









前言
已经实现了通过使用Obsidian实现Anki快速制卡。
对于语言学习,仅仅只有不同语言文字的对照是不够的,我们还需要声音。
所以就需要加入音频。
幸好 Anki 插件十分丰富。
安装插件
这里我们使用 AwesomeTTS 插件进行音频生成。
此为插件链接 AwesomeTTS - Add speech to your flashcards - AnkiWeb。
先安装插件,如有不会请先看 Anki如何安装插件。
安装后点击 Anki 中的浏览。
可以看到多了一个 AwesomeTTS 选项。
这就说明安装成功了。
制作音频
这个插件制作音频是开箱即用的,非常简单。
先选中一些卡片,然后点击 AwesomeTTS 中的 Add Audio to Selected。
进入下面的界面。
Generate Using 是选择你要用的语音模型,我这里用 Azure,这个是需要 API 的。还可以用 Google Translate,这个不需要 API,免费的,不过如果一次生成太多的卡片,会有个 sleep,需要等挺长时间的。
Voice 是声音,选择你需要的语言,语言一定要选对,不然会很奇怪。不同人物音色是不同的。
下面的 sava 可以保存声音的设置,下次生成就不用调整了。
最后单击 Generate,生成声音。可能会出现 sleep,让你等待,那就耐心等待,这个是因为一次请求太多了,一次生成十个卡片以上就会出现,换个付费的语音模型可以避免。
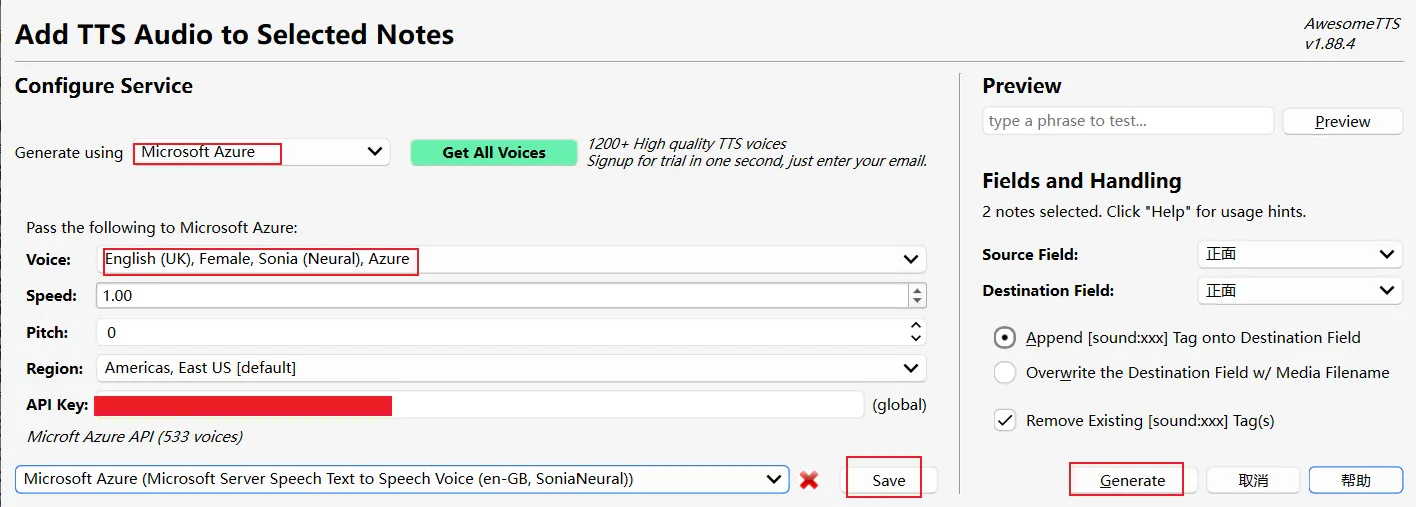
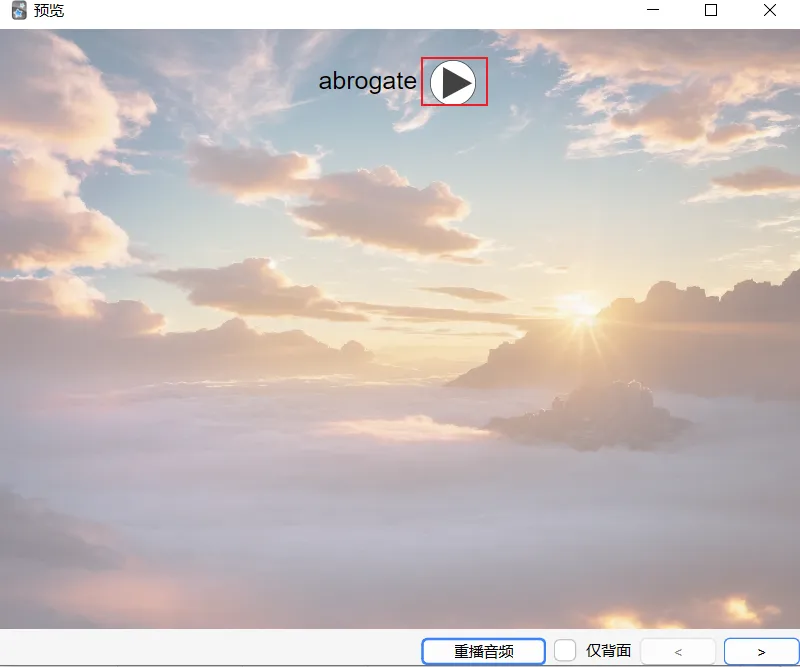
如果卡片后面出现 sound: xxx.mp3,这就说明语音生成成功了。

预览卡片,我们也能看到播放图标了。
一些注意事项
有些事情是需要注意的。
语音消失现象
当 Obsidian 中的一篇笔记再次点击制卡按键后,Anki 中的语音就会被删除,因为新制作的卡会覆盖老的卡片,语音是后加入的,会被覆盖掉,你就得重新制作卡片了。
所以推荐当你不会再点击制卡后再制作语音。
不同端出现媒体文件丢失
使用 AnkiWeb 进行不同端的同步时,可能会出现媒体文件丢失。
这是因为 Anki 默认只同步牌组,至于说卡牌含有的媒体文件,是不管的。
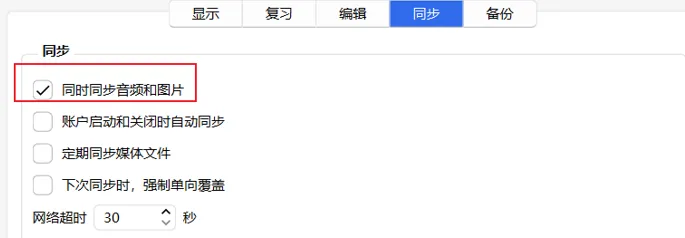
我们需要点击工具里面的设置。
选择同步,勾上同时同步音频和图片。

















 5619
5619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









