






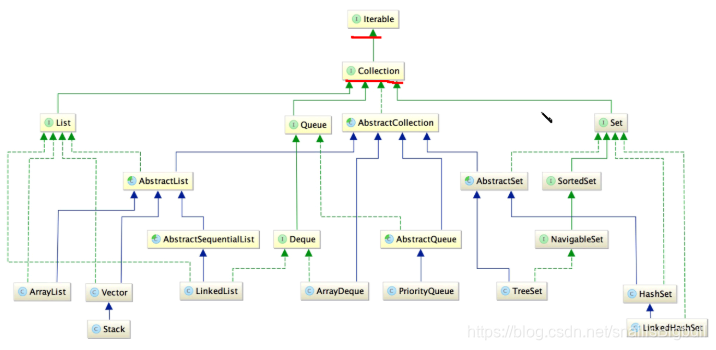
list有序可重复,set无序不可重复
ArrayList与LinkedList的区别?
他们都是list接口的实现类
ArrayList数组LinkedList双向链表
ArrayList底层基于数组,每次添加会判断扩容,可能设计到数组的复合
session和cookie的区别
1、cookie和session他们都是会话跟踪技术,可以存储用户信息。
2、cookie存储在本地客户端,session是存储在服务器端,所以session存储信息安全,为什么不安全呢?因为别人可以根据分析本地cookie获取用户信息,进行cookoe欺骗。session也依赖于cookie因为需要存储sessionId到浏览器。
3、每个cookie的内存大小由限制不超过4k,很多浏览器一个站点限制最多保存20个cookie。
4、session会在一定时间内保存在服务器中,如果访问多了,占用服务器内存,影响服务器性能,所以,通常把重要信息入用户账号密码放在session中,其他信息就放到cookie中。
抽象类与接口的区别
接口中的方法没有方法主体 默认有public abstract修饰
如果方法有static或者default修饰 可以有方法体
接口中没有构造方法
接口不能够实例化
接口中的字段默认有public static final修饰。
接口支持多态的。
普通类实现接口 implements 必须覆写接口中所有方法。
接口的继承:多继承 多重继承
类实现接口:可以多实现
一个类即有继承又有实现的时候 需要把继承的类写在前面,实现的接口放在后面。
使用abstract修饰的类和方法 类就变成抽象类 方法变成 抽象方法,
1、抽象方法不能存在于普通类中,可以存在于抽象类和接口中。
2、抽象类中可以有普通方法 字段
3、抽象类有构造方法 不能实例化
4、有abstract修饰的抽象方法 没有方法体,可以存在于抽象类和接口中。
抽象类继承另一个抽象类不需要覆写抽象类中的抽象方法
普通类继承另一个抽象类则必须覆写抽象类中抽象方法
 #### HashSet和TreeSet的区别
#### HashSet和TreeSet的区别
相同的:他们都是Set接口的实现类 都可以存储任意多个数据
不同点:HashSet可以存储任意类型的数据 而TreeSet存储任意类型中的一种实现了Comparable类 或者TreeSet有定制比较器
HashSet 是通过覆写hashcode和equals去重
线程和进程
什么是进程,比如说我们的电脑,打开任务管理器,就能看见有进程的选项卡,列表中就有当前电脑正在执行的软件应用,他们就是代表了进程。一个应用中它有很多功能比如QQ音乐,点进去就能看见线程数,这个应用里就有播放、快进、暂停等等,这些每一个功能就是线程,需要cpu分配资源区执行。
进程是资源分配的最小单位,线程是程序执行的最小单位
一个程序下至少有一个进程,一个进程下至少有一个线程,通常一个进程下拥有多个进程来增加程序的执行速度。
进程与进程的数据不共享,线程与线程之间的资源是共享的。
hashMap底层结构是如何实现的
hashMap的实现不是同步的,这就意味着不是线程安全的。它的key-value都可以为null,hashMap中的映射不是有序的。
jdk1.8中,hashmap底层是基于数组、链表和红黑树的。jdk之前底层是基于数组和链表,下面我就只分析一下JDK1.8之后的底层结构吧。其中红黑树,是一个自平衡的二叉查找树,是一种数据结构。对它的底层了解不多。
hash,通过hash确认到数组的位置,如果发生hash碰撞就以链表的形式存储,但是这样如果链表过长的话,hashmap会把这个链表转换成红黑树来存储。
1、判断数组是否为null,如果为null就需要对数组初始化(resize方法中会判断是否进行初始化)
2、根据当前key的hashcode定位到具体的数组并判断是否为null,为空则在当前位置创建一个新的数组把entry键值对放进去。
3、如果不为null那么hash碰撞,就要比较当前数组中的key,当前key的hashcode是否与已经写入的key的hashcode是否相等,相等就直接替换已有的值。
4、否则判断是否是红黑树,是就按照红黑树的方式写入数据。
5、如果是链表,如果是链表的话需要遍历到最后节点然后插入。
6、判断链表的节点长度大于或等红黑数的阀值8的话,就转换为红黑树存储
7、如果遍历过程中找到key相同直接退出遍历
8、如果e!=null,就直接覆盖,返回原来的值,为null最后会返回null。
9、最后判断是否需要进行扩容,如果数组长度大于了初始数组长度*加载因子0.75=12,就需要扩容为原来数组长度的2倍。
取值:
1、首先判断数组是否存在
2、判断key值是否存在
3、再去判断是红黑树还是链表的方式取值。
LinkedList与ArrayList的区别
他们都是List接口的实现类,可以存储有序可重复的数据。
区别是:
从底层结构上:LinkedList是基于双向链表,ArrayList是基于数组
在一定数据量的情况下,随机查询的效率ArrayList的效率高于LinkedList,arrayList实现了RandomAccess接口那么就表明了支持快速随机访问,LinkedList是双向链表要从头至尾挨个查询,效率低
增删操作时,双向链表的LinkedList的效率高,它通过前后节点就可以快如的完成增删。ArrayList会判断是否需要扩容,还会有复制数据的操作,性能消耗大。
线程的创建方式?
继承Thread类,覆写run()方法,通过start()方法启动线程。
实现runnable的接口,没有返回值
实现callable的接口,有返回值,相当于runnable功能的增强。
线程状态有哪些?
new 新建 runnable 就绪 running 正在执行 Dead 死亡 在准备就绪和running还会存在 Blocked阻塞的情况。
什么是线程安全?
多个线程同时操作同一个数据,如果有增删改的操作就会
守护线程(Deamon)
在运行程序的后台随时准备为程序服务的特殊线程,它并不属于程序中不可或缺的部分,当程序终止了,守护线程也会被摧毁。通过setDeamon可以将一个线程设置为守护线程。
sleep和wait的区别?
类的不同,sleep来自Thread,wait来自Object
释放锁,sleep不需要释放锁,wait需要释放锁
使用方法不一样,sleep设置时间到了自动恢复执行,wait需要,调用notify或者notifyAll方法唤醒
notify与notyfyAll的区别
notify是唤醒一条线程,具体那一条,是虚拟机随机分配。
notifyAll是唤醒所有的线程,这些被唤醒的线程需共同去竞争锁,争得锁就继续执行,没有竞得就等下次锁的释放参与竞争。
synchronized修饰对象有哪几种?
1、修饰方法
2、修饰代码块
3、修饰类
4、修饰静态方法
synchronized的作用?
1、同步代码,确保线程互斥访问
2、确保共享变量修改后能及时可见
3、有效的解决重排序的问题。
synchronized与Lock的区别?
1、Lock是一个类,synchronized是一个修饰符
2、Lock的枷锁和解锁是由Java代码来实现的,synchronized是jvm来管理的
3、synchronized能所锁住类、方法、代码块,Lock是块范围内的
4、Lock能提高多个线程的读操作效率
5、Lock的实现是乐观锁,synchronized是悲观锁
TreadLocal(本地线程存储):通过为每一个线程提供一个独立的变量副本,来解决线程安全问题。线程内部任何地方都可以使用,线程之间互不影响。这样就不存在线程安全问题了。
synchronized是线程间的数据共享,TreadLocal是线程间的数据隔离。
每个线程Thread内部有一个ThreadLocal.ThreadLocalMap类型的成员变量threadLocals,这个threadLocals就是用来存储实际的变量副本的,键值为当前ThreadLocal变量,value为变量副本(即T类型的变量)。
初始时,在Thread里面,threadLocals为空,当通过ThreadLocal变量调用get()方法或者set()方法,就会对Thread类中的threadLocals进行初始化,并且以当前ThreadLocal变量为键值,以ThreadLocal要保存的副本变量为value,存到threadLocals。
然后在当前线程里面,如果要使用副本变量,就可以通过get方法在threadLocals里面查找。














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









