






Single Layer
A layer has two memroy: input memory,output memory. Parameters are
A∈Rd×|V|
,
B∈Rd×|V|
,
C∈Rd×|V|
,
W∈R|V|×d
.
Input set x1,...,xi (one hot encoding or distribute encoding? probably the one hot.)
Input memory
The input memory represented by
mi
, the
mi
is computed by
Axi
, i.e. each
mi
is transformed from
xi
using
A
.
Query
The query
so p is a probability vecotr over the inputs.
Output memory
Each
Generating final prediction
The predicted label formula:
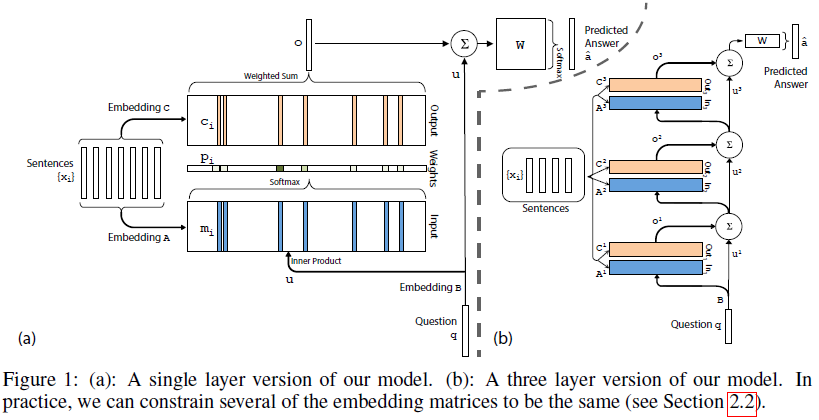
Mutltiple Layers
With K hop operations, the memory layers are stacked in the following way:
The input tot layers above the first is the sum of the output
ok and the input uk from layers k−1 (different ways to combine ok and uk are proposed later):
uk+1=uk+okEach layer has its own embedding matrices Ak , Ck , used to embed the inputs xi .
At the top of network, the input W also combines the input and the output of the top memory layer:
a^=softmax(Wuk+1)=softmax(W(oK+uK)) .Two types of weights tying:
- Adjacent: the output embedding for one layer is the input embedding for the one above, i.e. Ak+1=Ck . also constrain (a) the answer prediction matrix to be the same as the final output embedding, i.e. WT=CK , and (b) the question embedding to match the input embedding of the first layer, i.e. B=A1 .
- Layer-wise (RNN-like): the input and output embeddings are the same across different layers, i.e.
A1=A2=...=AK
and
C1=C2=...=CK
. found it useful to add a linear mapping
H
to the update of
u between hops; that is, uk+1=Huk+ok . This mapping is learned from data and used throughout experiments for layer-wise weight tying.















 665
665

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









