









下载Kaldi
git clone https://github.com/kaldi-asr/kaldi.git
需要安装大约120MB
编译安装
检查依赖,根据提示安装依赖库
cd kaldi/tools
extras/check_dependencies.sh

接着进行编译,这一步需要较长时间
make -j 8

cd ../src
./configure
make -j 8
运行yesno项目验证是否安装成功
cd ../egs/yesno/s5
./run.sh

运行TIMIT项目(失败)
准备数据
下载TIMIT数据集,并放到kaldi\egs\timit\s5目录下。将其解压后生成data文件夹
unzip TIMIT.zip
修改脚本
修改cmd.sh的运行模式。我是在本地运行,所以修改为run.pl运行
# cmd.run
# export train_cmd="queue.pl --mem 4G"
# export decode_cmd="queue.pl --mem 4G"
# # the use of cuda_cmd is deprecated, used only in 'nnet1',
# export cuda_cmd="queue.pl --gpu 1"
export train_cmd="run.pl --max-jobs-run 10"
export decode_cmd="run.pl --max-jobs-run 10"
export cuda_cmd="run.pl --max-jobs-run 2"
export mkgraph_cmd="run.pl --max-jobs-run 10"
修改run.sh中数据集的目录以及cpu参数
# run.sh
feats_nj=10
train_nj=20
decode_nj=5
# timit=/mnt/matylda2/data/TIMIT/timit # @BUT
timit=<your workspace>/kaldi/egs/timit/s5/data/lisa/data/timit/raw/TIMIT # @BUT
Error1
运行过程中出现以下错误

针对"Error: the IRSTLM is not available or compiled"解决方案如下:
到kaldi/tools/目录
cd ../../../tools/
extras/install_irstlm.sh

Error2
重新./run.sh之后又出现以下错误:
Cannot find scoring program at /<workspace>/kaldi/egs/timit/s5/…/…/…/tools/sctk/bin/hubhubscr.pl
tools目录下没有sctk,所以应该是需要重新编译sctk,但是解压自带的sctk-20159b5.tar.gz出错

可能是由于最开始make的时候网速差没下全,压缩包不完整。因此重新下载该压缩包
cd ../../../tools
wget https://github.com/usnistgov/SCTK/archive/20159b5.tar.gz
mv 20159b5.tar.gz sctk-20159b5.tar.gz
tar -zxvf sctk-20159b5.tar.gz
重新编译一次
make clean
make -j 8
# Warning: IRSTLM is not installed by default anymore. If you need IRSTLM
# Warning: use the script extras/install_irstlm.sh
# All done OK.
extras/install_irstlm.sh
cd ../src
./configure
make -j 8
之后就运行成功了。但是如果把exit 0注释掉,继续运行下面的训练过程,就会报错!!ubm的问题
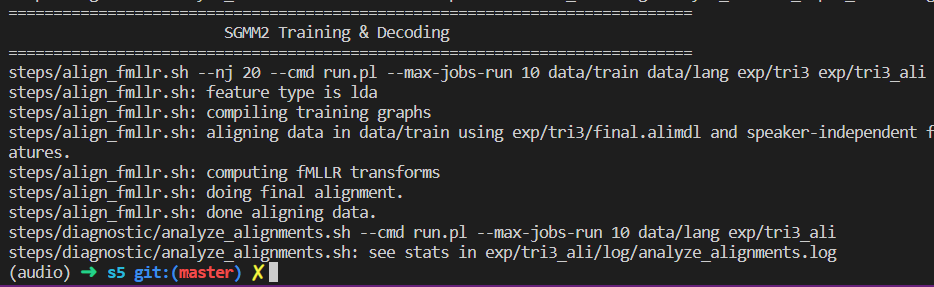
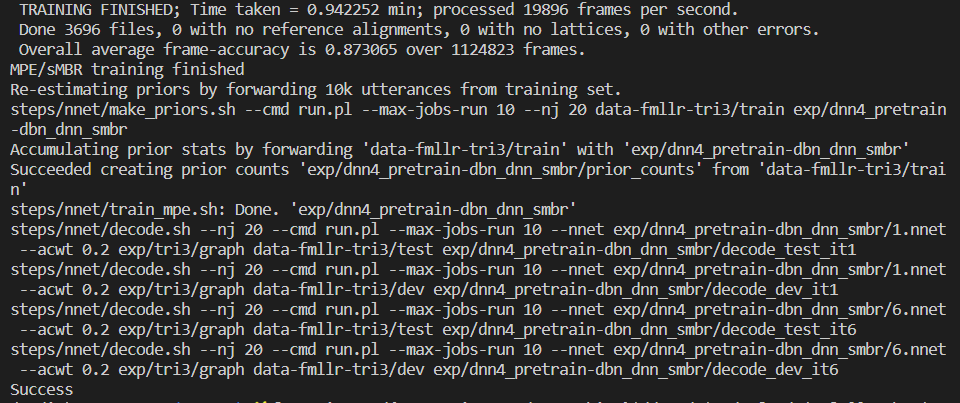
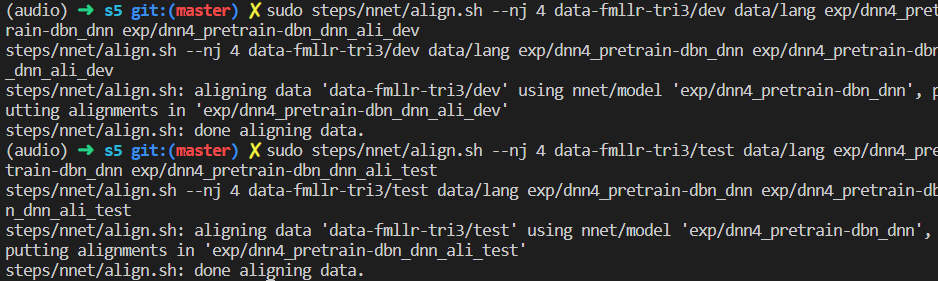
对齐数据
steps/nnet/align.sh --nj 4 data-fmllr-tri3/train data/lang exp/dnn4_pretrain-dbn_dnn exp/dnn4_pretrain-dbn_dnn_ali
steps/nnet/align.sh --nj 4 data-fmllr-tri3/dev data/lang exp/dnn4_pretrain-dbn_dnn exp/dnn4_pretrain-dbn_dnn_ali_dev
steps/nnet/align.sh --nj 4 data-fmllr-tri3/test data/lang exp/dnn4_pretrain-dbn_dnn exp/dnn4_pretrain-dbn_dnn_ali_test
修改配置
修改pytorch-kaldi/cfg/TIMIT_baselines中的TIMIT_MLP_mfcc_basic.cfg路径。将kaldi路径修改为自己环境下kaldi的工作路径(记住用绝对路径)
[dataset1]
data_name = TIMIT_tr
fea = fea_name=mfcc
fea_lst=/home/mirco/kaldi-trunk/egs/timit/s5/data/train/feats.scp
# fea_opts=apply-cmvn --utt2spk=ark:/home/mirco/kaldi-trunk/egs/timit/s5/data/train/utt2spk ark:/home/mirco/kaldi-trunk/egs/timit/s5/mfcc/cmvn_train.ark ark:- ark:- | add-deltas --delta-order=2 ark:- ark:- |
fea_lst=/<your workspace>/kaldi/egs/timit/s5/data/train/feats.scp
fea_opts=apply-cmvn --utt2spk=ark:/<your workspace>/kaldi/egs/timit/s5/data/train ark:/<your workspace>/kaldi/egs/timit/s5/mfcc/cmvn_train.ark ark:- ark:- | add-deltas --delta-order=2 ark:- ark:- |
cw_left=5
cw_right=5
lab = lab_name=lab_cd
# lab_folder=/home/mirco/kaldi-trunk/egs/timit/s5/exp/dnn4_pretrain-dbn_dnn_ali
lab_folder=/<your workspace>/kaldi/egs/timit/s5/exp/dnn4_pretrain-dbn_dnn_ali
lab_opts=ali-to-pdf
lab_count_file=auto
# lab_data_folder=/home/mirco/kaldi-trunk/egs/timit/s5/data/train/
# lab_graph=/home/mirco/kaldi-trunk/egs/timit/s5/exp/tri3/graph
lab_data_folder=/<your workspace>/kaldi/egs/timit/s5/exp/timit/s5/data/train/
lab_graph=/<your workspace>/kaldi/egs/timit/s5/exp/timit/s5/exp/tri3/graph
n_chunks = 5
[dataset2]
data_name = TIMIT_dev
fea = fea_name=mfcc
# fea_lst=/home/mirco/kaldi-trunk/egs/timit/s5/data/dev/feats.scp
# fea_opts=apply-cmvn --utt2spk=ark:/home/mirco/kaldi-trunk/egs/timit/s5/data/dev/utt2spk ark:/home/mirco/kaldi-trunk/egs/timit/s5/mfcc/cmvn_dev.ark ark:- ark:- | add-deltas --delta-order=2 ark:- ark:- |
fea_lst=/<your workspace>/kaldi/egs/timit/s5/data/dev/feats.scp
fea_opts=apply-cmvn --utt2spk=ark:/<your workspace>/kaldi/egs/timit/s5/data/dev/utt2spk ark:/<your workspace>/kaldi/egs/timit/s5/mfcc/cmvn_dev.ark ark:- ark:- | add-deltas --delta-order=2 ark:- ark:- |
cw_left=5
cw_right=5
lab = lab_name=lab_cd
# lab_folder=/home/mirco/kaldi-trunk/egs/timit/s5/exp/dnn4_pretrain-dbn_dnn_ali_dev
lab_folder=/<your workspace>/kaldi/egs/timit/s5/exp/dnn4_pretrain-dbn_dnn_ali_dev
lab_opts=ali-to-pdf
lab_count_file=auto
# lab_data_folder=/home/mirco/kaldi-trunk/egs/timit/s5/data/dev/
# lab_graph=/home/mirco/kaldi-trunk/egs/timit/s5/exp/tri3/graph
lab_data_folder=/<your workspace>/kaldi/egs/timit/s5/data/dev/
lab_graph=/<your workspace>/kaldi/egs/timit/s5/exp/tri3/graph
n_chunks = 1
[dataset3]
data_name = TIMIT_test
fea = fea_name=mfcc
# fea_lst=/home/mirco/kaldi-trunk/egs/timit/s5/data/test/feats.scp
# fea_opts=apply-cmvn --utt2spk=ark:/home/mirco/kaldi-trunk/egs/timit/s5/data/test/utt2spk ark:/home/mirco/kaldi-trunk/egs/timit/s5/mfcc/cmvn_test.ark ark:- ark:- | add-deltas --delta-order=2 ark:- ark:- |
fea_lst=/<your workspace>/kaldi/egs/timit/s5/data/test/feats.scp
fea_opts=apply-cmvn --utt2spk=ark:/<your workspace>/kaldi/egs/timit/s5/data/test/utt2spk ark:/<your workspace>/kaldi/egs/timit/s5/mfcc/cmvn_test.ark ark:- ark:- | add-deltas --delta-order=2 ark:- ark:- |
cw_left=5
cw_right=5
lab = lab_name=lab_cd
# lab_folder=/home/mirco/kaldi-trunk/egs/timit/s5/exp/dnn4_pretrain-dbn_dnn_ali_test
lab_folder=/<your workspace>/kaldi/egs/timit/s5/exp/dnn4_pretrain-dbn_dnn_ali_test
lab_opts=ali-to-pdf
lab_count_file=auto
# lab_data_folder=/home/mirco/kaldi-trunk/egs/timit/s5/data/test/
# lab_graph=/home/mirco/kaldi-trunk/egs/timit/s5/exp/tri3/graph
lab_data_folder=/<your workspace>/kaldi/egs/timit/s5/data/test/
lab_graph=/<your workspace>/kaldi/egs/timit/s5/exp/tri3/graph
运行run_exp.py
python3 run_exp.py cfg/TIMIT_baselines/TIMIT_MLP_mfcc_basic.cfg
Error1
...
File "/<workspace>/pytorch-kaldi/data_io.py", line 149, in _sort_chunks_by_length
fea_conc, lab_conc = zip(*fea_sorted)
ValueError: not enough values to unpack (expected 2, got 0)
...
File "/<workspace>/pytorch-kaldi/core.py", line 496, in run_nn
data_name = shared_list[0]
IndexError: list index out of rangev
卡住!!!
aishell项目
建立数据保存的文件夹
mkdir export
mkdir export/a05
mkdir export/a05/xna
mkdir export/a05/xna/data
修改local/cmd.sh,使用run.pl启动
diff --git a/egs/aishell/v1/cmd.sh b/egs/aishell/v1/cmd.sh
index d1ca1a6d1..170829d99 100644
--- a/egs/aishell/v1/cmd.sh
+++ b/egs/aishell/v1/cmd.sh
@@ -10,6 +10,7 @@
# conf/queue.conf in http://kaldi-asr.org/doc/queue.html for more information,
# or search for the string 'default_config' in utils/queue.pl or utils/slurm.pl.
-export train_cmd="queue.pl --mem 4G"
+# export train_cmd="queue.pl --mem 4G"
+export train_cmd="run.pl --mem 4G
修改local/download_and_untar.sh,这部分有路径错误,导致解压出错
diff --git a/egs/aishell/v1/local/download_and_untar.sh b/egs/aishell/v1/local/download_and_untar.sh
index b0636a8cd..8321ce283 100755
--- a/egs/aishell/v1/local/download_and_untar.sh
+++ b/egs/aishell/v1/local/download_and_untar.sh
@@ -78,9 +78,9 @@ if [ ! -f $data/$part.tgz ]; then
fi
fi
-cd $data
+# cd $data
-if ! tar -xvzf $part.tgz; then
+if ! tar -xvzf $data/$part.tgz; then
echo "$0: error un-tarring archive $data/$part.tgz"
exit 1;
fi
@@ -93,6 +93,7 @@ if [ $part == "data_aishell" ]; then
echo "Extracting wav from $wav"
tar -zxf $wav && rm $wav
done
+ cd ../../..
fi
echo "$0: Successfully downloaded and un-tarred $data/$part.tgz"
修改run.sh,此处data目录是在根目录,可将其修改为相对路径
diff --git a/egs/aishell/v1/run.sh b/egs/aishell/v1/run.sh
index b16939bd3..46bb6d976 100755
--- a/egs/aishell/v1/run.sh
+++ b/egs/aishell/v1/run.sh
@@ -12,7 +12,7 @@
# See README.txt for more info on data required.
# Results (EER) are inline in comments below
-data=/export/a05/xna/data
+data=export/a05/xna/data
data_url=www.openslr.org/resources/33
. ./cmd.sh
运行./run.sh,它占用大量的cpu资源,需要等待很长一段时间(我在服务器跑需要7.5小时),得到错误率为0.224845%
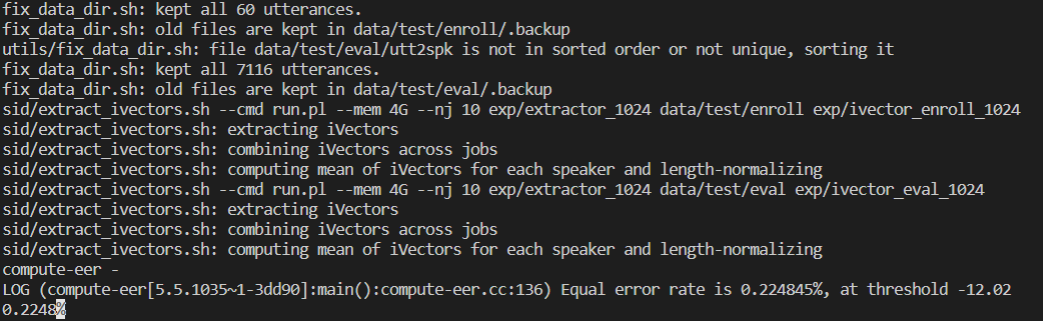
Kaldi 预训练模型
罢了罢了,使用别人训练好的模型他不香吗?
Kaldi ASR中既有语音识别(ASR),也有说话人识别(SID)以及其他部分任务

















 1422
1422

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









