







文章目录
本软件工具仅限于学术交流使用,严格遵循相关法律法规,符合平台内容合法合规性,禁止用于任何商业用途!
一、背景调研
1.1 开发背景
抖音作为国内流量极为突出的短视频平台,拥有庞大的用户群体以及亿级以上的日活跃用户,其视频下方的评论区蕴含着丰富的信息价值。在合法合规的前提下,经过充分的研究与探索,为了助力客户能够更深入地理解消费者对于商品和品牌的看法与反馈,以更有效地把握消费者的喜好、需求和购买意图,我们开发了一款基于 Python 技术的工具,旨在在符合平台规则和相关法律法规的框架内,对平台上公开且允许获取的评论数据进行收集分析。
我用python开发的爬虫采集工具【爬dy搜索评论软件】,支持2种模式的评论采集:
1、根据关键词采集评论,爬取思路:作品关键词->作品链接->评论
2、根据作品链接采集评论,爬取思路:作品链接->评论
用户可根据自身需求,在遵守相关规定的情况下,选择其中一种模式进行合规的评论数据收集与分析。
1.2 软件界面
软件界面,如下: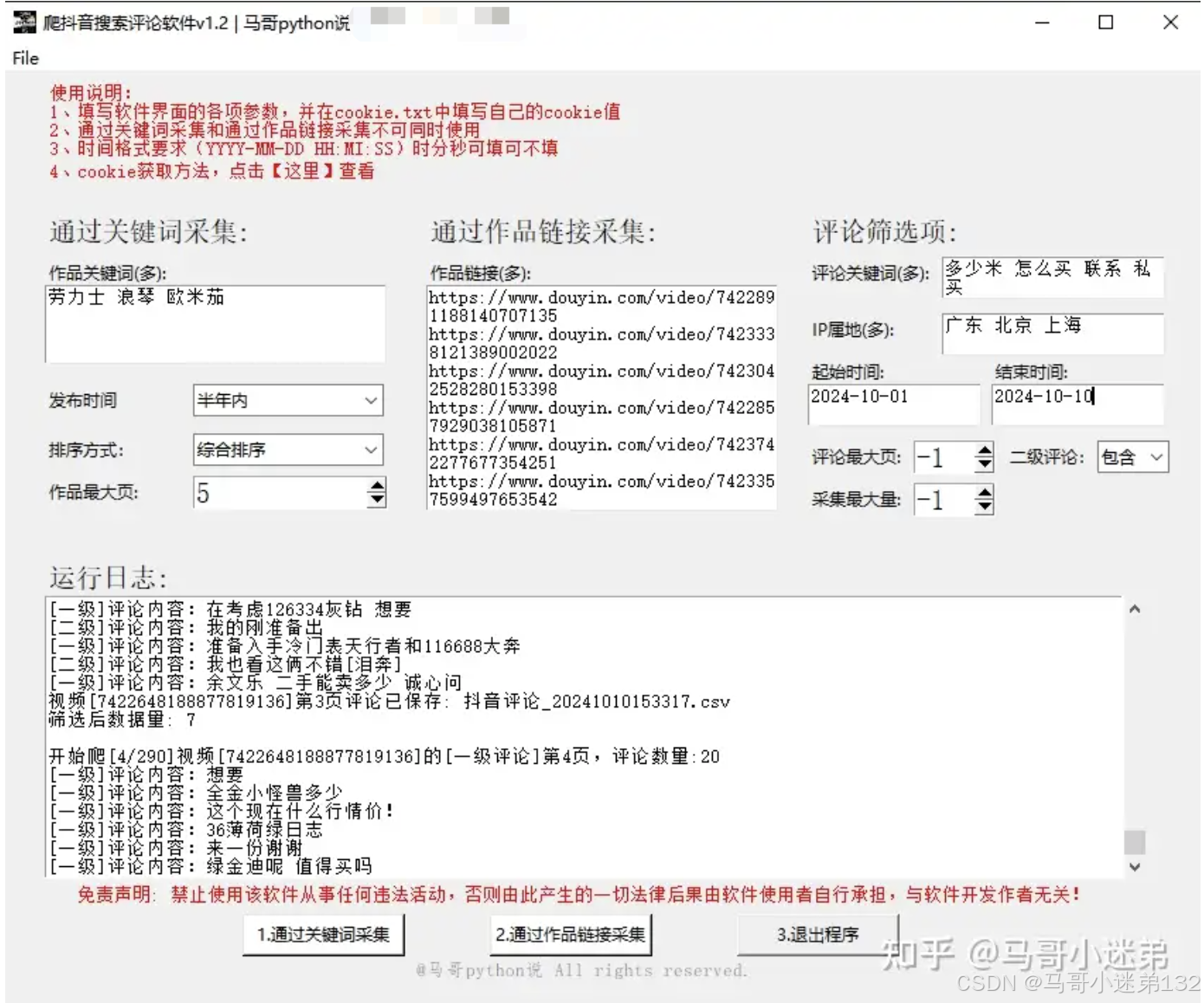
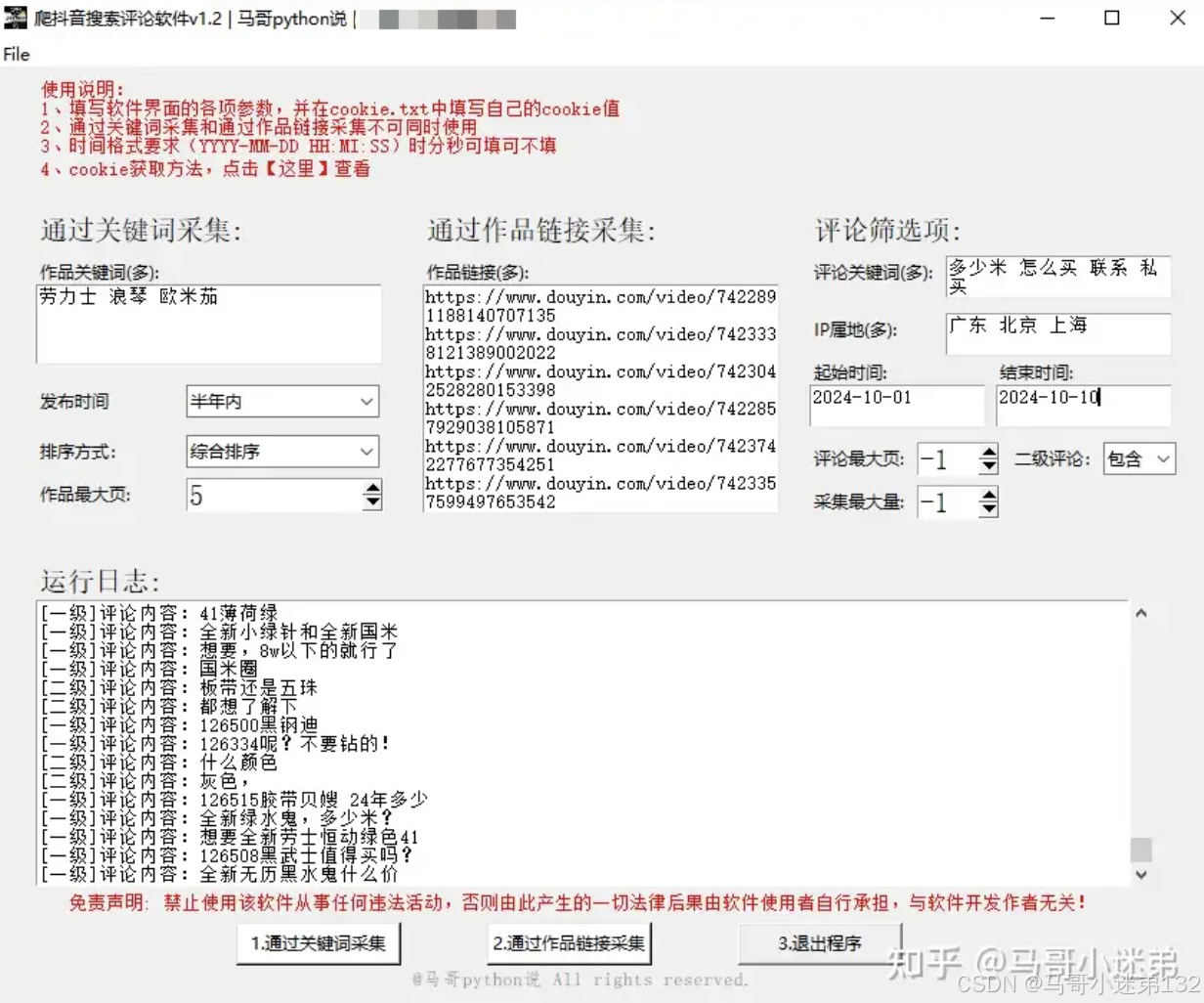
1.3 结果展示
经过合规流程采集分析后得到的数据示例:
爬取结果1-笔记数据: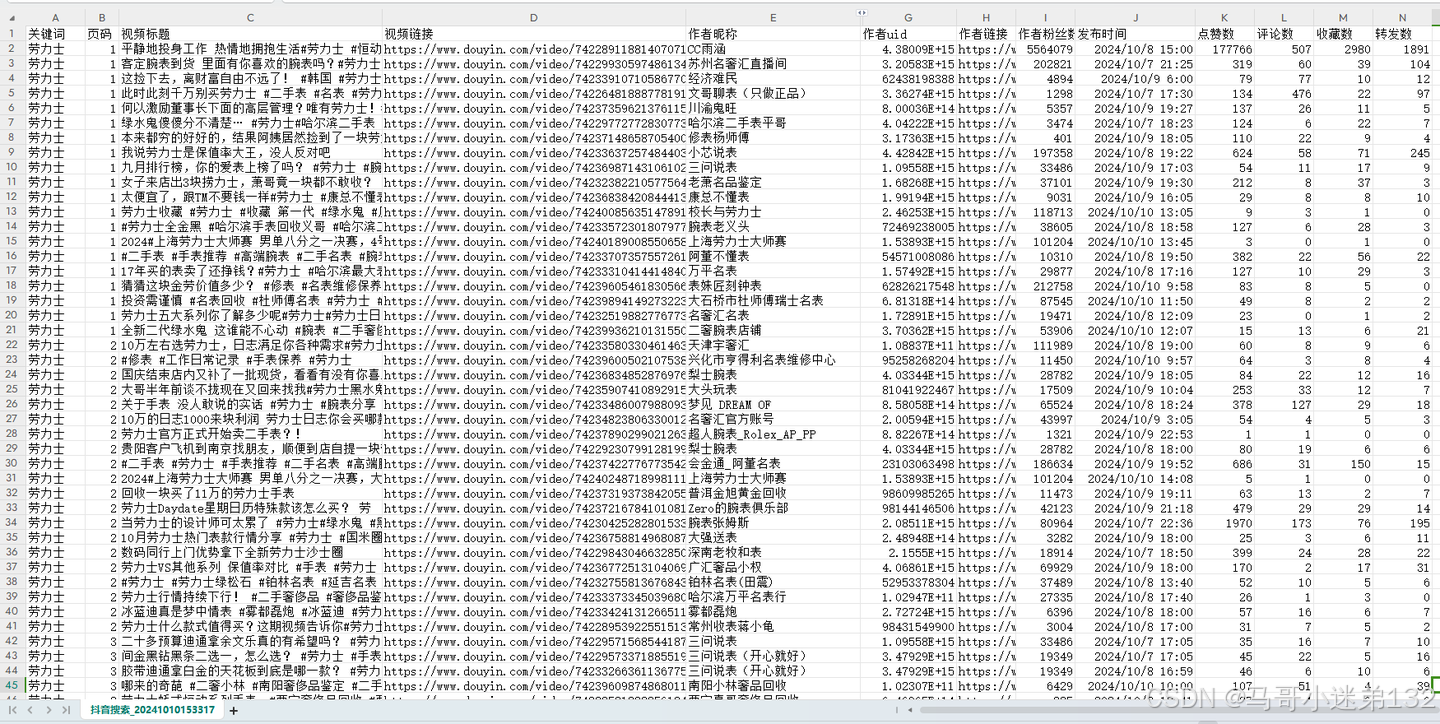
爬取结果2-评论数据: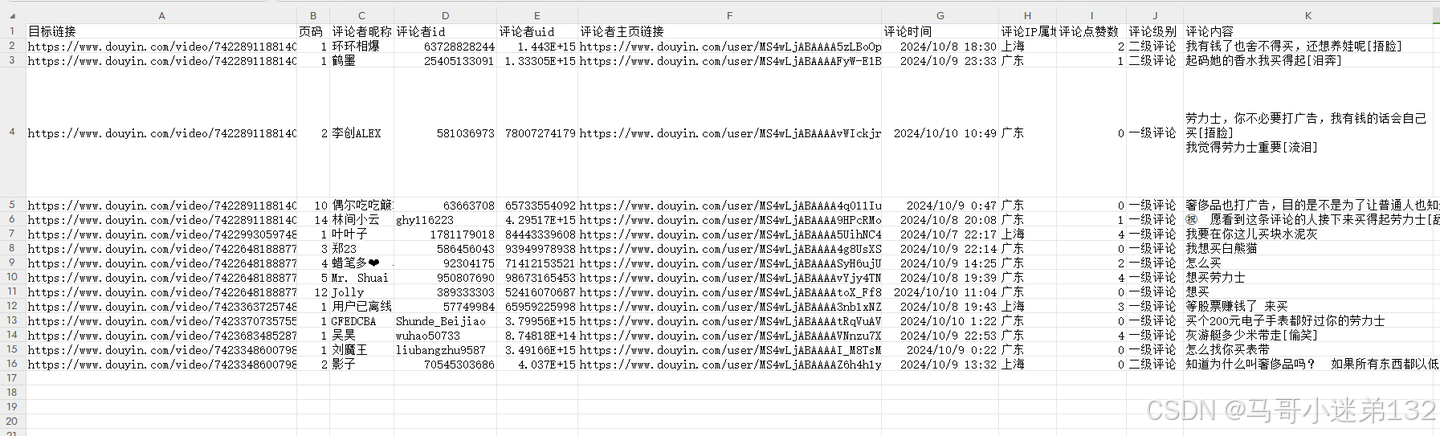
1.4 演示视频
软件运行演示: 【软件演示】dy评论区采集工具,支持2种模式:指定关键词和指定作品链接:
bilibili.com/video/BV1fH21YEEDV
1.5 软件说明
软件需符合相关法律法规的情况下使用。几点重要说明,请详读了解:
- Windows用户可直接双击打开使用,无需Python运行环境,非常方便!
- 软件通过接口协议爬取,并非通过模拟浏览器等RPA类工具,稳定性较高!
- 先在cookie.txt中填入自己的cookie值,方便重复使用(内附cookie获取方法)
- 支持筛选:排序方式(综合排序/最新发布/最多点赞)和发布时间(不限/一天内/一周内/半年内)
- 支持多个的设置项有:笔记关键词、笔记链接、评论关键词、IP属地
- 爬取过程中,每爬一页,存一次csv。并非爬完最后一次性保存!防止因异常中断导致丢失前面的数据(每条间隔1~2s)
- 爬取过程中,有log文件详细记录运行过程,方便回溯
- 爬取过程中,评论筛选同时进行。并非全部评论爬完再一次性筛选!所以效率较高!
- 笔记csv含13个字段,有:关键词,页码,视频标题,视频链接,作者昵称,作者uid,作者链接,作者粉丝数,发布时间,点赞数,评论数,收藏数,转发数
- 评论csv含11个字段,有:目标链接,页码,评论者昵称,评论者id,评论者uid,评论者主页链接,评论时间,评论IP属地,评论点赞数,评论级别,评论内容
以上。
二、实现技术栈
2.1 概要技术
软件全部模块采用python语言开发,主要分工如下:
tkinter:GUI软件界面
requests:在合法合规前提下进行数据请求
json:解析符合规定获取到的响应数据
pandas:保存csv结果、在合法范围内进行数据清洗
logging:日志记录操作过程,以便检查合规性
出于版权以及确保合法合规使用的考虑,暂不公开源码,仅向符合使用条件且遵守相关规则的用户提供软件使用。
2.2 细分模块
软件界面核心代码:
# 创建主窗口
root = tk.Tk()
root.title('爬小红书搜索评论软件v1.1')
# 设置窗口大小
root.minsize(width=900, height=650)
爬虫部分代码:
# 发送请求
r = requests.get(url, headers=h1)
# 接收响应数据
json_data = r.json()
保存结果数据核心代码:
# 保存数据到DF
df = pd.DataFrame(
{
'笔记链接': 'https://www.xiaohongshu.com/explore/' + note_id,
'笔记链接_长': note_url2,
'页码': page,
'评论者昵称': nickname_list,
'评论者id': user_id_list,
'评论者主页链接': user_link_list,
'评论时间': create_time_list,
'评论IP属地': ip_list,
'评论点赞数': like_count_list,
'评论级别': comment_level_list,
'评论内容': content_list,
}
)
# 保存到csv
df.to_csv(self.result_file2, mode='a+', header=header, index=False, encoding='utf_8_sig')
日志记录功能核心代码:
def get_logger(self):
self.logger = logging.getLogger(__name__)
# 日志格式
formatter = '[%(asctime)s-%(filename)s][%(funcName)s-%(lineno)d]--%(message)s'
# 日志级别
self.logger.setLevel(logging.DEBUG)
# 控制台日志
sh = logging.StreamHandler()
log_formatter = logging.Formatter(formatter, datefmt='%Y-%m-%d %H:%M:%S')
# info日志文件名
info_file_name = time.strftime("%Y-%m-%d") + '.log'
# 将其保存到特定目录下
case_dir = r'./logs/'
info_handler = TimedRotatingFileHandler(filename=case_dir + info_file_name,
when='MIDNIGHT',
interval=1,
backupCount=7,
encoding='utf-8')
self.logger.addHandler(sh)
sh.setFormatter(log_formatter)
self.logger.addHandler(info_handler)
info_handler.setFormatter(log_formatter)
return self.logger
三、功能介绍
3.0 填写cookie
在开始进行合规的数据收集分析前,使用者需将自己通过合法途径获取的 cookie 值填入 cookie.txt 文件。同时,请务必严格遵守平台对于 cookie 使用的相关规定。
cookie获取方法: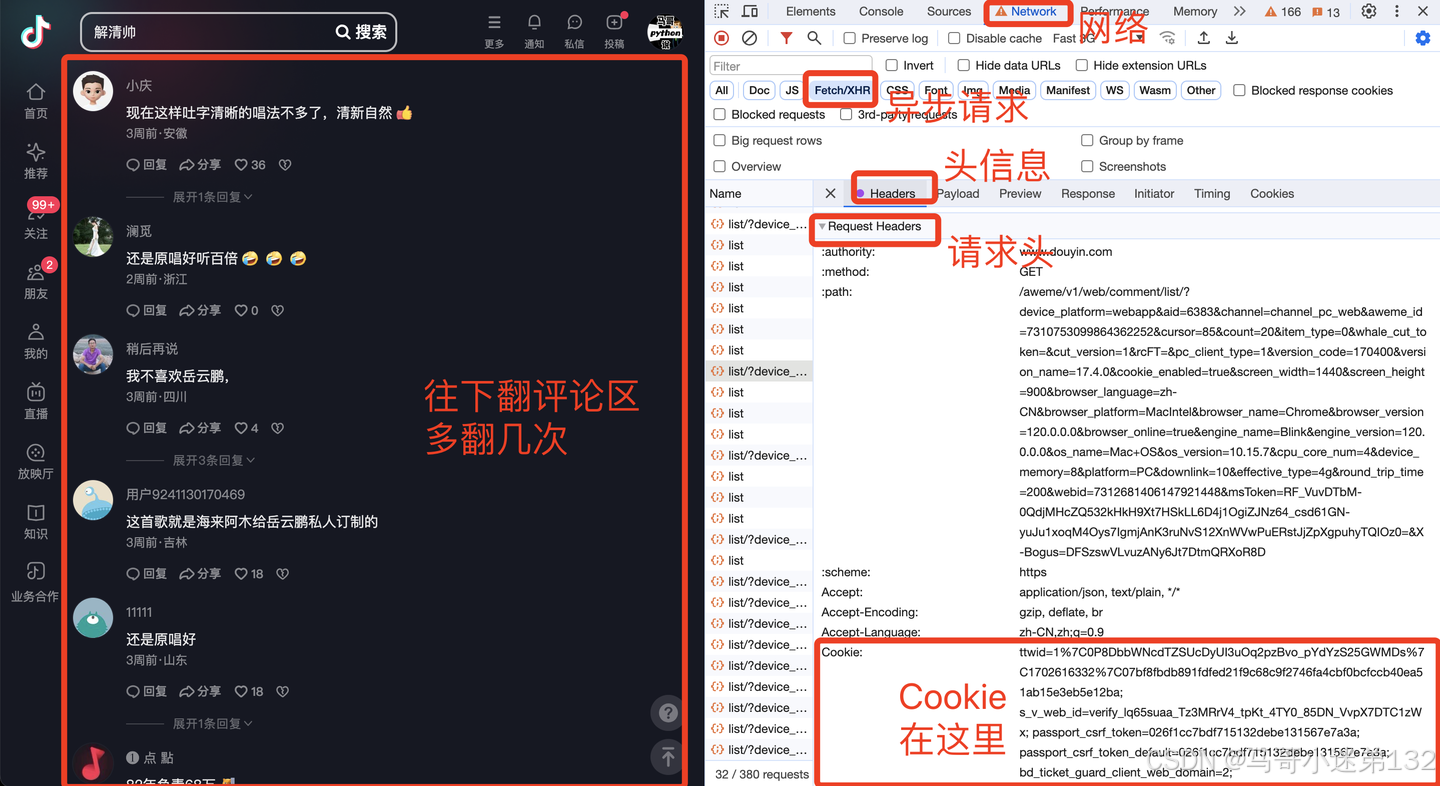
3.1 根据关键词爬评论
爬取思路:作品关键词->作品链接->评论
先填写左上区的笔记筛选项,再填写右上区的评论筛选项,点击按钮 1 进行合规的数据收集操作。。
3.2 根据作品链接爬评论
爬取思路:作品链接->评论
先填写中上区的作品链接,再填写右上区的评论筛选项,点击按钮 2 进行合规的数据收集操作。。

















 300
300

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









