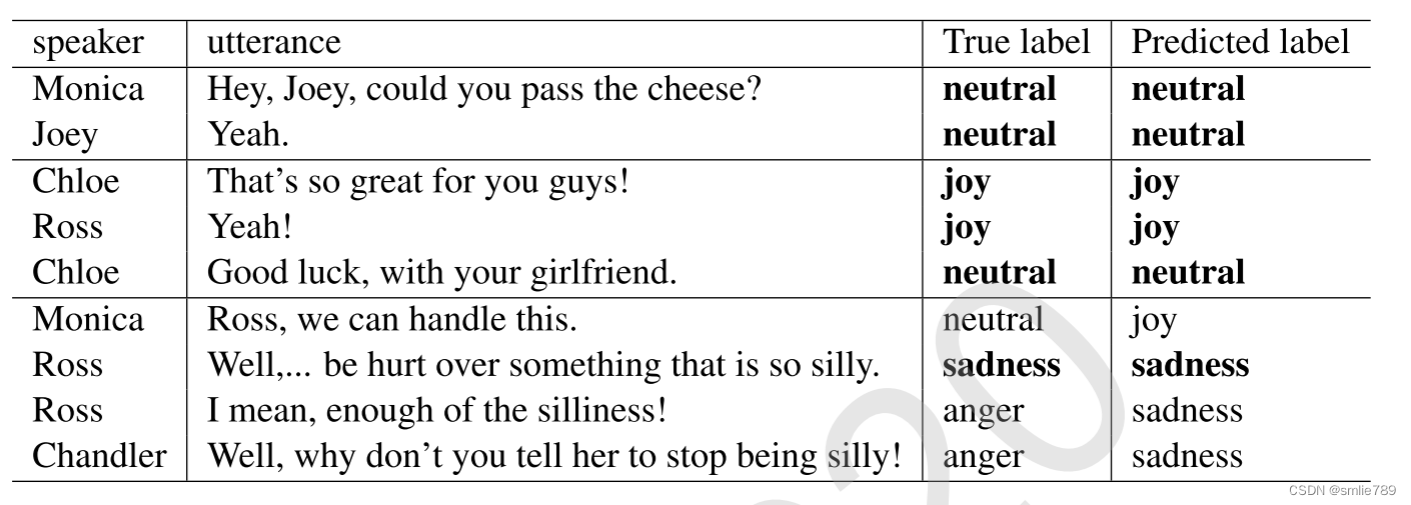
第一和第二种情况:
在第一和第二种情况中,CAN-biGRUA模型成功地识别了话语的情感类别。作者强调了‘Yeah’的不同表达方式:在Monica和Joey的对话中,‘Yeah’表达中性情感,而在Chloe和Ross的对话中,‘Yeah’伴随着‘!’表示更强烈的情感,模型有效地分析出了其中的喜悦情感。
第三种情况:
在第三种情况中,模型在对话中的第一、第三和第四个话语的情感分类上出现错误。这段对话包含了三种不同的情感,而且情感频繁变化。作者指出,模型在处理这种复杂情境时仍然存在限制,即使考虑了上下文。这表明,在情感较为复杂、频繁转换的情境下,模型的理解情感的能力仍然有待改进。
3.图表分析
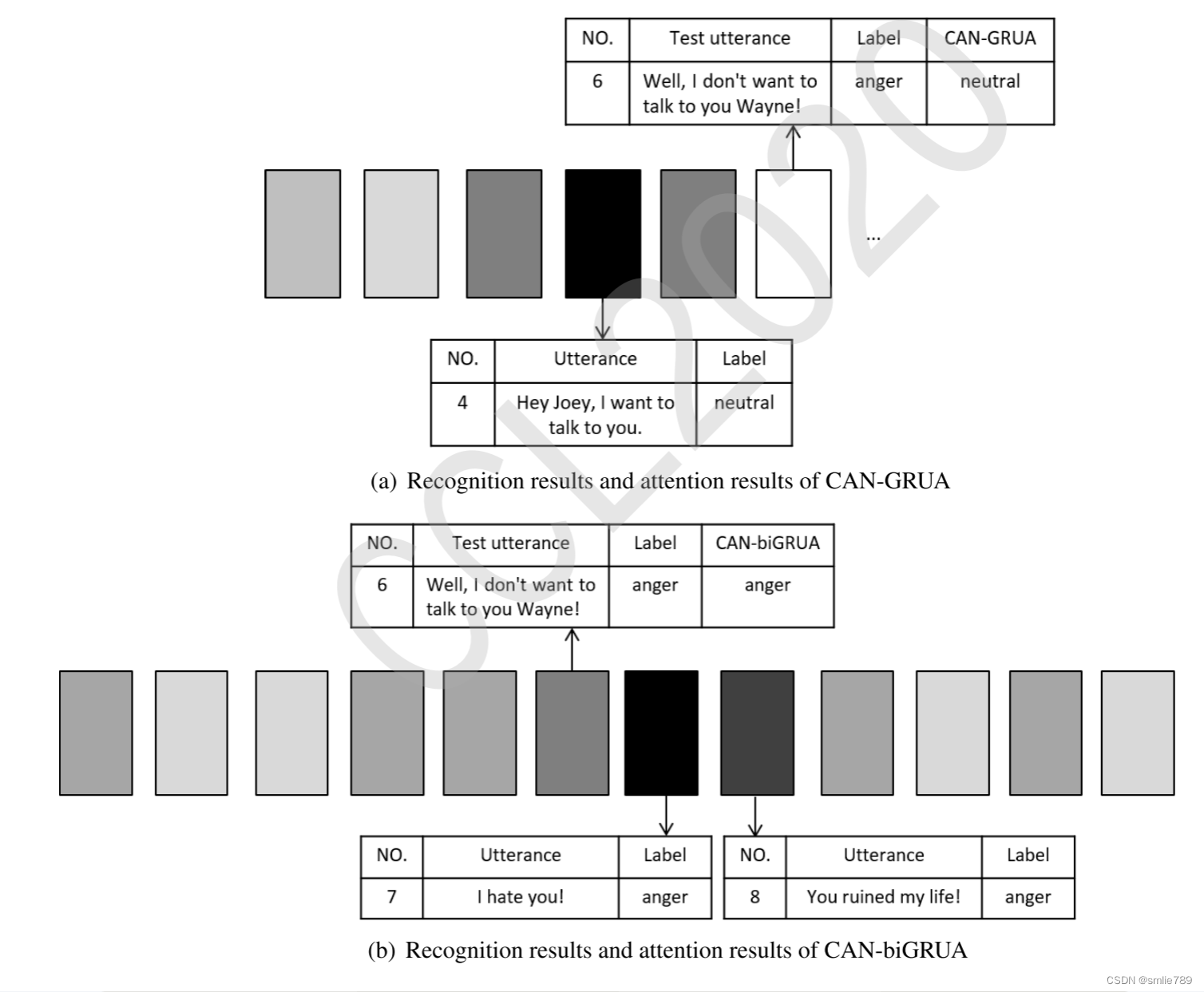
图表中比较了CAN-GRUA和CAN-biGRUA对于对话中第六个话语的情感识别和注意力分布。CAN-GRUA只使用历史信息,并且主要关注第四个话语,结果将其识别为中性情感。而CAN-biGRUA考虑了历史信息和未来信息,主要关注了第七和第八个话语,这两个话语表达了强烈的愤怒情感,因此最终将测试话语分类为愤怒情感。这个例子表明,考虑到历史和未来信息,可以帮助模型做出更好的分类。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









