







这次爬取的确实有些坎坷,经过了两个晚上吧,最后一个晚上还是爬取数据到最后一公里了,突然报错了。又得继续重新进行爬取
先来个爬取结果图,这次爬取的是标题,url,还有日期,估计也就只有这么多内容,用的单线程,
爬取结果:
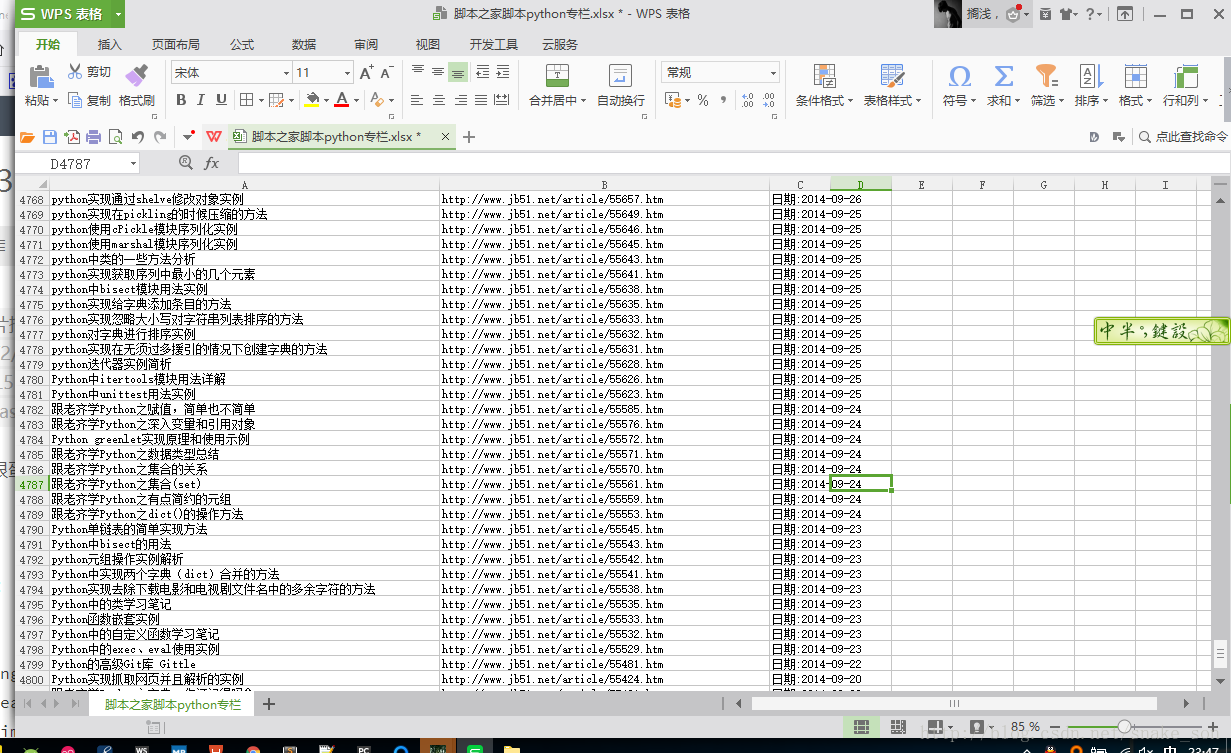
爬取的过程很蛋疼,最后是昨天晚上爬取出来的,下次争取不用单线程进行任务了。
先来份代码:
# -*- coding: UTF-8 -*-
import threading # 导入threading包
from lxml import etree
import requests
import re
import chardet
from openpyxl import Workbook
import time
# 脚本之家
baseUrl = 'http://www.jb51.net/list/list_97_1.htm'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.104 Safari/537.36 Core/1.53.2372.400 QQBrowser/9.5.10548.400'
}
pageNum = 1 # 用来计算爬取的页数
wb = Workbook()
ws = wb.active
ws.title = '脚本之家脚本python专栏'
ws.cell(row=1, column=1).value = '标题'
ws.cell(row=1, column=2).value = '链接'
ws.cell(row=1, column=3).value = '日期'
def getHtml(url):
req = requests.get(url, headers)
# print('html:'+req.text.encode(req.encoding).decode('gb2312'))
return req.text.encode(req.encoding).decode('gb2312')
def etreeMyHtml(html):
global pageNum
print('******' * 40)
html = etree.HTML(html)
result = etree.tostring(html, pretty_print=True, encoding='gb2312')
# 因为每页有四十页
for page in range(1, 41):
# 标题
title = html.xpath('//*[@id="contents"]/div/div[1]/div/div[3]/dl/dt[%s]/a/text()' % page)
# 日期
timeData = html.xpath('//*[@id="contents"]/div/div[1]/div/div[3]/dl/dt[%s]/span/text()' % page)
# 链接(因为用的是相对链接,所以要加上:http://www.jb51.net)
nextUrl = html.xpath('//*[@id="contents"]/div/div[1]/div/div[3]/dl/dt[%s]/a/@href' % page)
print('str1=== ' + str(title[0]))
print('timeData=== ' + str(timeData[0]))
nextUrl = 'http://www.jb51.net' + nextUrl[0]
print('nextUrl=== ' + str(nextUrl))
# ver_info = list(zip(title[0],nextUrl,timeData[0]))
pageNum = pageNum + 1
ws.cell(row=pageNum, column=1).value = title[0]
ws.cell(row=pageNum, column=2).value = nextUrl
ws.cell(row=pageNum, column=3).value = timeData[0]
# print('中文')
# data = getHtml(baseUrl)
# etreeMyHtml(data)
# print('中文')
def start(page1,page2):
try:
for i in range(page1, page2):
mUrl = 'http://www.jb51.net/list/list_97_%s.htm' % i
print('url ' + mUrl)
data = getHtml(mUrl)
etreeMyHtml(data)
except:
print('error '+i)
finally:
wb.save('脚本之家脚本python专栏' + '.xlsx')
def task1():
print('task1 start...')
start(1,71)
def task2():
print('task2 init...')
start(71,153)
# print("多线程:")
# starttime = time.time(); # 记录开始时间
# threads = [] # 创建一个线程列表,用于存放需要执行的子线程
# t1 = threading.Thread(target=task1) # 创建第一个子线程,子线程的任务是调用task1函数,注意函数名后不能有()
# threads.append(t1) # 将这个子线程添加到线程列表中
# t2 = threading.Thread(target=task2) # 创建第二个子线程
# threads.append(t2) # 将这个子线程添加到线程列表中
#
# for t in threads: # 遍历线程列表
# t.setDaemon(True) # 将线程声明为守护线程,必须在start() 方法调用之前设置,如果不设置为守护线程程序会被无限挂起
# t.start() # 启动子线程
# endtime = time.time(); # 记录程序结束时间
# totaltime = endtime - starttime; # 计算程序执行耗时
# print("耗时:{0:.5f}秒".format(totaltime)); # 格式输出耗时
# print('---------------------------')
# 以下为普通的单线程执行过程,不需解释
print("单线程:")
starttime = time.time();
start(1,153)
endtime = time.time();
totaltime = endtime - starttime;
print("耗时:{0:.5f}秒".format(totaltime));
总结一下:
遇到的坑:脚本之家的编码是gb2312,首次使用xpath,用完感觉还不错,比正则耗时少了,主要是直接浏览器F2,然后选中元素右键copy->xpath 就可以了, 而且上一篇文章写的很清楚,也比较容易入门
- 得到源网页:
def getHtml(url):
req = requests.get(url, headers)
# print('html:'+req.text.encode(req.encoding).decode('gb2312'))
return req.text.encode(req.encoding).decode('gb2312')
- 通过xpath进行相应的数据进行解析
def etreeMyHtml(html):
global pageNum
print('******' * 40)
html = etree.HTML(html)
# result = etree.tostring(html, pretty_print=True, encoding='gb2312')
# 因为每页有四十页
for page in range(1, 41):
# 标题
title = html.xpath('//*[@id="contents"]/div/div[1]/div/div[3]/dl/dt[%s]/a/text()' % page)
# 日期
timeData = html.xpath('//*[@id="contents"]/div/div[1]/div/div[3]/dl/dt[%s]/span/text()' % page)
# 链接(因为用的是相对链接,所以要加上:http://www.jb51.net)
nextUrl = html.xpath('//*[@id="contents"]/div/div[1]/div/div[3]/dl/dt[%s]/a/@href' % page)
print('str1=== ' + str(title[0]))
print('timeData=== ' + str(timeData[0]))
nextUrl = 'http://www.jb51.net' + nextUrl[0]
print('nextUrl=== ' + str(nextUrl))
# ver_info = list(zip(title[0],nextUrl,timeData[0]))
pageNum = pageNum + 1
ws.cell(row=pageNum, column=1).value = title[0]
ws.cell(row=pageNum, column=2).value = nextUrl
ws.cell(row=pageNum, column=3).value = timeData[0]- 使用try except finaly 进行数据的爬取,这样保证在最后也能进行数据的保存
def start(page1,page2):
try:
for i in range(page1, page2):
mUrl = 'http://www.jb51.net/list/list_97_%s.htm' % i
print('url ' + mUrl)
data = getHtml(mUrl)
etreeMyHtml(data)
except:
print('error '+i)
finally:
wb.save('脚本之家脚本python专栏' + '.xlsx')这次是失业了, 确实公司比较小,发工资都是老板亲手来发工资,遇到个京东众筹,资金又暂时的周转不过来,只能先把我这来了半年不到的小喽啰给裁掉咯。以后android 可能会慢慢放弃,转向大数据方向吧。python,你用你知道爽。下次学习招聘网站的爬取,因为自己要找工作了嘛。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









