






Despite these advancements, most word embedding techniques share a common problem in that each word must encode all of its potential meanings into a single vector.
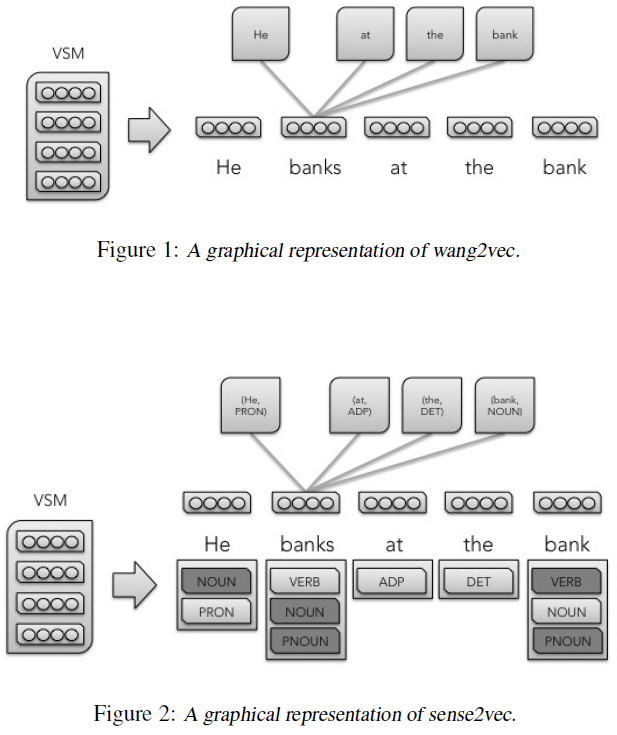
This technique is inspired by the work of Huang et al. (2012), which uses a multi-prototype neural vector-space model that clusters contexts to generate prototypes. Given a pre-trained word embedding model, each context embedding is generated by computing a weighted sum of the words in the context (weighted by tf-idf). Then, for each term, the associated context embeddings are clustered. The clusters are used to re-label each occurrence of each word in the corpus. Once these terms have been re-labeled with the cluster’s number, a new word model is trained on the labeled embeddings (with a different vector for each) generating the word-sense embeddings.
We expand on the work of Huang et al. (2012) by leveraging supervised NLP labels instead of unsupervised clusters to determine a particular word nstance’s sense. This eliminates the need to train embeddings multiple times, eliminates the need for a clustering step, and creates an efficient method by which a supervised classifier may consume the appropriate word-sense embedding.
Given a labeled corpus (either by hand or by a model) with one or more labels per word, the sense2vec model first counts the number of uses (where a unique word maps set of one or more labels/uses) of each word and generates a random ”sense embedding” for each use. A model is then trained using either the CBOW, Skip-gram, or Structured Skip-gram model onfigurations. Instead of predicting a token given surrounding tokens, this model predicts a word sense given surrounding senses.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









