






前言
在上一篇文章中,我们(1)构建了小区详细信息数据结构。(2)改造了爬虫文件lianjiaxiaoqu.py,将解析页面逻辑封装成方法,并根据链家页面组织结构改造了parse()方法。进而获得了单个小区详细信息。在这篇文章中,我们将(1)继续改造lianjiaxiaoqu.py,获得北京建造时间距今二十年内的全部小区信息。
1. 获取全部小区信息
首先分析链家页面组织结构,构造爬虫入口地址(1)通过爬虫入口地址获得链家小区展示页面,勾选页面中楼龄在二十年以内的小区,页面头部和尾部展示如下:
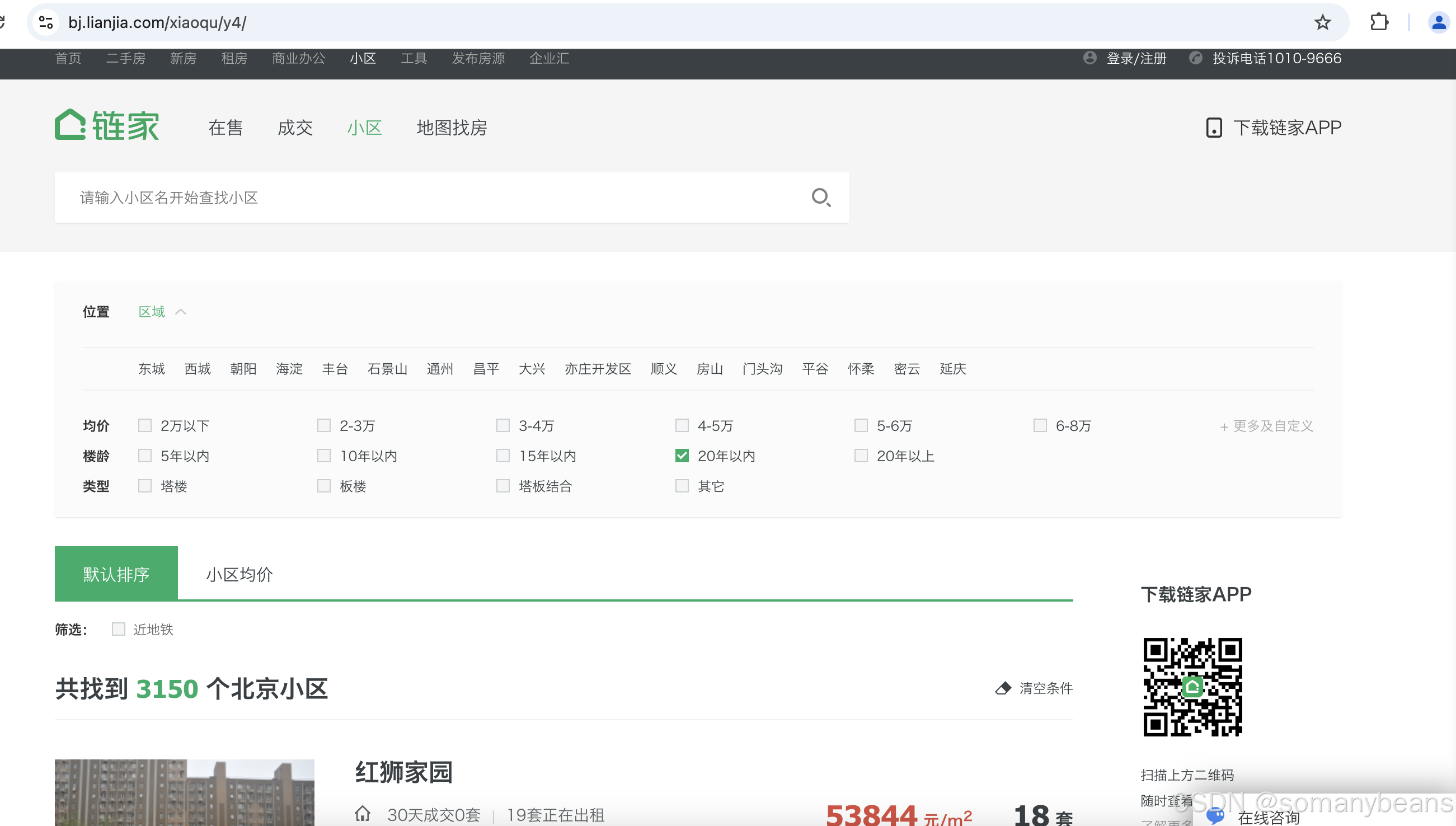
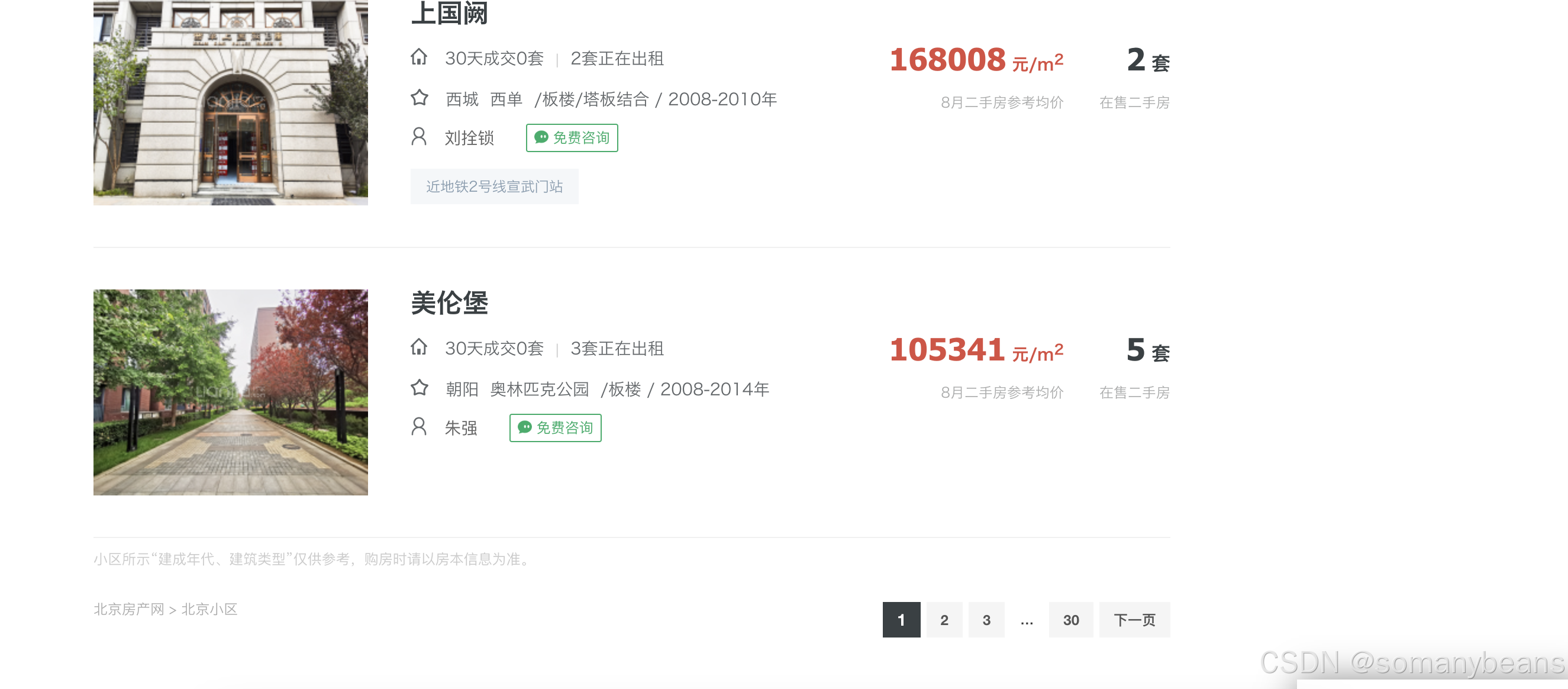
从上述两张图中可以获知如下信息:(1)可以将爬虫入口地址更改为“bj.lianjia.com/xiaoqu/y4” 。(2)多个小区分页展示,可以通过修改入口地址实现分页,比如“bj.lianjia.com/xiaoqu/pg3y4”代表第3页。“bj.lianjia.com/xiaoqu/pg4y4”代表第4页。其次改造lianjiaxiaoqu.py如下:
import scrapy
from lianjia.items import XiaoquItem
class LianjiaxiaoquSpider(scrapy.Spider):
name = "lianjiaxiaoqu"
allowed_domains = ["lianjia.com"]
start_urls = ["https://bj.lianjia.com/xiaoqu/pg{}y4/".format(i) for i in range(1, 31)]
def parse(self, response):
urls = response.xpath('//div[@class="info"]/div[@class="title"]/a/@href').extract()
for url in urls:
yield scrapy.Request(url, callback=self.parse_info)
def parse_info(self, response):
item = XiaoquItem()
item['xiao_id'] = response.url.split('/')[-2]
item["xiao_name"] = response.xpath(
'//div[@class="xiaoquDetailHeaderContent clear"]/div[@class="detailHeader fl"]/h1/text()').extract_first()
item["position"] = response.xpath(
'//div[@class="xiaoquDetailHeaderContent clear"]/div[@class="detailHeader fl"]/div[@class="detailDesc"]/text()').extract_first()
item["average_price"] = response.xpath(
'//div[@class="xiaoquPrice clear"]/div[@class="fl"]/span[@class="xiaoquUnitPrice"]/text()').extract_first()
item["total_house"] = response.xpath(
'//div[@class="xiaoquInfoItemMulty"]/div[@class="xiaoquInfoItemCol"][1]/div[@class="xiaoquInfoItem"][2]/span[@class="xiaoquInfoContent"]/text()').extract_first()
item["complete_year"] = response.xpath(
'//div[@class="xiaoquInfoItemMulty"]/div[@class="xiaoquInfoItemCol"][2]/div[@class="xiaoquInfoItem"][2]/span[@class="xiaoquInfoContent"]/text()').extract_first()
item["right_type"] = response.xpath(
'//div[@class="xiaoquInfoItemMulty"]/div[@class="xiaoquInfoItemCol"][2]/div[@class="xiaoquInfoItem"][1]/span[@class="xiaoquInfoContent"]/text()').extract_first()
item["heat"] = response.xpath(
'//div[@class="xiaoquInfoItemMulty"]/div[@class="xiaoquInfoItemCol"][2]/div[@class="xiaoquInfoItem"][3]/span[@class="xiaoquInfoContent"]/text()').extract_first()
item["developer"] = response.xpath(
'//div[@class="xiaoquInfoItemOneLine"]/div[@class="xiaoquInfoItem outerItem"][4]/span[@class="xiaoquInfoContent outer"]/text()').extract_first()
item["total_building"] = response.xpath(
'//div[@class="xiaoquInfoItemMulty"]/div[@class="xiaoquInfoItemCol"][1]/div[@class="xiaoquInfoItem"][3]/span[@class="xiaoquInfoContent"]/text()').extract_first()
item["water"] = response.xpath(
'//div[@class="xiaoquInfoItemMulty"]/div[@class="xiaoquInfoItemCol"][2]/div[@class="xiaoquInfoItem"][4]/span[@class="xiaoquInfoContent"]/text()').extract_first()
item["electricity"] = response.xpath(
'//div[@class="xiaoquInfoItemMulty"]/div[@class="xiaoquInfoItemCol"][2]/div[@class="xiaoquInfoItem"][5]/span[@class="xiaoquInfoContent"]/text()').extract_first()
item["green_ratio"] = response.xpath(
'//div[@class="xiaoquInfoItemMulty"]/div[@class="xiaoquInfoItemCol"][1]/div[@class="xiaoquInfoItem"][4]/span[@class="xiaoquInfoContent"]/text()').extract_first()
item["plot_ratio"] = response.xpath(
'//div[@class="xiaoquInfoItemMulty"]/div[@class="xiaoquInfoItemCol"][1]/div[@class="xiaoquInfoItem"][5]/span[@class="xiaoquInfoContent"]/text()').extract_first()
print(item)
相较于文章(二)中该文件, (1)修改了爬虫起始页面start_urls,通过循环方式构造30个页面地址,分别代表三十个小区展示页面。(2)在parse()方法中,构造三十次请求,并等待响应。(3)parse_info()保持不变。
运行该爬虫,在控制台得到如下输出结果:
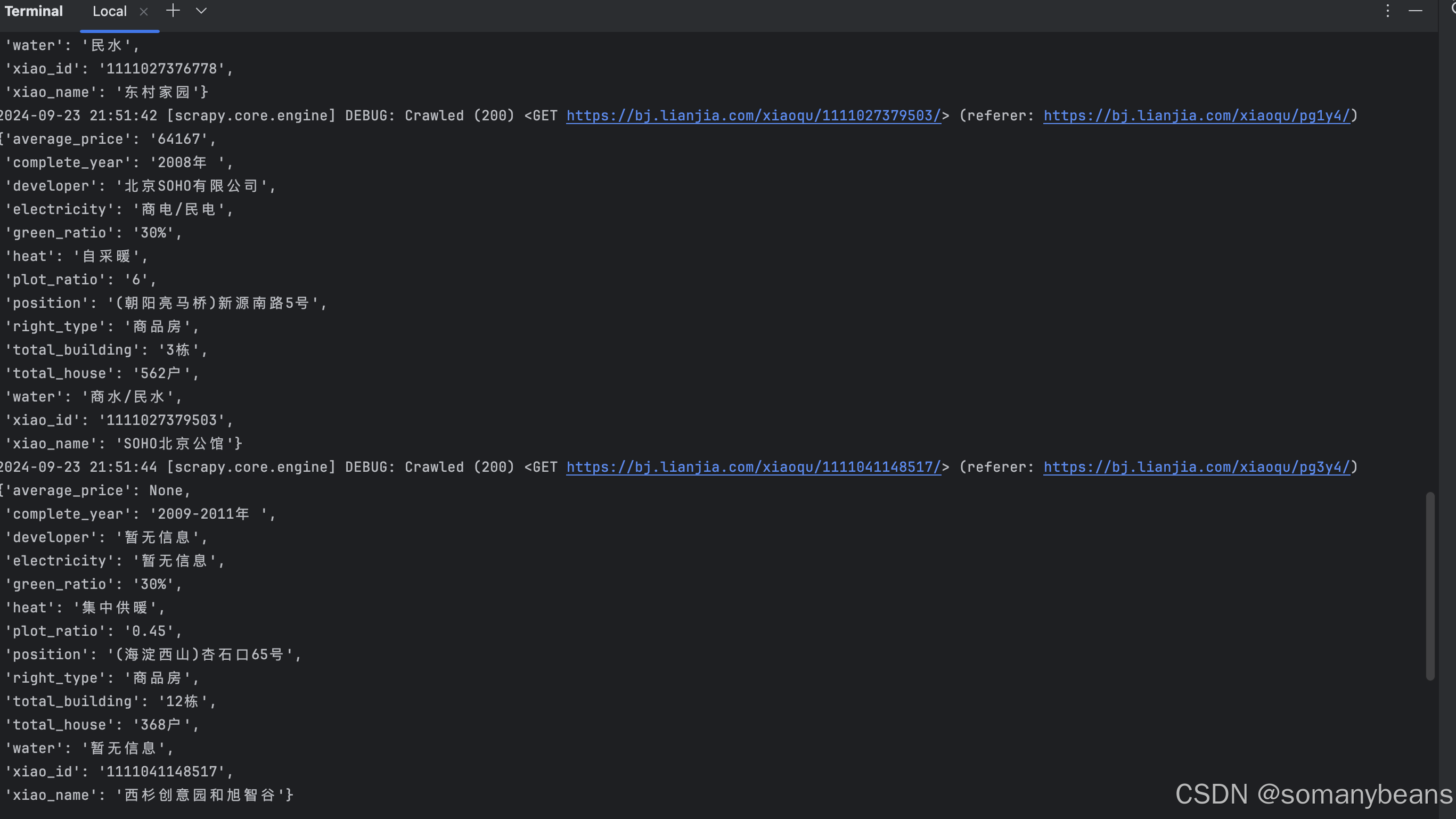
通过运行结果得知,我们连续获取了所有页面中全部小区详细信息。
2. 总结
通过上述内容,我们获取了链家页面展示建造年龄在二十年内的全部小区详细信息。有的朋友在实际操作中,可能并不能完整获取30页全部小区,大部分情况下,爬虫运行两三分钟后,控制台中都会出现302重定向到人机认证页面。这是因为我们触发了链家网的反爬机制。在下一篇文章中,我们将重点解析笔者在实际编码过程中解决反爬机制的过程。
就上述内容有任何问题,欢迎留言。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









