







本软件工具仅限于学术交流使用,严格遵循相关法律法规,符合平台内容合法性,禁止用于任何商业用途!

抖音作为国内颇受欢迎的短视频社交平台,汇聚了大量用户群体和活跃用户。分析平台上的热门视频可用于市场调研和竞品分析,帮助了解流行内容和趋势,从而为企业制定营销策略和推广方案提供参考。同时,也可作为灵感源泉,帮助内容创作者发现新的创意和内容方向。
为了实现这一目标,我使用Python开发了一个爬虫采集软件,可根据关键词抓取视频作品数据。
为了方便不熟悉编程的用户和文科专业人士使用,我开发了一个图形界面软件,用户无需安装Python,也无需更改代码,只需双击打开即可使用!
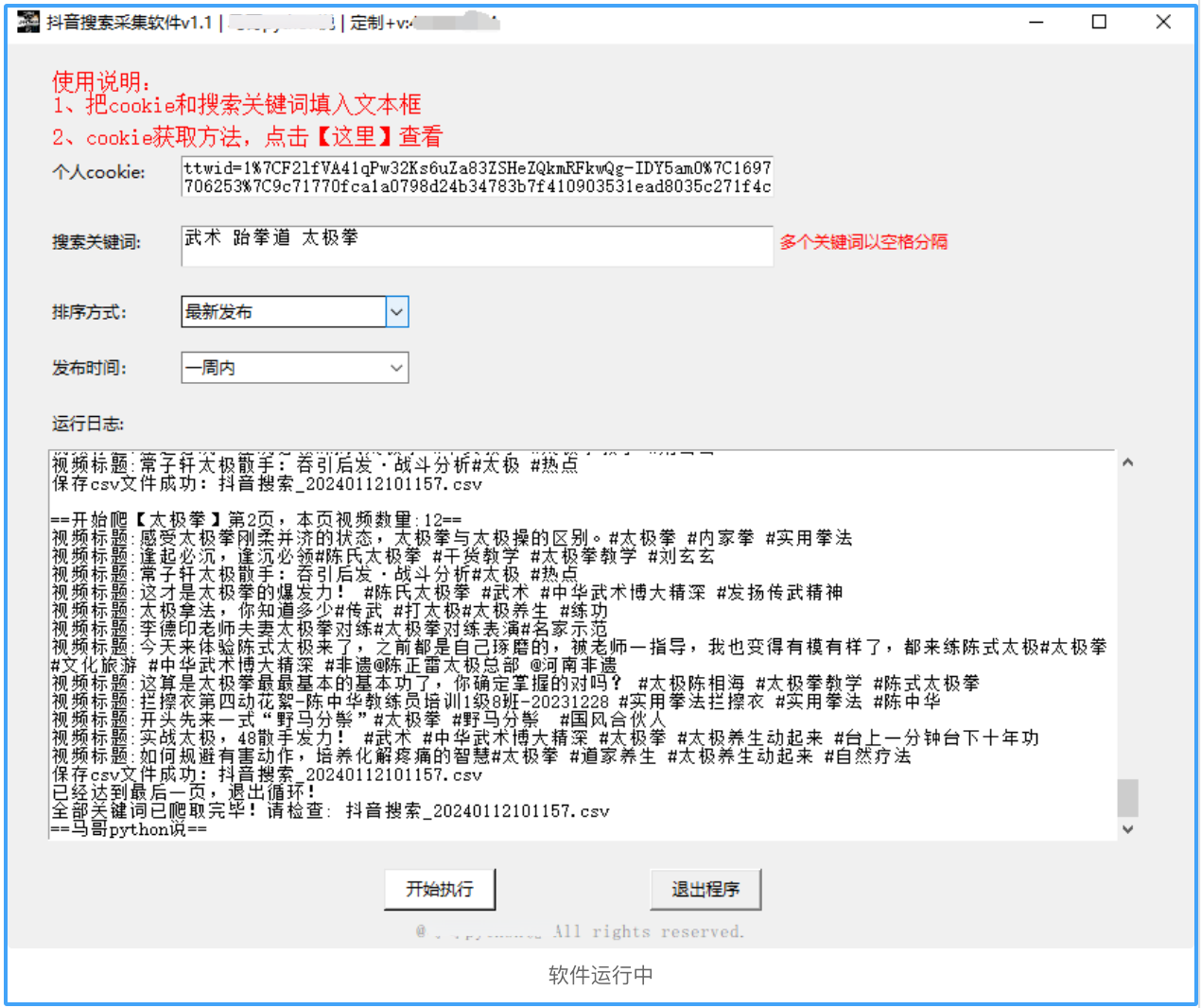
软件运行界面如下所示:
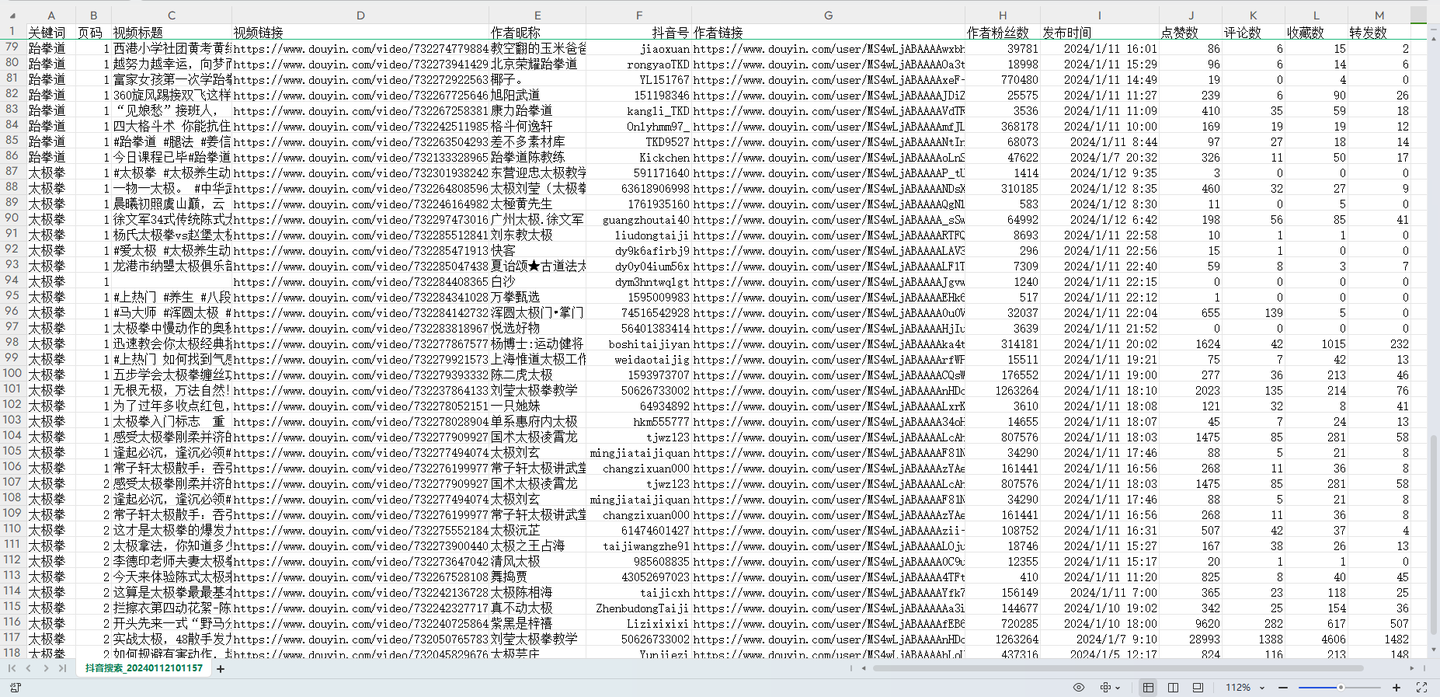
在软件运行过程中,显示了部分数据采集结果,如下图所示:
此外,我还制作了一段演示视频,展示软件的具体使用过程,供非IT领域从业者参考:
有几点重要说明需要特别指出:

在软件的代码解析中,通过定义请求地址和请求头部等参数,模拟浏览器发送请求,并获取dy视频数据。为了方便用户了解软件运行情况和历史记录,还包含了日志模块,可记录软件运行的详细信息。
请求地址:(目标链接)
# 请求地址
url = 'https://www.douyin.com/aweme/v1/web/search/item/'
请求头:(模拟浏览器)
# 请求头
h1 = {
"Accept": 'application/json, text/plain, */*',
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8",
"Cookie": self.cookie_val,
"Referer": "",
"Sec-Ch-Ua": 'Not_A Brand";v="8", "Chromium";v="120", "Google Chrome";v="120',
"Sec-Ch-Ua-Mobile": "?0",
"Sec-Ch-Ua-Platform": "Windows",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
请求参数:(爬取条件)
# 请求参数
params = {
"device_platform": "webapp",
"aid": "6383",
"channel": "channel_pc_web",
"search_channel": "aweme_video_web",
"sort_type": self.trans_sort_type(v_str=self.sort_type),
"publish_time": self.trans_time_range(v_str=self.time_range),
"keyword": search_keyword,
"search_source": "tab_search",
"query_correct_type": "1",
"is_filter_search": "1",
"from_group_id": "",
"offset": cursor,
"count": "20",
"pc_client_type": "1",
"version_code": "170400",
"version_name": "17.4.0",
"cookie_enabled": "true",
"screen_width": "1536",
"screen_height": "864",
"browser_language": "zh-CN",
"browser_platform": "Win32",
"browser_name": "Chrome",
"browser_version": "120.0.0.0",
"browser_online": "true",
"engine_name": "Blink",
"engine_version": "120.0.0.0",
"os_name": "Windows",
"os_version": "10",
"cpu_core_num": "8",
"device_memory": "8",
"platform": "PC",
"downlink": "10",
"effective_type": "4g",
"round_trip_time": "50",
"webid": "7249265465250973217",
"msToken": "Sx2PzLIz0YGvM_wrIkaUaaeUb1JUutgo3ERiWmwV1w6VC1naW15lFM6N3nanMZRZYfaHLvXrDNzGqkAyvvCpdO3d6u0u_kNmmZZHeMIsDqga2eWnjTzp5g==",
"X-Bogus": ""
}
发送请求:(相当于浏览器访问dy页面的过程)
# 发送请求
r = requests.get(url, headers=h1, params=params)
# 以json格式接收返回数据
json_data = r.json()
解析响应数据:
for v in video_list:
# 视频标题
title = v['aweme_info']['desc']
self.tk_show('视频标题:' + title)
title_list.append(title)
保存解析结果到csv文件:
# 保存数据到DF
df = pd.DataFrame(
{
'关键词': search_keyword,
'页码': page,
'视频标题': title_list,
'视频链接': link_list,
'作者昵称': author_name_list,
'dy号': author_id_list,
'作者链接': author_link_list,
'作者粉丝数': follower_count_list,
'发布时间': create_time_list,
'点赞数': like_count_list,
'评论数': comment_count_list,
'收藏数': collect_count_list,
'转发数': share_count_list,
}
)
df.to_csv(self.result_file, mode='a+', index=False, header=header, encoding='utf_8_sig')
self.tk_show('保存csv文件成功')
日志实现逻辑:
def get_logger(self):
self.logger = logging.getLogger(__name__)
# 日志格式
formatter = '[%(asctime)s-%(filename)s][%(funcName)s-%(lineno)d]--%(message)s'
# 日志级别
self.logger.setLevel(logging.DEBUG)
# 控制台日志
sh = logging.StreamHandler()
log_formatter = logging.Formatter(formatter, datefmt='%Y-%m-%d %H:%M:%S')
# info日志文件名
info_file_name = time.strftime("%Y-%m-%d") + '.log'
# 将其保存到特定目录下
case_dir = r'./logs/'
info_handler = TimedRotatingFileHandler(filename=case_dir + info_file_name,
when='MIDNIGHT',
interval=1,
backupCount=7,
encoding='utf-8')
以上就是全部重要实现代码啦。

















 1394
1394

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









