







 本文详述了如何在Spark 1.6.0中搭建基于Zookeeper的高可用(HA)架构,包括Master-Slave模型的问题、Zookeeper在HA中的作用,以及实际操作步骤,如设置Zookeeper环境、启动和测试HA。在Zookeeper故障切换期间,集群仍能保持正常运行。
本文详述了如何在Spark 1.6.0中搭建基于Zookeeper的高可用(HA)架构,包括Master-Slave模型的问题、Zookeeper在HA中的作用,以及实际操作步骤,如设置Zookeeper环境、启动和测试HA。在Zookeeper故障切换期间,集群仍能保持正常运行。
实验环境:
zookeeper-3.4.6
Spark:1.6.0
简介:
本篇博客将从以下几点组织文章:
一:Spark 构建高可用HA架构
二:动手实战构建高可用HA
三:提交程序测试HA
一:Spark 构建高可用HA架构
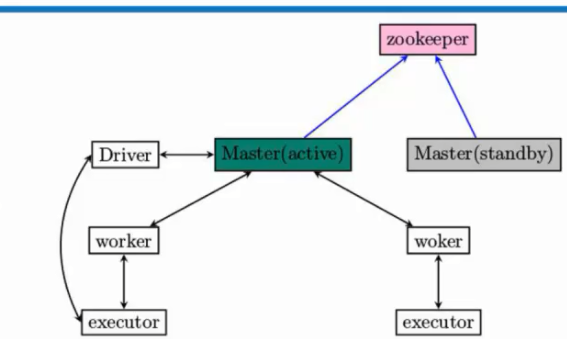
Spark本身是Master和Slave,而这这里的
Master是指Spark资源调度和分配。负责整个集群的资源调度和分配。
Worker是管理单个节点的资源。
这里面的资源主要指:内存和CPU。
1. Master-Slave模型很容易出现单节点故障的问题。所以为了应用这个问题,解决办法是通过Zookeeper来解决,在实际开发的时候一般都是三台,一个active,两个standby,当一个active挂掉后,Zookeeper会根据自己的选举机制,从standby的Master选举出来一个作为leader。这个leader从standby模式变成active模式的话,做的最重要的事:是从Zookeeper中获取整个集群的状态信息,恢复整个集群的Worker,Driver,Application,这样才能接管整个集群的工作,而只有它成功完成之后,leader的Master才可以恢复成active的Master,才可以对外继续提供服务(作业的提交和资源的申请请求。),当active的master挂掉以后,standby的master变成active的master之前我们是不可以向集群提交新的程序。但是在Zookeeper切换期间,在这个时间集群的运行时正常的,例如,一个程序依然可以正常运行。因为程序在运行之前已经向Master申请资源了,Driver与我们所有worker分配的executors进行通信,这个过程一般不需要master参与,除非executor有故障。Master是粗粒度分配,粗粒度的好处当Master出故障以后,可以让Worker和executor交互完成计算。
2. Zookeper包含的内容有哪些:所有的Worker,Driver(代表了正在运行的程序),Application(应用程序)
二:动手实战构建高可用HA
3. 准备好Zookeeper安装包,下载zookeeper-3.4.6.tar.gz地址如下:
http://apache.fayea.com/zookeeper/zookeeper-3.4.6/- 将Zookeeper软件包移动到/usr/local/spark。
- 解压zookeeper.
[root@Master spark]# tar -zxvf zookeeper-3.4.6.tar.gz- 在bashrc中添加zookeeper环境变量
export ZOOKEEPER_HOME=/usr/local/spark/zookeeper-3.4.6
export PATH=/usr/local/eclipse/eclipse:/usr/local/idea/idea-IC-141.1532.4/bin:${
MAVEN_HOME}/bin:${
FLUME_HOME}/bin:${
SPARK_HOME}/bin:${
SPARK_HOME}/sbin/sbin::${
SCALA_HOME}/bin:${
JAVA_HOME}/bin:${
HADOOP_HOME}/bin:${
HADOOP_HOME}/sbin:${
HIVE_HOME}/bin:${
ZOOKEEPER_HOME}/bin:$PATH
7. 到zookeeper的conf目录下,将zoo_sample.cfg拷贝一份,因为在执行的时候zoo_sample.cfg会被删除,拷贝改名zoo.cfg,对zoo.cfg进行配置。
[root@Master conf]# cp zoo_sample.cfg zoo.cfg8. 配置文件
[root@Master conf]# vim zoo.cfg
dataDir=/tmp/zookeeper
dataDir= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 347
347

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









