







Step 6: Machine Learning
Machine Learning In Python: Beginner
数据集:their machine learning repository
>>读取表格型数据文件 read_table method
mpg = pd.read_table("auto-mpg.data", delim_whitespace=True)
>>注意区别:
cars["weight"].values.shape >>返回(398,)0列,相当于是一个向量
cars[["weight"]].values.shape >>返回(398,1),1列相当于是一个矩阵
>>线性回归模型的训练
lr=LinearRegression()
lr.fit(inputs, output) inputs必须要是矩阵,而output可以是矩阵或者向量
>>计算均方误差,mean_squared_error
均方根误差,对上面mse开根号即可
#读取文件,并赋给索引值,这里采用name赋值的方式;如果先生成cars,再给cars.columns赋值则不对,会把第一行覆盖掉
import pandas as pd
name=['mpg','cylinders','displacement','horsepower','weight','acceleration','model year','origin','car name']
cars=pd.read_table('auto-mpg.data',names=name,delim_whitespace=True)
print(cars.head())
#可视化部分特征之间的关系
import matplotlib.pyplot as plt
fig=plt.figure()
ax1=fig.add_subplot(2,1,1)
ax2=fig.add_subplot(2,1,2)
cars.plot.scatter(x='weight',y='mpg',ax=ax1)
cars.plot.scatter(x='acceleration',y='mpg',ax=ax2)
plt.show()
#线性回归模型的训练与预测
from sklearn.linear_model import LinearRegression
lr=LinearRegression()
lr.fit(cars[['weight']],cars['mpg'])
predictions=lr.predict(cars[['weight']])
print(predictions[:5])
print(cars['mpg'].head())
#作图
fig,ax=plt.subplots()
ax.scatter(cars['weight'],cars['mpg'],c='r')
ax.scatter(cars['weight'],predictions,c='b')
plt.show()
#计算误差
from sklearn.metrics import mean_squared_error
mse=mean_squared_error(cars['mpg'],predictions)
print(mse)#进行数据清洗和类型转换
filtered_cars=cars[cars['horsepower']!='?']
filtered_cars['horsepower']=filtered_cars['horsepower'].astype(float)#逻辑斯提回归对模型进行训练
from sklearn.linear_model import LogisticRegression
logistic_model = LogisticRegression()
logistic_model.fit(admissions[["gpa"]], admissions["admit"])
#预测分类概率
pred_probs=logistic_model.predict_proba(admissions[["gpa"]])
plt.scatter(admissions["gpa"],pred_probs[:,1])
plt.show()
#进行预测
fitted_labels=logistic_model.predict(admissions[["gpa"]])
print(fitted_labels)>>对分类问题进行评价
二分类问题的评价指标TP TN FP FN,精确率召回率(P=TP/(TP+FP), R=TP/(TP+FN))
sensitivity=TPR=TP/(TP+FN) SPECIFITY=TNR=TN/(TN+FP)
>>交叉验证为了避免过拟合
numpy.random.permutation 对序列进行随机化
>>画出roc曲线roc_curve fpr, tpr, thresholds = metrics.roc_curve(labels, probabilities)
False positive rate, FPR=FP/(FP+TN)
>>roc曲线下的面积用auc表示roc_auc_score
#将序列随机化,然后分配测试集和验证集
import numpy as np
np.random.seed(8)
admissions = pd.read_csv("admissions.csv")
admissions["actual_label"] = admissions["admit"]
admissions = admissions.drop("admit", axis=1)
new_ind=np.random.permutation(admissions.index)
shuffled_admissions=admissions.loc[new_ind]
train=shuffled_admissions.iloc[0:515]
test=shuffled_admissions.iloc[515:]
print(shuffled_admissions.head())
#模型训练与验证
model = LogisticRegression()
model.fit(train[["gpa"]], train["actual_label"])
labels = model.predict(test[["gpa"]])
test["predicted_label"] = labels
matches = test["predicted_label"] == test["actual_label"]
correct_predictions = test[matches]
accuracy = len(correct_predictions) / len(test)
tp=len(test[(test['actual_label']==1)&(test['predicted_label']==1)])
tn=len(test[(test['actual_label']==0)&(test['predicted_label']==0)])
fp=len(test[(test['actual_label']==0)&(test['predicted_label']==1)])
fn=len(test[(test['actual_label']==1)&(test['predicted_label']==0)])
sensitivity=tp/(tp+fn)
specificity=tn/(tn+fp)
#画出roc曲线
pred_prob=model.predict_proba(test[['gpa']])
fpr,tpr,thresholds=roc_curve(test['actual_label'],pred_prob[:,1])
plt.plot(fpr,tpr)
from sklearn.metrics import roc_auc_score
auc_score=roc_auc_score(test['actual_label'],pred_prob[:,1])kf = KFold(n, n_folds, shuffle=False, random_state=None)

注意kfold进行了版本更新,现在的链接KFold
cross_val_score(estimator, X, Y, scoring=None, cv=None)

验证的步骤:
instantiate the model class you want to fit (e.g. LogisticRegression),
instantiate the KFold class and using the parameters to specify the k-fold cross-validation attributes you want,
use the cross_val_score function to return the scoring metric you're interested in.
>>聚类基础
计算欧几里得距离euclidean_distances()
与模型训练类似,传入的参数需要是矩阵,而不能是向量
所以要么是:distance=euclidean_distances([votes.iloc[0,3:]], [votes.iloc[2,3:]])
或者euclidean_distances(votes.iloc[0,3:].reshape(1, -1), votes.iloc[2,3:].reshape(1, -1)),不能是euclidean_distances(votes.iloc[0,3:], votes.iloc[2,3:])
k均值聚类 KMeans,kmeans实例化为model后, 对数据集进行聚类model.fit(data),然后可以得到各个sample聚类的标签model.labels_,通过model.transform()还可以转化为每个sample到各个簇的距离里的最近的为该sample的标签
统计数据表内的频次关系 crosstab()例子:
is_smoker = [0,1,1,0,0,1]
has_lung_cancer = [1,0,1,0,1,0] has_lung_cancer 0 1
smoker
0 1 2
1 2 1
代码:
#计算欧几里得距离
from sklearn.metrics.pairwise import euclidean_distances
distance=euclidean_distances([votes.iloc[0,3:]], [votes.iloc[2,3:]])
#进行k均值聚类
import pandas as pd
from sklearn.cluster import KMeans
kmeans_model = KMeans(n_clusters=2, random_state=1)
senator_distances=kmeans_model.fit_transform(votes.iloc[:,3:])
#统计频次
labels=kmeans_model.labels_
pd.crosstab(labels, votes["party"])
#找出异常的samples,本应该属于某一簇,实际没有聚类到该簇
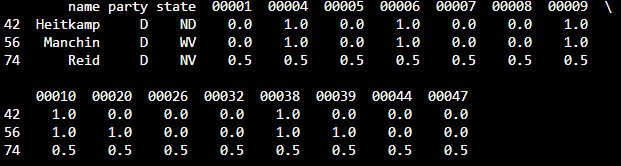
democratic_outliers=votes[(labels==1)&(votes['party']=='D')]
print(democratic_outliers)
#将聚类结果可视化
plt.scatter(senator_distances[:,0],senator_distances[:,1],c=labels)
plt.show()
#利用各个sample到各个簇的距离值来评价各个sample的extreme情况和moderate情况,依据此进行排序
extremism=[senator_distances[i,0]**3+senator_distances[i,1]**3 for i in range(len(senator_distances))]
votes['extremism']=extremism
votes.sort_values('extremism',inplace=True,ascending=False)
print(votes.head(10))中间结果:
聚类之后统计的频次:

所找出的异常的三个sample:
>>Guided Project: Predicting Board Game Reviews















 500
500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









