






地址空间_RISC与CISC
ARM中怎么访问寄存器?就像访问内存一样
怎么访问寄存器?用指针:
unsigned int *p = 0x40010800; // p等于某个寄存器的地址
*p = val; // 写这个地址,也就是写这个寄存器
val = *p; // 读寄存器
int a;
unsigned int *p = &a; // p等于“a的地址”
*p = val; // 写这个地址,就是写a
val = *p; // 读这个地址,就是读a
在ARM CPU看来,内存,IO的操作是一样的
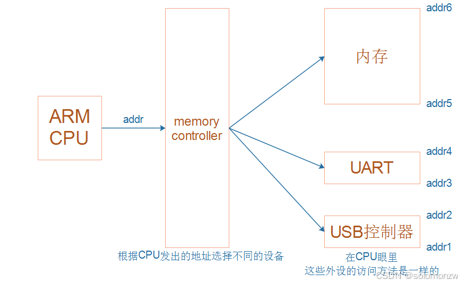
在X86架构中内存和IO是分开的
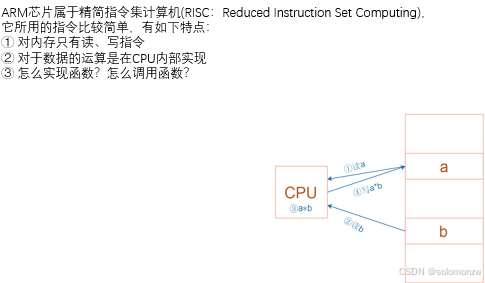
RISC
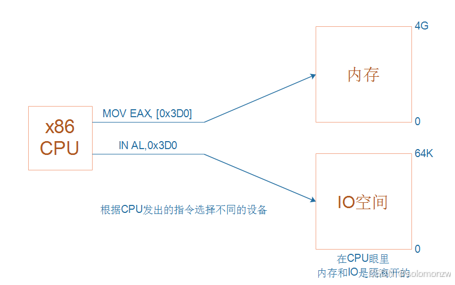
ARM芯片属于精简指令集计算机(RISC:Reduced Instruction Set Computing),它所用的指令比较简单,有如下特点:
① 对内存只有读、写指令
② 对于数据的运算是在CPU内部实现
③ 使用RISC指令的CPU复杂度小一点,易于设计
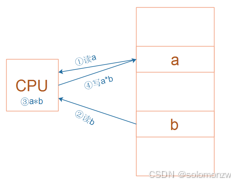
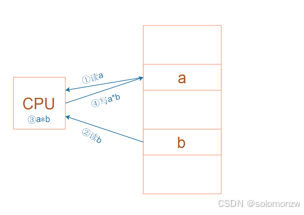
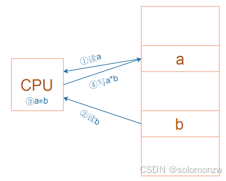
对于左图所示的乘法运算a = a * b,
在RISC中要使用4条汇编指令:
① 读内存a
② 读内存b
③ 计算a*b
④ 把结果写入内存
CISC
x86属于复杂指令集计算机(CISC:Complex Instruction Set Computing),
它所用的指令比较复杂,比如某些复杂的指令,它是通过“微程序”来实现的。
比如执行乘法指令时,实际上会去执行一个“微程序”,
在“微程序”里,
一样是去执行这4不操作:
① 读内存a
② 读内存b
③ 计算a*b
④ 把结果写入内存
但是对于程序员来说,
他看不到“微程序”,
他好像用一条指令就搞定了这一切!
RISC和CISC比较
CISC的指令能力强,单多数指令使用率低却增加了CPU的复杂度,指令是可变长格式;
RISC的指令大部分为单周期指令,指令长度固定,操作寄存器,对于内存只有Load/Store操作CISC支持多种寻址方式;
RISC支持的寻址方式CISC通过微程序控制技术实现;
RISC增加了通用寄存器,硬布线逻辑控制为主,采用流水线CISC的研制周期长RISC优化编译,有效支持高级语言
好的!我用生活化的比喻帮你理解CISC和RISC的区别:
CISC(复杂指令集)
👉 像一个瑞士军刀:
- 功能多(一条指令能完成复杂操作,比如直接操作内存数据),但很多功能不常用。
- 设计复杂(刀上各种小工具互相干扰,增加制造难度),研发周期长。
- 操作步骤不固定(指令长度可变,像不同大小的快递包裹,分拣起来麻烦)。
- 支持多种“找东西”方式(寻址方式),比如直接算地址、间接找地址等。
- 控制原理像“说明书”(微程序控制:用预先写好的代码解释复杂指令)。
典型代表:Intel的x86架构(家用电脑CPU)。
RISC(精简指令集)
👉 像一个高效流水线工厂:
- 只保留最常用的功能(指令简单,大部分1个时钟周期完成),比如操作寄存器,内存只能通过专门的Load/Store指令访问。
- 设计简单(指令长度固定,像统一规格的零件,流水线处理超快)。
- 支持少数高效的“找东西”方式(寻址方式少,比如直接算地址)。
- 控制原理像“自动化流水线”(硬布线逻辑:电路直接执行指令,速度快)。
- 编译器优化强(像智能流水线调度员,能帮高级语言生成高效代码)。
典型代表:ARM架构(手机/平板芯片)、RISC-V(新兴开源架构)。
对比总结
| 场景 | CISC | RISC |
|---|---|---|
| 指令复杂度 | 复杂,能直接操作内存 | 简单,只能操作寄存器 |
| 设计理念 | "多功能但笨重" | "少而精,追求速度" |
| 适用场景 | 传统PC(需要兼容复杂指令) | 移动设备、嵌入式(省电高效) |
| 现代发展 | 二者界限模糊(比如Intel也用流水线) |
打个比方:
CISC像老教授——知识渊博但反应慢;
RISC像体育生——专注几个动作,但速度爆发力强!
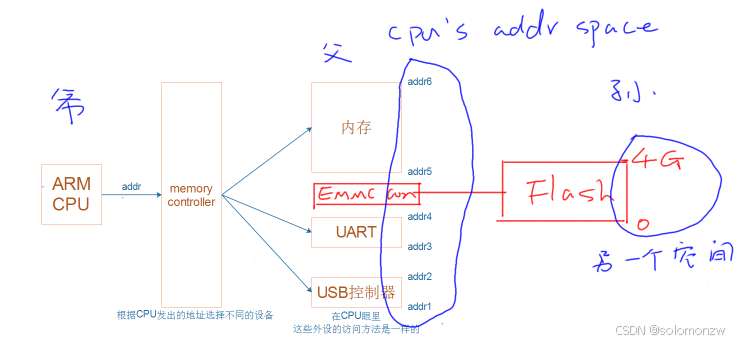
这张图描述了 CPU 与各种外设或存储器之间是如何通过“地址”联系起来的。可以把它理解成:
-
CPU 拥有一个统一的“地址空间”(图中右边标注了 0~4GB):
- 对 32 位 CPU 来说,所有的地址都在这 4GB 范围内。
- 不管是访问内存、访问 eMMC/Flash 还是访问其他外设(UART、USB 控制器),在 CPU 看来都是在读写某个“地址”。
-
内存控制器(Memory Controller) 就像一个“交通枢纽”或“分配中心”:
- 当 CPU 发出对某个地址的访问请求时,内存控制器会根据地址范围来决定,这次访问到底应该路由到内存、还是 eMMC、还是其他外设。
- 例如:
- 如果地址在某个区间(比如 0x8000_0000 ~ 0x8FFF_FFFF),就映射到内存;
- 如果地址在另一个区间(比如 0x9000_0000 ~ 0x9FFF_FFFF),就映射到 eMMC;
- 再比如 0x1000_0000 ~ 0x1000_FFFF 可能映射到 UART 寄存器;
- …等等。
-
eMMC / Flash / 外设(UART、USB 控制器) 只是在地址空间中占了一部分区域:
- CPU 通过读写对应地址,就能控制或获取这些外设的数据。
- 从 CPU 的角度看,它只是在访问一段内存地址;
- 实际上,访问请求被内存控制器转发给了真正的硬件(eMMC、UART、USB 等等)。
-
为什么说“父”是 CPU 的地址空间,“子”是 eMMC、Flash 等?
- 可以理解为:CPU 的地址线是“父级”,而各种硬件设备是“子级”。
- 这些硬件都挂在 CPU 的地址总线上,不同的地址段对应不同的硬件。
- CPU 只认地址,不直接知道具体是哪块硬件——由内存控制器来“做翻译”和“分配”。
通俗比喻
- 想象 CPU 是一个人,他只有一个“电话本(地址空间)”,里面记录了 0~4G 的号码(地址)。
- 内存控制器 像一个“电话总机”或“前台”,当 CPU 拨打某个号码(读写某个地址)时,前台决定把这通电话接到“内存”部门,还是“eMMC”部门,还是“UART”部门。
- 对 CPU 而言,他只知道“我在打某个号码”,并不知道背后是具体哪位接电话(哪块硬件响应)。
- 最终,不同号码对应了不同硬件,就像不同分机
- CPU 只有一套统一的 4GB 地址空间(因为是 32 位)。
- 内存控制器 负责把不同地址段映射到不同硬件(内存、eMMC、Flash、UART、USB 控制器等)。
- 对 CPU 来说,读写某个地址就是读写某块硬件;对硬件来说,只在特定地址段上做出响应。
- 这就是嵌入式系统中常见的“总线 + 地址映射”机制。
eMMC 就是一块把 Flash 存储和控制器封装在一起的“小硬盘”,系统只需用标准协议去读写它,既省空间又减少软件开发难度,广泛用于手机、平板等嵌入式设备。
ARM内部寄存器
RISC
ARM芯片属于精简指令集计算机(RISC:Reduced Instruction Set Computing),它所用的指令比较简单,有如下特点:
① 对内存只有读、写指令
② 对于数据的运算是在CPU内部实现
③ 使用RISC指令的CPU复杂度小一点,易于设计
对于左图所示的乘法运算a = a * b,
在RISC中要使用4条汇编指令:
① 读内存a
② 读内存b
③ 计算a*b
④ 把结果写入内存
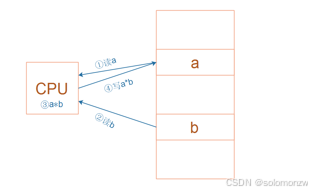
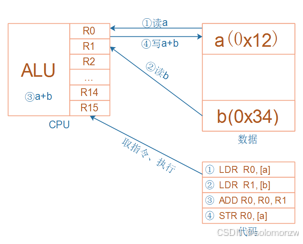
问题:在CPU内部,用什么来保存a、b、a*b ?
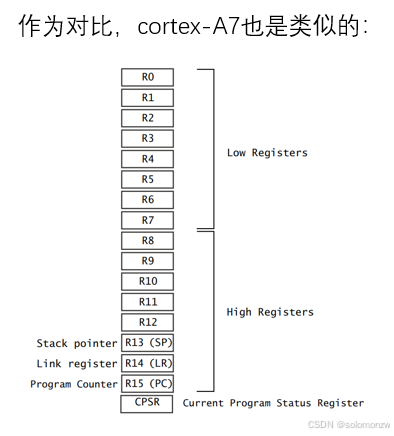
无论是cortex-M3/M4,还是cortex-A7,
CPU内部都有R0、R1、……、R15寄存器;
它们可以用来“暂存”数据。
对于R13、R14、R15,还另有用途:
R13:别名SP(Stack Pointer),栈指针
R14:别名LR(Link Register),用来保存返回地址
R15:别名PC(Program Counter),程序计数器,表示当前指令地址,写入新值即可跳转
M3/M4/A7 CPU内部寄存器

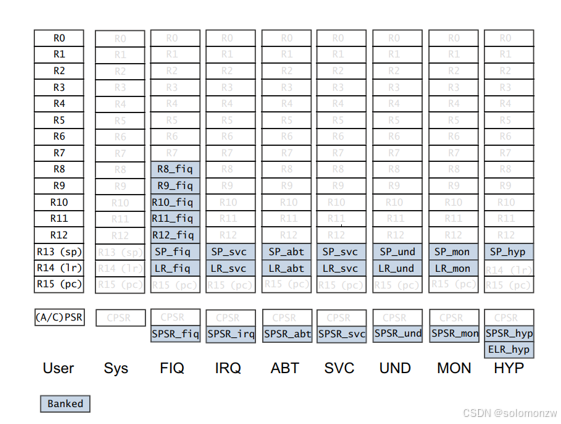
好的!我用生活化的比喻来解释这张图中的寄存器结构,保证你5分钟就能看懂:
1. 寄存器银行 = 快递柜 + 急救包
想象你的手机/电脑里有一个「超级快递柜」,柜子分成不同颜色的格子(对应不同处理器模式)。每个格子里的快递盒(寄存器)有的通用(比如R0-R7),有的专用(比如R15是程序计数器),还有的格子放了「急救包」(特殊寄存器CPSR/SPSR)。
2. 为什么要分这么多模式?
👉 就像你生活中不同场合用不同工具:
- 用户模式(User):日常搬砖模式,只能用普通快递盒(R0-R15),权限低。
- 中断模式(IRQ/FIQ):突然有紧急电话(比如你按了音量键),系统立刻切换到「中断快递柜」,用专属快递盒(R8_fiq/R9_fiq等),避免和日常搬砖的数据搞混。
- 超级用户模式(SVC):管理员模式,能调用高级权限(比如安装App)。
- 其他模式(ABT/UND等):类似「应急通道」,处理程序崩溃、未知指令等意外。
3. 重点看「FIQ快递柜」的特殊设计
快速中断模式(FIQ)的格子最特别:
- 专属快递盒:R8_fiq到R14_fiq,专门给紧急任务用。
- 不排队:普通中断(IRQ)要和其他程序抢快递盒,FIQ直接用自己的,响应速度更快。
- 类比:普通快递员要排队进小区,FIQ快递员有专属通道,随叫随到!
4. 底部的「急救包」是做什么的?
特殊寄存器CPSR和SPSR就像「急救包」:
- CPSR:记录当前状态(比如你是用户模式还是中断模式)。
- SPSR_xxx:每次切换模式时,把原来的状态存档(比如从用户模式切到IRQ模式,存档用户模式的CPSR到SPSR_irq)。
- 类比:你突然被叫去开会,先拍一张工位照片存档(SPSR),回来时按照片恢复现场。
终极总结
| 组件 | 生活比喻 | 作用 |
|---|---|---|
| R0-R12 | 通用快递盒 | 日常搬砖存数据 |
| R13(SP) | 临时货架管理员 | 记录当前货架(栈)的位置 |
| R14(LR) | 返程机票 | 记录执行完任务后要回哪里 |
| R15(PC) | 任务清单指针 | 指向下一条要执行的指令 |
| CPSR/SPSR | 工位状态存档照片 | 保存和恢复处理器状态 |
一句话理解:
处理器像一家快递公司,不同场景(模式)用不同的快递柜(寄存器),紧急任务(FIQ)有专属通道,急救包(CPSR)随时存档恢复现场,保证高效不乱套!
M3/M4比较两个数是,结果并保存在哪里
对于cortex-M3/M4,还要一个Program Status Register
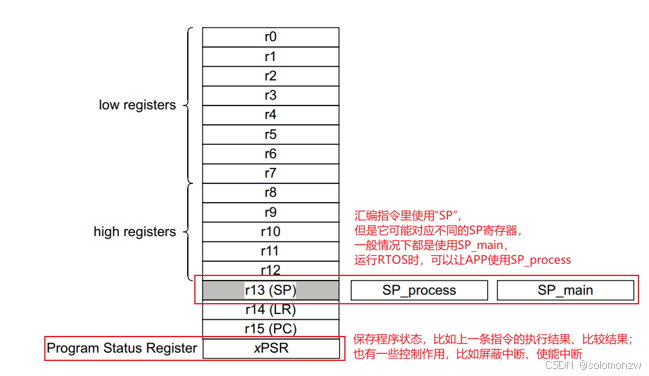
M3/M4:xPSR实际上对应3个寄存器APSR/IPSR/EPSR
对于cortex-M3/M4来说,
xPSR实际上对应3个寄存器:
① APSR:Application PSR,应用PSR
② IPSR:Interrupt PSR,中断PSR
③ EPSR:Exectution PSR,执行PSR
这3个寄存器的含义如右图所示
这3个寄存器,可以单独访问:
MRS R0, APSR ;读APSR
MRS R0, IPSR ;读IPSR
MSR APSR, R0 ;写APSR
这3个寄存器,也可以一次性访问:
MRS R0, PSR ; 读组合程序状态
MSR PSR, R0 ; 写组合程序状态
所谓组合程序状态,入下图所示:

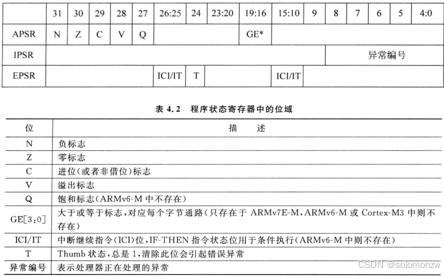
好的!我这就用「汽车仪表盘」的比喻帮你轻松理解这张图的内容——程序状态寄存器就像一台车的“状态显示屏”,实时告诉你车子(处理器)现在跑得怎么样了:
1. 仪表盘三大区域
程序状态寄存器分三块,像汽车仪表盘的三个显示屏:
- APSR:车速/油表(记录车子跑起来的状态)
- IPSR:故障灯(显示哪里出问题了)
- EPSR:自动驾驶状态(记录车子怎么跑的)
2. APSR区——核心仪表(基础状态)
👉 像车速、油量、水温表:
- N(负标志) → 油表负数警告(算数结果为负数时亮红灯)
- Z(零标志) → 车速为零提示(计算结果为0时亮灯,比如刹车踩到底)
- C(进位标志) → 油量超上限提示(比如算加法时超过油箱容量,油表爆了)
- V(溢出标志) → 发动机过热警告(计算结果太大,超出正常范围)
- Q(饱和标志) → 刹车过热提示(某些操作导致数值卡在极限值,ARMv6-M车型没有这个表)
- GE[3:0] → 四驱轮胎状态(比如四个轮胎是否都抓地良好,但Cortex-M3车型没这功能)
3. IPSR区——故障诊断(异常处理)
👉 像故障代码显示屏:
- 异常编号 → 故障代码(比如显示“Error 12”代表发动机故障,对应具体的错误类型)
- 例子:代码1=刹车失灵,代码2=电池没电...
4. EPSR区——驾驶模式(执行状态)
👉 像自动驾驶系统显示屏:
- ICI/IT → 待执行的自动驾驶指令(比如:“前方路口左转”还没执行完就被红灯打断)
- ARMv6-M车型没有这个功能
- T(Thumb状态) → 必须保持“自动驾驶模式”(这个灯必须常亮,如果灭了车子直接抛锚报错)
总结表格
| 标志位 | 汽车比喻 | 触发场景 |
|---|---|---|
| N | 油量负数警告灯 | 计算结果为负数(比如5-10=-5) |
| Z | 车速为零提示 | 计算结果为0(比如10-10=0) |
| C | 油表爆满提示 | 加法进位(比如255+1=0且进位) |
| V | 发动机过热警告 | 计算结果溢出(比如128+128=-256) |
| 异常编号 | 故障代码 | 程序崩溃/硬件错误(比如除零错误) |
| T=1 | 自动驾驶模式常亮 | 必须保持!否则直接死机 |
一句话理解:
程序状态寄存器就像智能汽车的仪表盘,N/Z/C/V告诉你算数结果正不正常,异常编号告诉你哪里坏了,T标志确保车子永远在自动驾驶状态!
A7:比较两个数时,结果保存在哪?
对于cortex-A7,还要一个Current Program Status Register

这是一个关于 ARM处理器状态寄存器(CPSR/SPSR) 的各个标志位的解释,我用生活化的比喻帮你理解这些专业术语:
状态寄存器的各个标志位就像汽车的「仪表盘」
每个指示灯都告诉你处理器的「运行状态」,以下是通俗版解读:
1. 运算结果指示灯(ALU运算后的状态)
| 标志位 | 名称 | 通俗解释 |
|---|---|---|
| N | Negative(负数) | 运算结果像温度计显示-5℃(结果为负,N=1) |
| Z | Zero(零) | 计算结果像空钱包(结果为0,Z=1) |
| C | Carry(进位) | 算钱时超过钱包容量,要掏第二个钱包(加法进位/减法借位,C=1) |
| V | Overflow(溢出) | 温度计最高50℃,实际温度60℃(结果超出数据范围,V=1) |
| Q | Saturation(饱和) | 音量调节到最大后继续调,实际音量不再变化(结果被限制,Q=1) |
2. 工作模式开关(控制处理器行为)
| 标志位 | 名称 | 通俗解释 |
|---|---|---|
| J | Jazelle状态 | 手机同时支持Java应用和原生应用(特殊指令加速Java字节码执行) |
| GE[3:0] | SIMD模式 | 像洗衣机同时洗4件衣服(并行处理多个数据) |
| IT[7:2] | 条件执行 | 红绿灯控制车流(If-Then条件决定后续指令是否执行) |
3. 系统控制开关(全局设置)
| 标志位 | 名称 | 通俗解释 |
|---|---|---|
| E | Endianness(字节序) | 写日期是「年-月-日」还是「日-月-年」(数据存储顺序,E=1表示大端模式) |
| A | Asynchronous Abort | 关闭突发任务打断(A=1时,不处理硬件异常事件) |
| I | IRQ屏蔽 | 开启「请勿打扰」模式(I=1时,不响应普通中断) |
| F | FIQ屏蔽 | 紧急事件专用通道(F=1时,不响应快速中断) |
| T | Thumb状态 | 使用精简指令集(像说简写俚语,T=1时执行Thumb指令) |
4. 权限模式选择器(M[4:0])
| 模式值 | 模式名称 | 通俗解释 |
|---|---|---|
| 0b10000 | User(用户模式) | 普通APP运行模式(权限受限) |
| 0b10001 | FIQ(快速中断模式) | 处理紧急事件(如火灾警报) |
| 0b10010 | IRQ(普通中断模式) | 处理常规事件(如微信消息通知) |
| 0b10011 | Supervisor(管理模式) | 系统管理员模式(可执行特权指令) |
实际应用场景
-
条件跳转:
CMP R0, R1 ; 比较R0和R1 BGT label ; 如果R0>R1(N=0且 Z=0且 V=0),则跳转到label -
中断处理:
-
收到中断时,处理器自动切换模式(如从User切到IRQ模式)并保存状态到SPSR
-
-
SIMD加速:
; 使用GE标志位加速图像处理 USADA8 R0, R1, R2, R0 ; 同时处理4对像素数据
总结
这些状态位就像汽车的仪表盘和控制系统:
-
🚨 状态标志(N/Z/C/V/Q):告诉你「引擎」(ALU)的实时状态
-
🔧 控制开关(J/GE/IT/E/A/I/F/T):调整「驾驶模式」
-
🚦 权限模式(M[4:0]):决定你能开普通道路还是专用车道
理解这些标志位,就能像老司机一样精准控制处理器的行为!
ARM汇编
ARM汇编概述ARM汇编概述
好的!我用「手动挡 vs 自动挡」的比喻来解释这个问题,保证你3分钟就能看懂:
1. 传统问题:手动切换档位(Thumb/ARM指令集)
早期的ARM处理器像一辆手动挡汽车,开发者需要自己决定什么时候用「高速档」(ARM指令集)和「省油档」(Thumb指令集):
- ARM指令集(32位) → 高速档:动力强(执行快),但油耗高(代码体积大)。
- Thumb指令集(16位) → 省油档:油耗低(代码紧凑),但动力弱(需要更多指令)。
痛点:每次切换档位(调用不同指令集的函数)都要手动操作,非常麻烦!
2. 怎么手动切换档位?
假设你要调用两个函数:
- 函数A(Thumb指令) → 省油档
- 函数B(ARM指令) → 高速档
你需要用「换挡杆」(PC寄存器)告诉CPU现在切到哪个档位:
-
调用函数A(Thumb):
- 把函数A的地址写入PC寄存器时,偷偷踩一脚离合(地址最低位BIT0设为1)。
- 例如:
PC = 函数A地址 + 1(相当于地址末尾补1,但实际跳转时会忽略这个1)。 - CPU看到BIT0=1,就切换到「省油档」(Thumb状态)。
-
调用函数B(ARM):
- 直接写入地址,保持BIT0=0。
- 例如:
PC = 函数B地址。 - CPU看到BIT0=0,切回「高速档」(ARM状态)。
吐槽:这就像开车时每过一个路口都要换挡,司机(开发者)累到崩溃!
3. 救星来了:Thumb2指令集(自动挡)
Thumb2像一辆自动挡汽车,彻底解决手动换挡的麻烦:
- 混合档位:允许在同一个函数里混用16位和32位指令(比如用16位指令处理简单操作,32位指令处理复杂计算)。
- 自动换挡:编译器会自动判断该用哪种指令,开发者不用再操心BIT0的设置。
- 性能平衡:代码体积接近Thumb(省油),性能接近ARM(高速)!
实际效果:
- 开发者写代码时,就像开自动挡汽车——只管踩油门(写逻辑),换挡交给编译器!
- 例如:一段循环中,条件判断用16位指令,数学计算用32位指令,无缝衔接。
对比总结
| 方案 | 比喻 | 优点 | 缺点 |
|---|---|---|---|
| 传统Thumb/ARM | 手动挡汽车 | 灵活控制性能/体积 | 切换繁琐,容易出错 |
| Thumb2 | 自动挡汽车 | 自动优化,代码高效简洁 | 需要编译器支持(现代工具链已解决) |
终极结论:
Thumb2的诞生,相当于让ARM处理器从「手动挡时代」迈入「自动挡时代」,开发者终于不用再和BIT0较劲了! 🚗💨
根据Cortex-A7的机制,PC寄存器BIT0的设置与指令集状态的关系是反直觉的。让我用「开关贴纸」的比喻来解释:
核心结论
- BIT0=1 → Thumb状态(贴红色贴纸)
- BIT0=0 → ARM状态(贴蓝色贴纸)
你提到的操作其实是反过来的:
调用函数A(Thumb指令)时设置BIT0=1(贴红标),调用函数B(ARM指令)时BIT0=0(贴蓝标)。
详细拆解(对照CPSR的T位)
1. BIT0是「状态贴纸」
- 当程序跳转到某个地址时,CPU会偷看地址的BIT0:
- 如果BIT0=1 → 撕下这个贴纸(BIT0会被硬件清零),同时把CPSR的T位置1(进入Thumb状态)。
- 如果BIT0=0 → 保持贴纸,把CPSR的T位置0(进入ARM状态)。
示例:
- 调用Thumb函数A:
PC = 函数A地址 | 1(BIT0=1,实际跳转到地址&0xFFFFFFFE,同时T=1)。 - 调用ARM函数B:
PC = 函数B地址(BIT0=0,T=0)。
2. 为什么需要这样设计?
- 硬件自动对齐:Thumb指令要求地址对齐到2字节(BIT0必须为0),ARM指令对齐到4字节(BIT0必须为0)。BIT0=1只是临时标记,实际跳转时会被清除。
- CPSR联动:BIT0的设置会自动更新CPSR的T位(如图3-6中的T位),无需手动修改CPSR。
对照你提到的CPSR图
图中明确标注了T位的作用:
- T=1:Thumb状态(对应BIT0=1的跳转操作)
- T=0:ARM状态(对应BIT0=0的跳转操作)
但T位本身不直接存储BIT0的值,而是由硬件在跳转时根据BIT0自动设置。
Thumb-2的改进
在Thumb-2指令集中,允许混合使用16/32位指令,但状态切换规则不变:
- 编译器会自动在Thumb函数内部插入32位指令,无需开发者手动设置BIT0。
- 例如:一个Thumb函数中既有16位比较指令,又有32位乘法指令,但全程保持T=1。
终极对比表
| 操作 | BIT0值 | 实际跳转地址 | CPSR.T位 | 指令集 |
|---|---|---|---|---|
PC = 函数地址 + 1 | 1 | 地址 & 0xFFFFFFFE | 1(Thumb) | Thumb/Thumb2 |
PC = 函数地址 | 0 | 地址 | 0(ARM) | ARM |
结论:BIT0=1选择的是Thumb状态,而非ARM状态!你的原始描述需要交换两者的对应关系。
有那么多指令集:ARM、Thumb、Thumb2,不好记啊!不用区分它们,不用担心,ARM公司推出了: Unified Assembly LanguageUAL,统一汇编语言,你不需要去区分这些指令集。
在程序前面用CODE32/CODE16/THUMB表示指令集:ARM/Thumb/Thumb2日常工作中,只需要这么几条汇编指令,从名字就可以猜出含义:MOV,LDR/STR,LDM/STM,AND/OR,ADD/SUB,B/BL,DCD,ADR/LDR,CMP后面再练习这些汇编指令
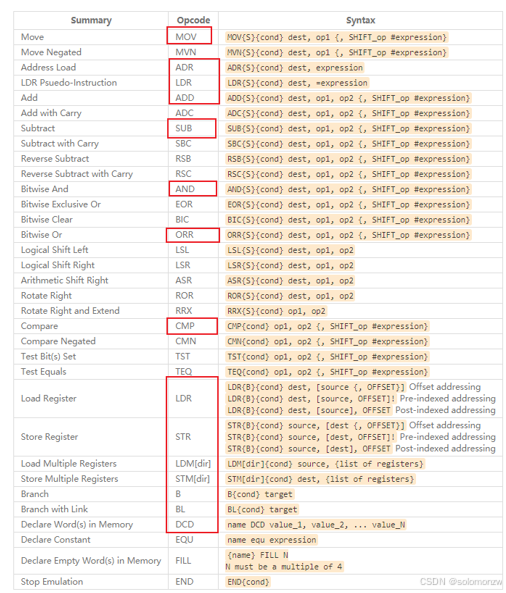
想深入学习汇编指令?没必要

汇编指令格式
汇编指令可以分为几大类:数据处理、内存访问、跳转、饱和运算、其他指令

以“数据处理”指令为例,UAL汇编格式为: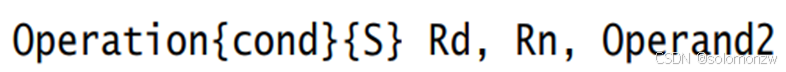
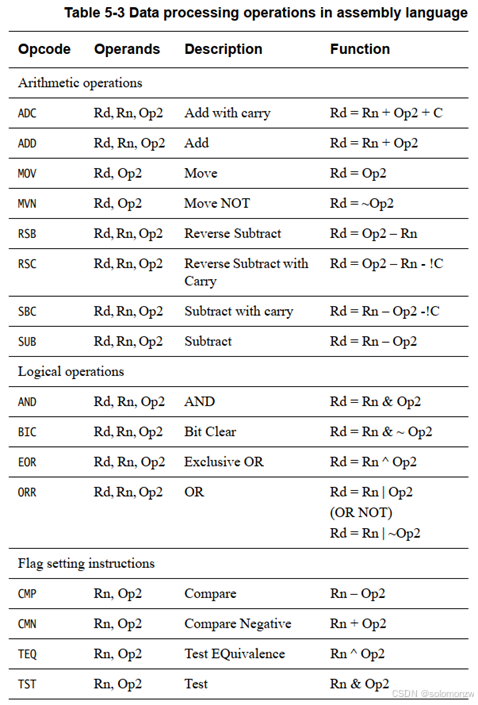
Operation表示各类汇编指令,比如ADD、MOV;
cond表示conditon,即该指令执行的条件;
S表示该指令执行后,会去修改程序状态寄存器;
Rd为目的寄存器,用来存储运算的结果;
Rn、Operand2是两个源操作数
Operation表示各类汇编指令,比如ADD、MOV;如下图:
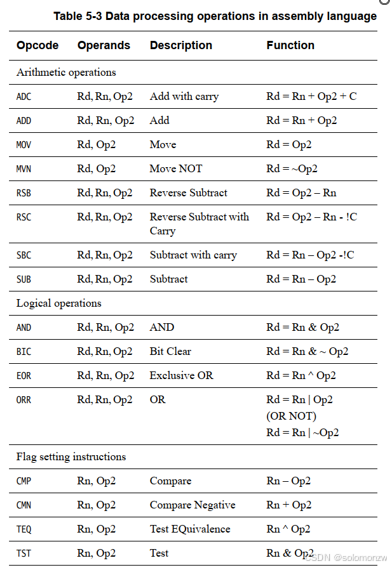
cond有多种取值,如下:
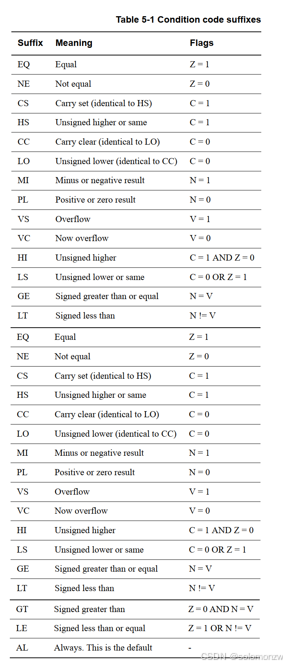
内存访问指令简介
读内存指令LDR/LDM:参考《DEN0013D_cortex_a_series_PG.pdf》P340、P341
写内存指令STR/STM:参考《DEN0013D_cortex_a_series_PG.pdf》P377、P378
LDR:Load Register;LDM:Load Multiple Register;
STR:Store Register;STM:Store Multiple Register。

(掏出螺丝刀在电路板上画出彩虹轨迹)咱们把LDR指令想象成快递小哥取快递的过程,拆解成三个神奇步骤:
一、基础版:搬箱子
LDR R3, [R2] @ 就像对R2说:兄弟,你家地址里放的快递(内存数据),我拿给R3啦!这里的操作就像:
- R2是仓库管理员(存储地址)
- 是仓库大门(内存访问)
- R3是快递接收人(目标寄存器)
二、升级版:智能快递车(地址模式)
- 前变址快递(提前报地址):
LDR R0, [R1, #4]! @ "!"像快递车自动更新地址:
▸ 先去R1家往东4米的位置取货
▸ 然后R1家的门牌号自动变成R1+4- 后变址快递(取完再更新):
LDR R0, [R1], #8 @ 像共享单车解锁:
▸ 先按R1的原地址取件
▸ 取完后R1自动+8(类似骑完车自动结账)三、特种快递(数据类型暗号)
LDRB R5, [R6] @ B=Byte → 搬1个微型快递箱(8位)
LDRH R7, [R8] @ H=Halfword → 搬中型箱(16位)
LDRSB R9, [R10] @ SB=Signed Byte → 搬带正负号的微型箱举个栗子🌰:
当用LDRB加载0xFF到32位寄存器时:
- 无符号:变成0x000000FF(像给箱子填充白色泡沫)
- 有符号:变成0xFFFFFFFF(像把黑色海绵塞满箱子)
四、实战秘籍(三秒选指令)
- 看到传感器数据用LDRSB(温度有正负)
- 处理图像像素用LDRH(RGB565格式常见)
- 循环搬数组必加"!"或后变址:
loop:
LDR R2, [R1], #4 @ 每次自动跳4字节
SUBS R3, R3, #1
BNE loop(突然用示波器画出爱心波形)记住这个魔法口诀:
"方括号里是仓库,感叹号是自动档,字母后缀定箱型,偏移就像GPS导航"
下次写驱动时,试着把printf改成用LDR指令在内存里"偷看"数据,体验底层编程的快乐!

(掏出快递扫码枪对准屏幕「滴——」)咱们把STR指令想象成「快递员存包裹」,用仓库管理流程拆解这张图:
一、基础操作:快递员存件
STR R3, [R2] @ 对R3说:兄弟,把你手里的快递(数据)存到R2仓库的地址!▸ 核心三要素:
R3= 快递员(要存的数据在R3里)[R2]= 仓库地址(R2是仓库管理员)- 默认存4字节大包裹(不写B/H时)
二、三种存件模式(重点!)
- 普通存件(不动仓库地址):
STR R0, [R1, #4] @ 操作指南:
▸ 找到R1仓库
▸ 往东走4米(+4字节偏移)
▸ 存入R0的包裹
▸ 仓库管理员R1的地址不变- 前变址存件(存完自动挪仓库):
STR R5, [R6, #8]! @ 注意感叹号!
▸ 先计算:新地址 = R6 + 8
▸ 把R5的包裹存到新地址
▸ 仓库管理员R6搬家到新地址(R6 = R6+8)- 后变址存件(存完才挪仓库):
STR R7, [R8], #-12 @ 括号外偏移
▸ 按R8原地址存R7的包裹
▸ 存完后R8自动-12(像快递车倒车)三、包裹类型暗号(Type后缀)
| 指令 | 包裹大小 | 比喻场景 |
|---|---|---|
STR | 4字节 | 存整箱矿泉水(32位) |
STRB | 1字节 | 存手机壳(8位) |
STRH | 2字节 | 存键盘(16位) |
举个栗子🌰:
STRB R1, [R2, #3] @ 操作分解:
1️⃣ 找到R2仓库地址
2️⃣ 往东走3米(地址+3)
3️⃣ 只存R1里最右边的1字节(像存手机壳进小格子)四、实战口诀(快递员秘籍)
- 处理传感器配置 → 用
STRB存8位控制字节 - 保存游戏得分 → 用
STRH存16位数值 - 批量存数组必用自动更新地址:
mov R2, #0 @ 初始化计数器
loop:
STR R3, [R1], #4 @ 每次存4字节并自动跳地址
ADD R2, R2, #1
CMP R2, #10
BLT loop(突然用快递单打印机打出指令表)魔法口诀:
「方括号里是仓库,感叹号是自动档,B存小件H存中件,偏移就像量尺子!」
下次写代码时,想象自己是指挥快递员的仓库管理员,用STR指令把数据精准投递到内存地址,体验「存包裹」的底层乐趣!

(掏出快递扫码枪在空气中画出指令轨迹)咱们把这张图想象成「智能货架搬运机器人」的工作手册,用仓库管理员的视角拆解这两个核心功能:
一、搬运模式:机器人移动策略(add_mode)
把寄存器组想象成货架上的快递箱,Rn是机器人的当前位置
LDMIA/STMIA → 后增模式(默认)举个栗子 🌰
假设要搬运4个箱子(R0-R3),地址变化如同机器人行走路线:
https://tva1.sinaimg.cn/large/007YVyKcly1h3j5q8zq6xj30m80b4dgf.jpg
-
IA模式(默认模式,快递员常用):
- 动作:先取快递,再向前走一步
- 代码:
LDMIA R4, {R0-R3} - 轨迹:
原地址R4 → 取R0 → R4+4 → 取R1 → R4+8 → ...(像边走边取货)
-
IB模式(超前派送,仅限ARM模式):
- 动作:先向前走一步,再取快递
- 代码:
LDMIB R4, {R0-R3} - 轨迹:
R4+4 → 取R0 → R4+8 → 取R1 → ...(像预判下一个货架)
-
DA/DB模式(反向操作,适合倒序场景):
- 场景:从高地址向低地址搬运(比如处理堆栈)
- 代码:
LDMDA R4, {R0-R3}(取完再后退) - 对比:
IA模式:地址越搬越高 → 适合向上生长 DA模式:地址越搬越低 → 适合向下回收
二、操作符秘籍:机器人的记忆开关(! 和 ∧)
1. 感叹号「!」——自动更新坐标
STM R0, {R1-R3}! @ 重点在感叹号!- 无感叹号:机器人搬完货物后,回到原点(R0不变)
- 有感叹号:机器人搬完后记住新位置(R0 = 最后地址+4)
- 实战场景:
STMIA R0!, {R1-R3} @ 存完R1-R3后,R0自动指向下一个空位
2. 帽子符「∧」——特殊模式标记
- 作用:影响状态寄存器(CPSR),常用于异常处理
- 举个栗子:从异常返回时恢复现场
LDMFD SP!, {R0-R3, PC}^ @ 同时恢复寄存器和程序状态
三、速记口诀(快递员专用)
地址模式四兄弟:
IA先搬再走(默认快递员)
IB先走再搬(预判型选手)
DA搬完后退(回收旧纸箱)
DB退后再搬(谨慎型操作)符号两件套:
感叹号是记忆贴 → 更新坐标不迷路
帽子符是警报器 → 状态切换要小心(突然用扫码枪在屏幕上画出流程图)下次写汇编时,把自己想象成调度机器人的仓库主管,用IA模式快速装车,用DB模式反向清点库存,体验像指挥交响乐一样操作寄存器的快感! 🚚💨
分支/跳转指令
参考《DEN0013D_cortex_a_series_PG.pdf》P327、P328、P329
核心指令是B、BL:
B:Branch,跳转
BL:Branch with Link,跳转前先把返回地址保持在LR寄存器中
BX:Branch and eXchange,根据跳转地址的BIT0切换为ARM或Thumb状态(0:ARM状态,1:Thumb状态)
BLX:Branch with Link and eXchange :根据跳转地址的BIT0切换为ARM或Thumb状态(0:ARM状态,1:Thumb状态)

(掏出导航仪画出指令地图)咱们把ARM跳转指令想象成「自驾游导航系统」,用旅行攻略的方式拆解这组指令:
一、基础导航:B指令 vs BL指令
B指令 = 单程旅行(不记录返程路线)
B target @ 说走就走,直接跳转到目的地▸ 应用场景:
- 循环内跳转(像在景区内反复逛同一个景点)
- 永久性跳转(像决定定居新城市)
BL指令 = 跟团游(导游自动记录返程点)
BL target @ 跳转前自动保存返回地址到LR寄存器▸ 核心机制:
- 把
下一条指令地址存入LR(R14)(像导游记下集合点) - 跳转到目标地址执行(带团出发)
- 用
BX LR或MOV PC, LR返回(游览完按原路返回)
举个栗子🌰:
main:
BL play_music @ 1.保存main的下一条地址到LR
@ 2.跳转到play_music函数
B exit @ 4.返回后继续执行
play_music:
... @ 3.执行音乐播放逻辑
BX LR @ 像导游喊"集合返回大巴车"二、智能导航:BX和BLX(状态切换黑科技)
关键原理:地址最低位(BIT0)是状态开关
- BIT0=0 → ARM状态(32位指令集,性能优先)
- BIT0=1 → Thumb状态(16位指令集,体积优先)
1. BX指令 = 跨界导航(切换CPU模式)
BX R0 @ 根据R0的BIT0切换状态▸ 典型场景:
- 从ARM代码跳转到Thumb代码(像从高速公路切到乡道)
- 函数指针调用(根据地址自动选择模式)
2. BLX指令 = 跨界跟团游(导航+记录)
BLX target @ 三合一操作:
1. 保存返回地址到LR
2. 根据目标地址BIT0切换状态
3. 跳转执行▸ 实战代码:
ARM_code:
BLX thumb_func @ 跳转到Thumb函数,LR自动保存返回地址
...
thumb_func:
.thumb @ 切换到Thumb模式
...
BX LR @ 返回ARM模式三、状态切换原理(导航系统底层逻辑)
BIT0的特殊处理:
- 跳转时CPU自动屏蔽BIT0(地址必须对齐)
- BIT0不参与实际地址计算(只用于模式判断)
目标地址 = 实际地址 & 0xFFFFFFFE @ 去掉BIT0后的真实地址
目标模式 = (目标地址 & 0x1) @ 根据BIT0判断状态举个栗子:
0x8000→ BIT0=0 → ARM模式0x8001→ BIT0=1 → Thumb模式- 实际执行地址都是
0x8000(地址自动对齐)
四、速记口诀 & 场景指南
导航系统三定律:
- 普通跳转用B,函数调用必选BL
- 切换状态用BX,跨界调用BLX
- BIT0是暗号,对齐地址别忘掉
场景选择矩阵:
| 场景 | 指令选择 | 比喻 |
|---|---|---|
| 循环/条件跳转 | B | 单程通勤 |
| 函数调用 | BL | 跟团游 |
| 动态库调用(模式未知) | BLX | 智能跨界旅行团 |
| 从异常返回 | BX LR | 紧急返航 |
(突然用导航仪生成流程图)下次写汇编时,想象自己是用BLX指令切换ARM/Thumb状态的跨界导游,体验在不同指令集间丝滑切换的编程乐趣!🚗💻
立即数
这样一条指令:MOV R0, #VAL意图是把VAL这个值存入R0寄存器。
问:VAL可以是任意值吗?答:不可以,必须是立即数。
问:为什么?答:假设VAL可以是任意数,”MOV R0, #VAL”本身是16位或32位,哪来的空间保存任意数值的VAL?所以,VAL必须符合某些规定。

(掏出乐高积木开始拼装)咱们把这张图想象成「魔法印章制作工坊」,用搭积木的方式拆解ARM立即数的生成规则:
一、核心原理:旋转复制术
规则说明 → 用1个字节(8位)的颜料,通过「旋转印章」在32位画布上盖章:
- 原料:任意8位数(如0xAB)
- 魔法操作:旋转偶数位(2/4/6...30位)
- 成品特征:图案在32位画布上呈现规律重复
二、三种魔法图案
1. 隔空盖章 → 0x00XY00XY 型
# 例:0xAB 旋转8位(相当于左移24位)
0xAB << 24 = 0xAB000000
0xAB << 8 = 0x0000AB00
合并 → 0xAB00AB00▸ 特征:两个相同片段被零隔开(像火车站台的间隔座椅)
2. 连续盖章 → 0xXYXYXYXY 型
# 例:0xAB 每次旋转8位
0xAB → 0x000000AB
0xAB<<8 → 0x0000AB00
0xAB<<16 → 0x00AB0000
0xAB<<24 → 0xAB000000
合并 → 0xABABABAB▸ 特征:四个字节完全重复(像瓷砖铺满整个地板)
3. 错位盖章 → 0xXY00XY00 型
# 例:0xCD 旋转16位
0xCD << 16 = 0xCD0000
再复制一次 → 0xCD00CD00▸ 特征:带零间隔的重复块(像钢琴的黑白键交替)
三、为什么必须遵守这些规则?
- 8位限制:ARM指令的立即数字段只能携带8位核心数据
- 偶数位移:4位移位字段(0-30)只能表示偶数位移(2位步长)
- 硬件加速:这种设计让CPU能用单条指令快速生成常用常数
四、实战口诀(三秒生成魔法数)
- 取色:选一个8位颜色(0x00-0xFF)
- 旋转:想象把颜色条绕成环形(旋转偶数格)
- 拓印:把环形展开成32位直线,重复部分自动显现
LDR伪指令
去判断一个VAL是否立即数,麻烦!
并且我就是想把任意数值赋给R0,怎么办?
可以使用伪指令:LDR R0, =VAL
“伪指令”,就是假的、不存在的指令。
注意LDR作为“伪指令”时,指令中有一个“=”,否则它就是真实的LDR(load regisgter)指令了。
编译器会把“伪指令”替换成真实的指令,比如:LDR R0, =0x12 0x12是立即数,那么替换为:MOV R0, #0x12
LDR R0, =0x12345678 0x12345678不是立即数,那么替换为:
LDR R0, [PC, #offset] // 2. 使用Load Register读内存指令读出值,offset是链接程序时确定的
……
Label DCD 0x12345678 // 1. 编译器在程序某个地方保存有这个值
(掏出魔法检测仪对准数值)咱们把判断过程想象成「数值变形术检测」,用快递分拣的流程来拆解:
一、立即数判断三步法
核心原理 → 这个数能不能通过「8位颜料+旋转印章」生成?
def 是立即数吗(数值):
1. 把数值拆成4个字节(如0x11223344 → 0x11,0x22,0x33,0x44)
2. 检查是否存在8位颜料,通过旋转得到整个图案
3. 旋转步长必须是偶数(2位对齐)举个栗子 🌰:
-
0xABABABAB → ✅
- 核心颜料:0xAB
- 旋转方式:每个字节都相同(像复制粘贴)
-
0x00120012 → ✅
- 核心颜料:0x12
- 旋转方式:间隔重复(像斑马线)
-
0x12345678 → ❌
- 四个字节全不同,找不到可旋转复制的8位核心
二、万能赋值咒语:LDR伪指令
魔法原理 → 让编译器自动判断数值类型,并施展对应法术:
LDR R0, =任意数值 @ 这是万能咒语!▸ 编译器会做两种处理:
-
立即数模式(检测通过):
MOV R0, #数值 @ 直接注入寄存器(最快) -
非立即数模式(检测失败):
LDR R0, [PC, #偏移量] @ 从内存加载 ... 秘密仓库 DCD 数值 @ 编译器偷偷存好数据
三、实战演示
案例1:0x12(立即数)
LDR R0, =0x12 → 编译器替换为 ↓
MOV R0, #0x12 @ 闪电注入!案例2:0x12345678(非立即数)
LDR R0, =0x12345678 → 编译器替换为 ↓
LDR R0, [PC, #0x08] @ 去内存取快递
...
秘密仓库:
DCD 0x12345678 @ 藏在代码段里的快递柜四、记忆口诀
判断立即数 →
「拆成四段找规律,八位颜料转圈圈,偶数步长要对齐,重复出现就过关!」
万能赋值 →
「不管数值多复杂,LDR等号走天下,编译器是魔法师,自动分拣顶呱呱!」
(突然用检测仪射出激光)下次写代码时,把自己想象成ARM编译器,用LDR R0, =数值一键召唤数值,体验像魔法师一样操纵寄存器的快感!✨
(掏出导航仪对准代码地图)咱们把ADR指令想象成「智能地址快递员」,用导航系统的工作原理拆解这张图:
一、核心功能:地址快递服务
ADR = Address Delivery Robot(地址配送机器人)
ADR R0, Loop @ 任务:把Loop标签的地址打包送到R0寄存器▸ 运作原理:
- 程序员告诉ADR机器人目标标签(如
Loop) - 机器人自动计算当前位置(PC)到目标的距离
- 生成最优路线(ADD/SUB指令)完成配送
二、工作流程拆解(快递员的一天)
示例代码:
ADR R0, Loop @ 快递员R0接单
Loop: @ 目的地坐标
ADD R0, R0, #1-
接单阶段:
- 编译器看到
ADR R0, Loop - 检查
Loop标签距离当前PC有多远
- 编译器看到
-
路径规划:
- 若距离近(±4095字节内),生成:
ADD R0, PC, #0x10 @ PC+16字节就是Loop地址 - 若距离远,改用
LDR指令从内存加载
- 若距离近(±4095字节内),生成:
-
自动派送:
- 链接器最终确定
#0x10的具体值 - 运行时CPU直接计算得出准确地址
- 链接器最终确定
三、为什么需要这个快递员?
-
地址漂移问题:
- 代码加载到内存后,实际地址会变
- ADR用相对地址(PC+X)自动适应变化
-
人类免计算福利:
- 原始方法:手工计算
(目标地址 - 当前PC) - ADR方法:写个标签就能自动获取地址
- 原始方法:手工计算
-
代码可移植性:
; 不用ADR的笨方法(地址写死) MOV R0, #0x8004 ; 使用ADR的智能方法 ADR R0, Loop▸ 当代码被复制到其他内存区域时,ADR方案依然有效
四、实战口诀(三秒掌握)
快递员三定律:
- 标签即地址 → 看见
ADR Rx,标签就是在取地址 - 相对位置 → 距离必须在±4KB范围内(快递员电量限制)
- 链接器赋能 → 最终地址由链接阶段计算
魔法口诀:
「ADR是个快递员,标签地址送门前;PC当起点,偏移自动算,链接器来充电源!」
下次写汇编时,试着用ADR指令获取循环开始地址,体验像点外卖一样获取内存地址的便捷!🚚💨

(掏出语法转换器对准代码)咱们把这张表想象成「中英双语编程词典」,用日常生活中的类比拆解两种汇编语法的核心差异:
一、基础元素差异(像不同国家的标点符号)
| 场景 | GNU(英语区) | armasm(中文区) | 生活类比 |
|---|---|---|---|
| 写注释 | @ 这是注释 | ; 这是注释 | 英文用@符号,中文用分号 |
| 十六进制数 | #&123 | #0x123 | 英语写&,中文写0x(像地址标签) |
二、逻辑运算符号(像不同的数学符号)
| 操作 | GNU写法 | armasm写法 | 记忆口诀 |
|---|---|---|---|
| 按位或 | ` | ` | :OR: |
| 按位与 | & | :AND: | &变AND,像缩写展开 |
| 左移右移 | << / >> | :SHL: / :SHR: | 箭头变单词,防止混淆 |
举个栗子 🌰:
// GNU写法
MOV R0, #1 << 3 | #0x10
// armasm写法
MOV R0, #1 :SHL: 3 :OR: #0x10三、数据定义(像快递包裹的尺寸标签)
| 数据类型 | GNU指令 | armasm指令 | 比喻 |
|---|---|---|---|
| 32位数据 | .word | DCD | 字(Word) vs 定义常数双字 |
| 16位数据 | .short | DCW | 短裤(Short) vs 定义常数字 |
| 8位数据 | .byte | DCB | 字节(Byte) vs 定义常数字节 |
实战演示:
// 定义数组(两种写法等效)
GNU: .word 0x1234, 0x5678
armasm:DCD 0x1234, 0x5678四、宏与条件编译(像写信的格式差异)
| 功能 | GNU写法 | armasm写法 | 类比 |
|---|---|---|---|
| 定义宏 | .macro 宏名 | MACRO | 信封开头写MACRO更正式 |
| 结束宏 | .endm | ENDM | 结尾标签带M更醒目 |
| 条件编译 | .if 条件 | IFDEF 条件 | GNU用点号,armasm用大写 |
代码对比:
// GNU条件编译
.if DEBUG_MODE
MOV R0, #1
.else
MOV R0, #0
.endif
// armasm条件编译
IFDEF DEBUG_MODE
MOV R0, #1
ELSE
MOV R0, #0
ENDIF五、速记口诀(三秒切换语法)
跨平台编程三定律:
- 注释符号换刀叉 →
@变; - 立即数前带标签 →
#&变#0x - 宏像信封要配对 →
.macro↔MACRO/ENDM
附加彩蛋:
- 包含头文件:GNU用
.include "file",armasm直接INCLUDE file - 声明全局变量:GNU用
.global,armasm拆成IMPORT/EXPORT
(突然用转换器生成双语代码)下次写汇编时,想象自己在做「语法翻译官」,用这张表快速切换GNU和armasm的写法,体验像切换输入法一样写代码的乐趣! 🌍💻
ARM汇编模拟器VisUAL
ARM UAL模拟器VisUAL
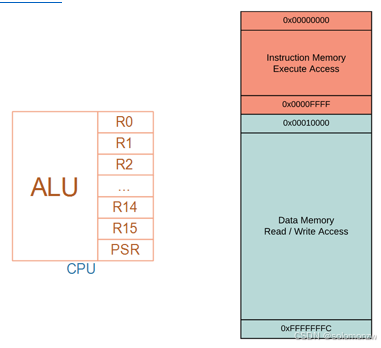
(掏出乐高积木开始拼装)咱们把这张图想象成「公司办公室布局图」,用日常工作的分工来比喻计算机的运作原理:
一、核心部门分工
1. 老板办公室(CPU)
- 工位组成:
- R0/R1/R2 → 老板手边的笔记本(临时记录重要数据)
- R14(LR) → 电话留言本(记录返回地址)
- R15(PC) → 待办事项清单(指向当前处理的任务)
- PSR → 状态公告板(记录工作是否出错/结果正负)
2. 财务部(ALU)
- 核心职责:
- 算账(加减乘除)
- 做决策(逻辑判断:比如是否批准预算)
- 比喻:所有数字相关的工作都从这里过手
三、仓库管理(内存系统)
1. 教科书仓库(橙色-指令内存)
- 地址范围:0x00000000~0x0000FFFF
- 权限:只读(像图书馆)
- 内容:写好的程序指令(比如"先加后跳转"的流程)
- 比喻:操作规程手册,必须严格按步骤执行
2. 账本仓库(浅蓝色-数据内存)
- 地址范围:0x00010000+
- 权限:可读写(像白板)
- 内容:程序运行时产生的数据(比如计算结果)
- 比喻:临时草稿纸,随时可以修改
四、工作流程演示(以1+2=3为例)
-
老板查看待办表(PC=R15):
地址0x00000100:去教科书仓库取"ADD R0, R1, R2"指令 -
财务部计算(ALU执行):
- 从R1笔记本读数字1
- 从R2笔记本读数字2
- 算出3写回R0笔记本
-
更新公告板(PSR):
- 记录"计算结果无溢出"
- 记录"结果是正数"
-
保存数据(STR R0, [0x00010000]):
- 把R0的3存到账本仓库的0x00010000地址
五、速记口诀
「CPU是老板管全局,ALU算账做苦力;指令仓库像教材,数据仓库如草稿!」
现在试着想象自己是指挥这个「公司」的程序员,通过写指令让各部门协同工作,体验像管理团队一样编写代码的乐趣! 🧩💻
VisUAL是一款ARM汇编模拟器,下载地址:https://salmanarif.bitbucket.io/visual/downloads.html如果无法下载,可以使用我们预先下载的,下载GIT资料后,位于这个目录:“STM32F103\开发板配套资料\软件\ARM汇编模拟器”使用方法:https://salmanarif.bitbucket.io/visual/user_guide/index.htmlVisUAL模拟的ARM板子如下图所示,它没有模拟外设,仅仅模拟了CPU、ROM、RAM。红色区域是ROM,不能读不能写,只能运行其中的程序;ROM区域本来可以读的,这是VisUAL的局限;RAM区域可读可写。
(掏出玩具实验箱开始演示)咱们把VisUAL想象成「ARM积木实验箱」,用玩玩具的方式拆解这个模拟器的核心特点:
一、核心三件套(实验箱基础组件)
-
CPU芯片 → 玩具箱的「大脑积木」
- 能执行你写的ARM指令(如MOV/ADD)
- 没有外设接口(像不带遥控器的智能车)
-
ROM红区 → 只读的「固定说明书」
- ✅ 可以运行写好的程序(像自动播放录音带)
❌ 模拟器限制:不能直接查看内容(实际硬件可以读) - 比喻:封装的魔法卷轴(程序烧录后不可修改)
- ✅ 可以运行写好的程序(像自动播放录音带)
-
RAM白区 → 可擦写的「草稿本」
- ✅ 自由读写数据(像用白板笔随意涂改)
- 存放变量、堆栈等临时数据
二、为什么这样设计?
-
专注学习核心:
- 像乐高基础版,只保留CPU和内存模块
- 适合练习纯汇编指令(如数据处理、跳转)
-
规避外设复杂性:
- 不模拟GPIO、UART等硬件(避免新手被电路干扰)
- 比喻:学自行车先练平衡,不加变速器和车灯
-
ROM限制的真相:
- 实际硬件ROM可读,但VisUAL为简化模型屏蔽此功能
- 开发团队解释:"保持模拟器轻量化"
三、能做什么?不能做什么?
| 能力范围 | 限制项 | 比喻 |
|---|---|---|
| ✅ 运行加减乘除指令 | ❌ 控制LED灯 | 能算数学题,不能开灯 |
| ✅ 练习内存读写(LDR/STR) | ❌ 读取ROM内容 | 能写草稿本,不能偷看魔法卷轴 |
| ✅ 调试循环和条件跳转 | ❌ 中断处理 | 能设计迷宫,不能设置警报器 |
四、快速上手指南
-
写第一个程序(在ROM区):
MOV R0, #42 @ 把数字42装进R0口袋 STR R0, [R1] @ 把R0的值存到R1指向的RAM地址 -
调试技巧:
- 点击「单步执行」观察寄存器变化(像侦探追踪线索)
- 在RAM窗口查看内存变化(像检查草稿本涂改痕迹)
-
避开雷区:
- 别尝试读写红色ROM区(会触发错误警报)
- 复杂外设需求换真实开发板(如STM32)
五、记忆口诀
「红区ROM跑程序,白区RAM随便改;不碰外设纯练功,汇编入门好搭档!」
现在打开VisUAL,试着写一段让R0从1加到10的代码,体验像搭积木一样学习ARM汇编的乐趣! 🧩💻
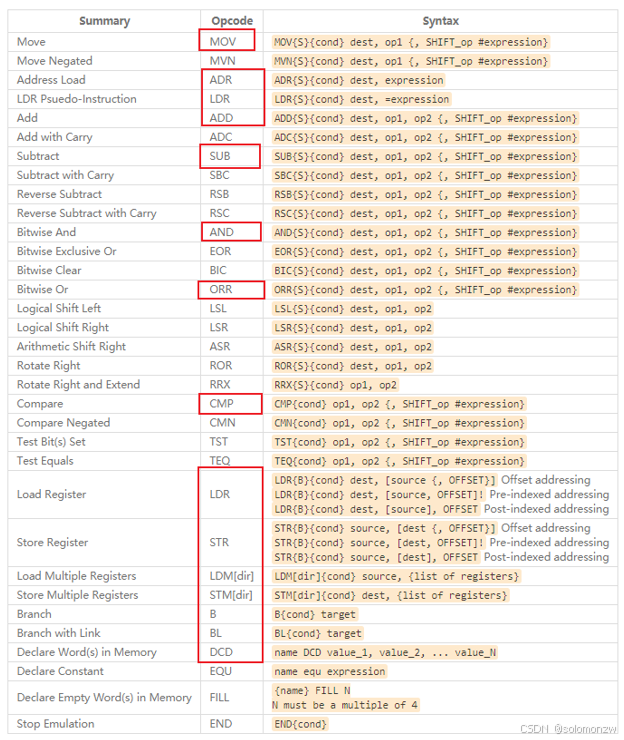
VisUAL支持的汇编指令
注意:右图中的DCD、FILL、END等是ARM汇编器语法GCC汇编语法稍有不同,后面会介绍。
 VisUAL
VisUAL
VisUAL设置
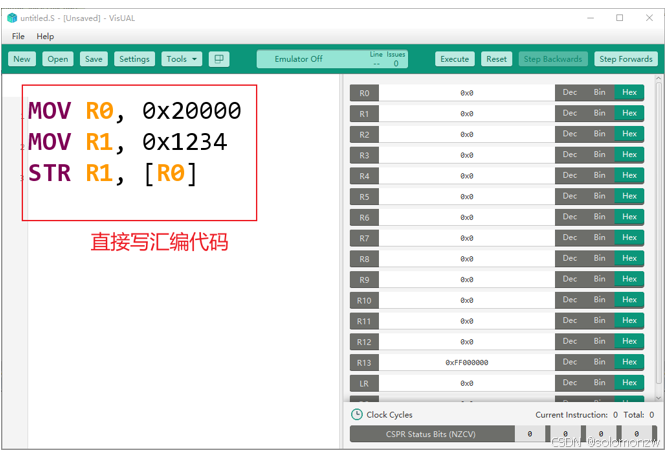
编写汇编指令
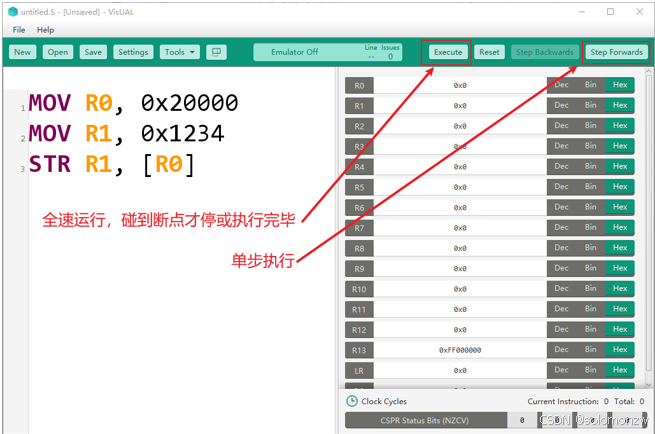
运行
修改错误
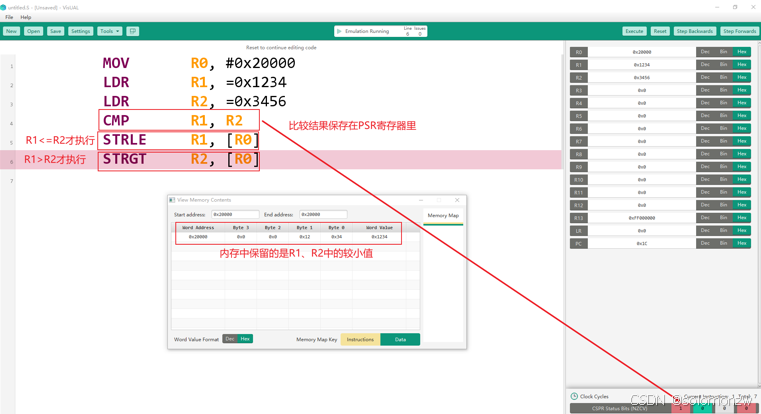
点击“Reset”后修改为:MOV R0, #0x20000 MOV R1, #0x1234
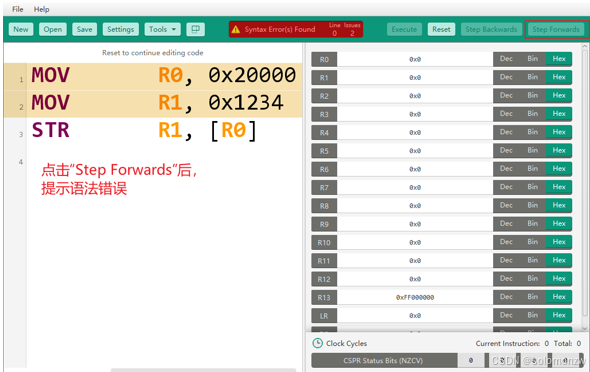
修改运行错误
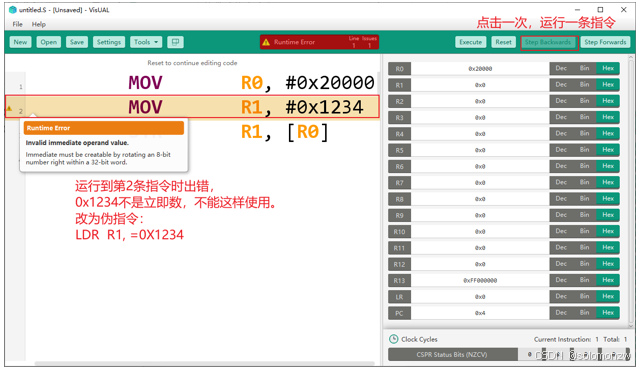
点击“Reset”后,才能修改:
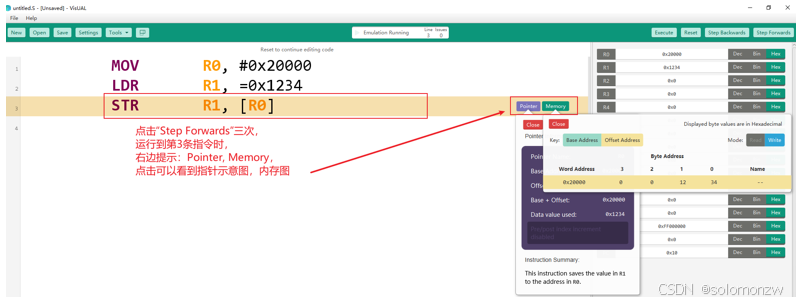
查看指针、内存
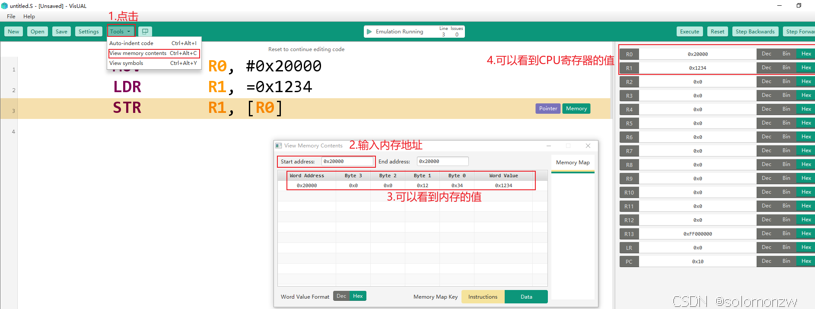
工具
稍微复杂点的汇编程序
内存访问指令
读内存指令LDR/LDM:参考《DEN0013D_cortex_a_series_PG.pdf》P340、P341
写内存指令STR/STM:参考《DEN0013D_cortex_a_series_PG.pdf》P377、P378
LDR:Load Register;LDM:Load Multiple Register;
STR:Store Register;STM:Store Multiple Register。



addr_mode:IA - Increment After, 每次传输后才增加Rn的值(默认,可省)
IB - Increment Before, 每次传输前就增加Rn的值(ARM指令才能用)
DA – Decrement After, 每次传输后才减小Rn的值(ARM指令才能用)
DB – Decrement Before, 每次传输前就减小Rn的值
! : 表示修改后的Rn值会写入Rn寄存器, 如果没有"!", 指令执行完后Rn恢复/保持原值
^ : 会影响CPSR, 在讲异常时再细讲
LDR/STR

示例:
MOV R0, #0x20000
MOV R1, #0x10
MOV R2, #0x12
STR R2, [R0] ; R2的值存到R0所示地址
STR R2, [R0, #4] ; R2的值存到R0+4所示地址
STR R2, [R0, #8]! ; R2的值存到R0+8所示地址,
R0=R0+8STR R2, [R0, R1] ; R2的值存到R0+R1所示地址
STR R2, [R0, R1, LSL #4] ; R2的值存到R0+(R1<<4)所示地址
STR R2, [R0], #0X20 ; R2的值存到R0所示地址, R0=R0+0x20
MOV R2, #0x34
STR R2, [R0] ; R2的值存到R0所示地址
LDR R3, [R0], +R1, LSL #1 ; R3的值等于R0+(R1<<1)所示地址上的值
LDM/STM
 LDM/STM的地址模式
LDM/STM的地址模式
好的!我来用最通俗的方式解释这段 ARM 汇编中的 **stm 指令和 地址模式**,保证你秒懂!👇
1. 核心概念:stm 指令的作用
-
stm(Store Multiple)的作用是:把多个寄存器的值,一口气存到连续的内存地址中**。 - 比如要把
R1=1, R2=2, R3=3存到内存中,可以用stm一次性完成,不用写多条指令。
2. 地址增长方向:递增 or 递减?
- 递增(Increment):内存地址从低到高增长(比如
0x1000 → 0x1004 → 0x1008)。 - 递减(Decrement):内存地址从高到低减少(比如
0x1008 → 0x1004 → 0x1000)。
3. 传输顺序:传输前 or 传输后改变地址?
假设基地址寄存器是 Rn(比如 R0):
- Before(传输前改变):先更新
Rn的值,再用新地址存数据。 - After(传输后改变):先用当前地址存数据,再更新
Rn的值。
4. 四种模式的直观对比
以下用 R0=0x1000 为例,假设要存 R1, R2, R3:
| 模式 | 全称 | 操作顺序 | 内存地址顺序 | R0 最终值 |
|---|---|---|---|---|
| IA | Increment After | 存完数据后,地址递增 | 0x1000, 0x1004, 0x1008 | 0x100C |
| IB | Increment Before | 存数据前,地址递增(ARM指令专用) | 0x1004, 0x1008, 0x100C | 0x100C |
| DA | Decrement After | 存完数据后,地址递减(ARM指令专用) | 0x1000, 0xFFC, 0xFF8 | 0xFF4 |
| DB | Decrement Before | 存数据前,地址递减 | 0xFFC, 0xFF8, 0xFF4 | 0xFF4 |
5. ! 的作用:是否更新基地址寄存器
- 有
!:指令执行后,Rn的值会更新为最新的地址(比如上表中的“最终值”)。 - 无
!:Rn的值会保持原值(比如R0始终是 0x1000)。
例子:
stmdb R0!, {R1-R3} @ 存完数据后,R0 的值会变成最终地址
stmdb R0, {R1-R3} @ 存完数据后,R0 的值还是原来的值6. ^ 的作用(简单版)
- 一般情况下不用管,它和异常处理(比如中断)有关,会影响当前程序状态寄存器(
CPSR)。 - 暂时记住:如果看到
^,说明这段代码可能在处理异常(比如从中断返回)。
7. 实际例子(结合源码)
假设源码中有类似代码:
stmib R0!, {R1-R3} @ 1. 先增加 R0 的值,再存数据- 操作步骤:
R0原值是 0x1000。- 传输前,
R0先增加(假设每个寄存器占 4 字节):R0 = R0 + 4 = 0x1004
- 把
R1存到0x1004。 R0继续增加:0x1008,存R2。R0增加到0x100C,存R3。- 因为用了
!,最终R0 = 0x1010。
总结
- IA(默认):边存边往后走,适合顺序存储。
- DB:先倒车再存数据,适合栈操作(比如满递减栈)。
-
!:如果想自动更新指针(比如循环中),一定要加! -
^:暂时忽略,以后学异常再研究。
这样是不是清楚多了? 😊

栈的4种方式


一、满减栈的核心特点
-
“满”的含义
- 栈指针(SP)始终指向最后一个有效数据。例如,若栈中有5个数据,SP会指向第5个数据的地址(而不是下一个空位)。这意味着压栈时需先移动SP腾出空间,再存入数据;弹栈时先取出数据,再移动SP恢复空间
-
“减”的含义
- 栈向低地址方向增长(即SP值减小)。例如,初始SP为
0x2000,压入4字节数据后,SP变为0x1FFC,下次压栈继续向更小的地址扩展
- 栈向低地址方向增长(即SP值减小)。例如,初始SP为
二、STMFD指令:压栈操作
STMFD sp!, {r0-r5} ; 将r0到r5寄存器的值压入满减栈-
执行步骤
- 先递减SP:根据寄存器数量(6个寄存器 × 4字节 = 24字节),SP先减24字节,指向新的栈顶位置。
- 按寄存器编号逆序存储:从高编号寄存器到低编号依次存入。例如,
r5存入新SP指向的地址,随后是r4、r3...直到r0
-
内存变化示例
- 假设初始SP为
0x2000,执行后:- SP先减24字节 →
0x1FE8 - 数据存储顺序:
r5→0x1FE8,r4→0x1FEC,...,r0→0x1FFC
- SP先减24字节 →
- 假设初始SP为
三、LDMFD指令:弹栈操作
LDMFD sp!, {r0-r5} ; 从满减栈中弹出数据到r0到r5-
执行步骤
- 按寄存器编号顺序加载:从当前SP指向的地址开始,依次加载数据到
r0、r1...r5。 - 后递增SP:加载完成后,SP增加24字节,恢复压栈前的栈顶位置
- 按寄存器编号顺序加载:从当前SP指向的地址开始,依次加载数据到
-
内存变化示例
- 假设当前SP为
0x1FE8,执行后:- 数据加载顺序:
r0←0x1FE8,r1←0x1FEC,...,r5←0x1FFC - SP最终增加24字节 →
0x2000(恢复初始值)
- 数据加载顺序:
- 假设当前SP为
四、为何指令名是STMFD/LDMFD?
- STMDB/LDMIA的等价性:
STMFD的全称是Store Multiple Full Descending,等同于STMDB(Store Multiple Decrement Before)。LDMFD的全称是Load Multiple Full Descending,等同于LDMIA(Load Multiple Increment After)
- 后缀含义:
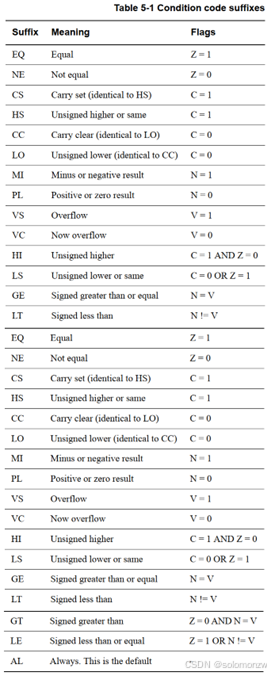
FD表示“满减栈”,直接对应硬件支持的栈类型,符合ARM标准调用约定(AAPCS)
五、实际代码示例解析
STMFD sp!, {r0-r5} ; 压栈
LDMFD sp!, {r0-r5} ; 弹栈- 压栈效果:将
r0-r5的值按逆序存入栈中,且SP指向栈底(最后一个有效数据)。 - 弹栈效果:按正序从栈中恢复
r0-r5的值,SP回到压栈前的位置。 - 注意:寄存器的写入/加载顺序看似相反,但这是为了保证数据后进先出(LIFO),符合栈的特性
六、满减栈的优势
- 硬件高效性:
STMDB和LDMIA的组合能高效处理连续内存操作,与CPU流水线优化兼容 - 内存安全性:栈向低地址扩展,堆向高地址扩展,避免两者内存区域重叠
- 调试友好:栈溢出时SP会指向非法低地址,易被调试工具检测(如MMU触发异常)
数据处理指令
RISC

数据处理指令简介
参考《DEN0013D_cortex_a_series_PG.pdf》P70、《ARM Cortex-M3与Cortex-M4权威指南.pdf》第5章以“数据处理”指令为例,UAL汇编格式为:
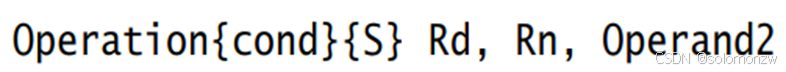
Operation表示各类汇编指令,比如ADD、MOV;如下图:
cond有多种取值,如下:
练习几条数据处理指令

程序状态寄存器中的位
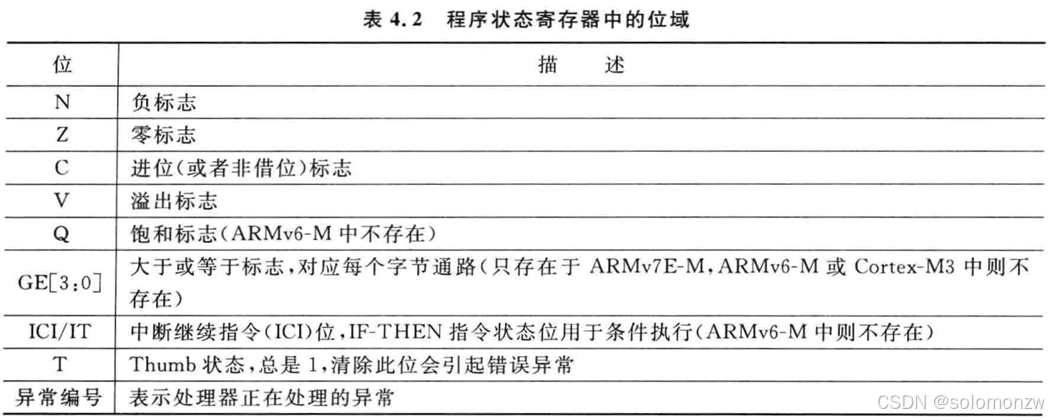

跳转指令
RISC
跳转指令简介

分支/跳转指令

练习几条跳转指令

 \
\
也可以给PC直接赋值

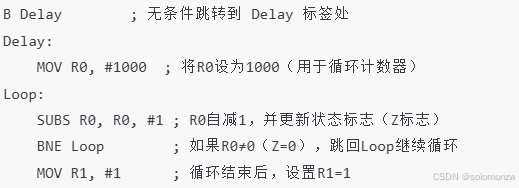
1. 调用延时子程序
ADR LR, Ret ; 伪指令:将Ret标签的地址存入LR(链接寄存器),作为返回地址
ADR PC, Delay ; 伪指令:将Delay标签的地址存入PC(程序计数器),跳转到延时子程序- 关键操作:
ADR LR, Ret:将Ret标签的地址(即MOV R1, #1的地址)保存到 LR寄存器,记录函数返回位置。ADR PC, Delay:将Delay标签的地址加载到 PC寄存器,直接跳转到延时子程序。
2. 主程序返回点(Ret)
Ret
MOV R1, #1 ; 延时结束后返回此处,设置R1=1- 功能:延时子程序结束后,程序通过
MOV PC, LR返回到此处继续执行。
3. 延时子程序(Delay)
Delay
MOV RO, #1000 ; 初始化RO(应为R0)为1000,作为循环计数器
Loop
SUBS RO, RO, #1 ; RO自减1,并更新状态标志(Z标志)
BNE Loop ; 若RO≠0(Z=0),跳回Loop继续循环
MOV PC, LR ; 循环结束后,将LR的值赋给PC,返回主程序(Ret标签处)- 关键操作:
SUBS:减法指令,同时更新状态寄存器(当RO减到0时,Z标志置1)。BNE:条件跳转指令(Branch if Not Equal),在RO≠0时继续循环。MOV PC, LR:将LR中保存的返回地址(Ret)赋给PC,实现子程序返回。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









