







 本文详细探讨了Spark的任务调度与资源调度的区别,重点解析了资源调度的内部机制,包括Master的schedule方法调用时机、Worker的随机打乱策略以及Executor的分配逻辑。内容涉及Driver在Cluster模式下的启动、资源需求匹配、FIFO调度策略以及数据本地性优化等方面,旨在帮助读者深入了解Spark的资源分配策略。
本文详细探讨了Spark的任务调度与资源调度的区别,重点解析了资源调度的内部机制,包括Master的schedule方法调用时机、Worker的随机打乱策略以及Executor的分配逻辑。内容涉及Driver在Cluster模式下的启动、资源需求匹配、FIFO调度策略以及数据本地性优化等方面,旨在帮助读者深入了解Spark的资源分配策略。
一:任务调度与资源调度的区别
1. 任务调度:是通过DAGScheduler,TaskScheduler,SchedulerBackend等进行的作业调度;
2. 资源调度:是指应用程序如何获得资源;
3. 任务调度时在资源调度的基础上进行的,没有资源调度那么任务调度就成为了无源之水,无本之木。
二:资源调度内幕天机揭秘
1. 因为Master负责资源管理和调度,所以资源调度的方法schedule位于Master.scala这个类中,当注册程序或者资源发生改变的时候都会导致schedule的调用,例如注册程序如下:
case RegisterApplication(description, driver) => {
// TODO Prevent repeated registrations from some driver
if (state == RecoveryState.STANDBY) {
// ignore, don't send response
} else {
logInfo("Registering app " + description.name)
val app = createApplication(description, driver)
registerApplication(app)
logInfo("Registered app " + description.name + " with ID " + app.id)
persistenceEngine.addApplication(app)
driver.send(RegisteredApplication(app.id, self))
schedule()
}
}
2. schedule调用的时机:每次有新的应用程序提交或者集群资源状况发生改变的时候(包括Executor增加或者减少,Worker增加或者减少等);
/**
* Schedule the currently available resources among waiting apps. This method will be called
* every time a new app joins or resource availability changes.
*/
3. 当前Master必须是Alive的方式采用进行资源的调度,如果不是ALIVE的状态会直接返回,也就是说StandbyMaster不会进行Application的资源调度;
if (state != RecoveryState.ALIVE) { return }4. 使用Random.shuffle把Master中保留的集群中所有Worker的信息随机打乱;为啥要打乱?为了负载均衡。
// Drivers take strict precedence over executors
val shuffledWorkers = Random.shuffle(workers) // Randomization helps balance drivers
5. Shuffle源码详解:
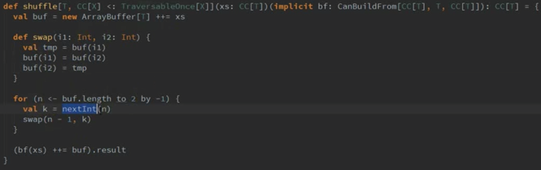
将worker存入到ArrayBuffer中并赋值给buf.
swap函数: 是将索引位置上的Worker两两进行交换.
For循环: 从buf中最后一个元素开始循环,一直到索引为3,其中的nextInt是取0到n-1的随机数,然后调用swp()函数,将n-1和k进行交换,这样执行结束后,buf中的Worker顺序完全被打乱了。
Workers的源码是
val workers = new HashSet[WorkerInfo]其算法内部是循环随机交换所有Worker在Master缓存数据结构中的位置;
10. 接下来要判断所有Worker中那些是ALIVE级别的Worker,ALIVE才能够参与资源的分配工作;
for (worker <- shuffledWorkers if worker.state == WorkerState.ALIVE) {
当SparkSubmit指定Driver在Cluster模式的情况下,此时Driver会加入waitingDriver等待列表中,在每个DriverInfo的DriverDescription中有要启动的Driver时候对Worker的内存及cores要求等内容。
Supervise: 如果是Cluster集群模式的话,SparkSubmit的时候,可以设置suprvise,Driver挂掉之后可以自动重启,但这个前提是Driver是在进群中的。
private[deploy] case class DriverDescription(
jarUrl: String,
mem: Int,
cores: Int,
supervise: Boolean,
command: Command) {
override def toString: String = s"DriverDescription (${command.mainClass})"
}
11. launchDriver源码:launch到worker中去了,而这个worker就是我们前面Shuffle之后打乱的Worker,此时就把Driver放到了Worker上。
//判断Worker上的内存和可用的cores是否满足Driver的要求
if (worker.memoryFree >= driver.desc.mem && worker.coresFree >= dr 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2247
2247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









