






前言
在上一篇文章中,我们获取了链家页面展示建造年龄在二十年内的全部小区详细信息。但是在爬取过程中,我们会触发链家的反爬机制,将爬虫入口页面重定向到人机验证页面。当触发人机验证时,控制台显示如下:
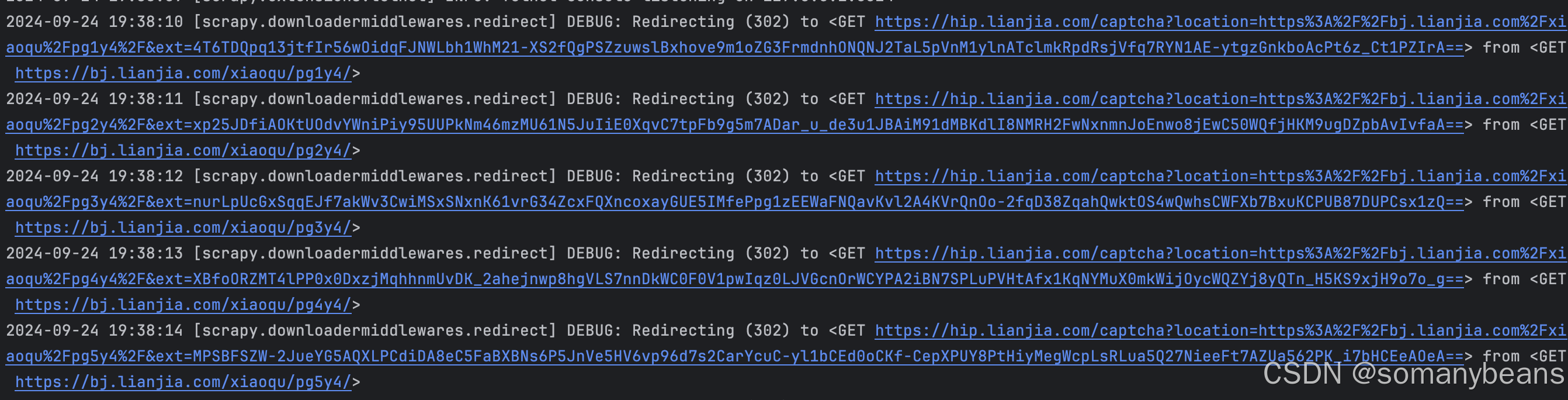
点击链接后,页面显示如下:
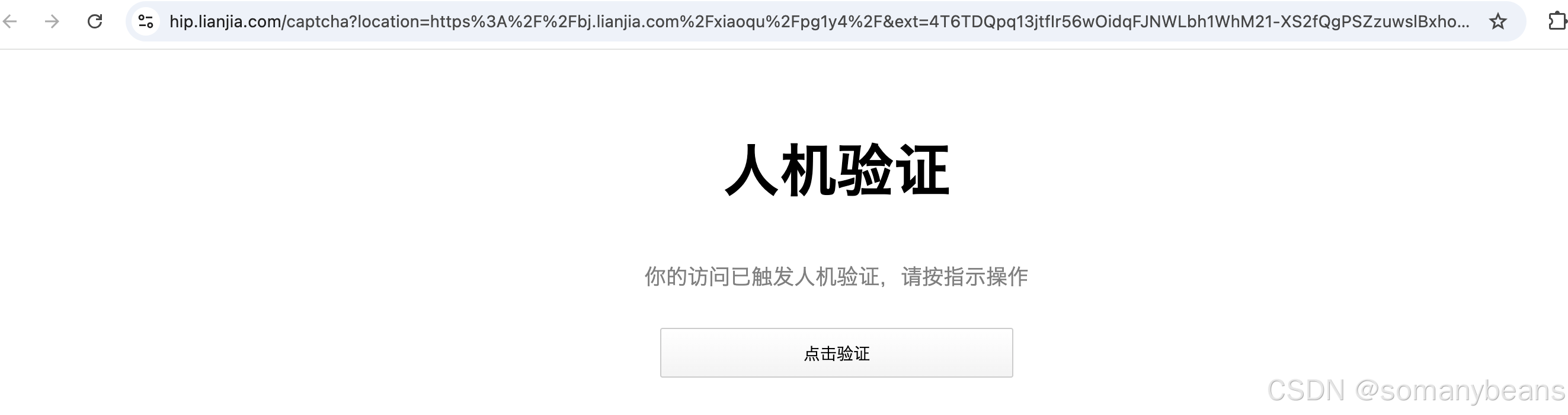
本篇文章将详细讲述使用动态ip解决上述问题的过程。
1. 设置User-Agent
User-Agent是HTTP请求头的一部分,包含浏览器和系统信息,用于标识访问者。服务器可能根据User-Agent识别并阻止爬虫。要查看浏览器的User-Agent,可打开开发者工具,点击Network,然后查看Headers中的User-Agent字段。它通常格式为Mozilla/5.0 (平台) 引擎版本浏览器版本号,例如Chrome的User-Agent显示其WebKit历史和版本详情。
对于爬虫程序来说,修改请求头中的User-Agent是通识。在Scrapy中,通过Scrapy源码我们可以发现User-Agent默认值为“Scrapy”:
class UserAgentMiddleware:
"""This middleware allows spiders to override the user_agent"""
def __init__(self, user_agent="Scrapy"):
self.user_agent = user_agent
该默认值和正常人为操作浏览器产生的User-Agent相差甚远,很容易被服务器识别并拒绝该类型请求,因此我们需要修改默认请求头,在Scrapy框架中,通常采用以下两种方式修改请求头:(1)在settings.py文件中设置,本案例采取该方式,因此在settings.py文件任意位置增加内容如下:
# 设置UA
import random
USER_AGENT_LIST = [
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6',
'Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)',
'Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
]
USER_AGENT = random.choice(USER_AGENT_LIST)该部分逻辑很好理解,首先引入random 包,其次在网上搜索一些主流版本浏览器请求头User-Agent格式,最后每次请求时随机挑选一个User-Agent。改种逻辑有很多衍生实现,比如将列表更换成随机生成User-Agent第三方工具包等等。
(2)第二种方法为将修改User-Agent的逻辑放入中间件中,如果选取该方式,需要在middlewares.py文件中增加如下内容:
import random
class UserAgentMiddleware(object):
def __init__(self):
self.user_agent_list = [
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6',
'Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322; .NET CLR 2.0.50727)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.11 (KHTML, like Gecko) Chrome/23.0.1271.64 Safari/537.11',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1; Trident/4.0; SV1; QQDownload 732; .NET4.0C; .NET4.0E; 360SE)',
'Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) Chrome/19.0.1036.7 Safari/535.20',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6',
'Mozilla/5.0 (X11; U; Linux x86_64; zh-CN; rv:1.9.2.10) Gecko/20100922 Ubuntu/10.10 (maverick) Firefox/3.6.10',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.71 Safari/537.1 LBBROWSER',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; Media Center PC 5.0; .NET CLR 3.0.04506)',
'Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.8.0.12) Gecko/20070731 Ubuntu/dapper-security Firefox/1.5.0.12',
'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; QQDownload 732; .NET4.0C; .NET4.0E; LBBROWSER)',
'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
]
def process_request(self,request,spider):
request.headers['USER_AGENT']=random.choice(self.user_agent_list)然后启用该中间件,启用方式为在settings.py中增加如下代码:
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'lianjia.middlewares.UserAgentMiddleware': 543,
}2. 增加动态ip机制
修改请求头只能让我们发起正常的http请求,但是并不能掩饰我们的真实身份,即客户端的ip。因此服务端在短时间内接收到大量同一客户端发起的请求,就会拒绝服务,将我们的请求重定向到人机校验页面。 为了不断“更换”客户端ip,需要引入动态ip代理机制,将我运行爬虫的客户端和链家服务器之间引入一层正向代理。首先在middlewares.py中间件中加入以下类:
class LianjiaProxyMiddleware(object):
def __init__(self):
self.proxies = self.get_proxy()
threading.Thread(target=self.cron_update_proxies).start()
def process_request(self, request, spider):
print("进入proxymiddleware")
if len(self.proxies) == 0:
self.update_proxies()
time.sleep(1)
proxy = random.choice(self.proxies).strip()
request.meta['proxy'] = "https://" + proxy
request.meta['dont_redirect'] = True
return None
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
print(response.status, '*****middleware-return*****')
if not response.text:
print("wrong response")
lian_utils.lian_exception_urls.append(response.url)
if response.status != 200:
if response.status == 302:
self.proxies = []
return request
else:
return response
def process_exception(self, request, exception, spider):
if str(exception).find('407') != -1:
self.proxies = []
return request
else:
return request
def get_proxy(self):
response = requests.get('https://xxxx.xxxx.xxxx.xxxx/get?key=DAB0748D&num=1')
if response.status_code == 200:
res_data = response.json()
proxys = []
if res_data['code'] == "SUCCESS":
for p in res_data['data']:
proxys.append(p['server'])
return proxys
else:
return []
def update_proxies(self):
self.proxies = []
self.proxies = self.get_proxy()
def cron_update_proxies(self):
sched = BlockingScheduler()
sched.add_job(self.update_proxies, 'interval', seconds=30)
sched.start()在该类中,核心思路为(1)获得代理ip。(2)周期性更新代理ip。(3)如果周期内代理ip失效,则马上更代理ip。具体实现为(1)cron_update_proxies方法为周期性任务,即每隔30秒执行update_proxies。(2)update_proxies方法作用为全量更新代理ip列表。(3)get_proxy方法作用为获取代理ip。(4)其余逻辑放入中间件必须实现的类中。(5)很多免费代理现在并不稳定,本案例使用了付费代理,因此在实际运行过程中请根据实际情况修改get_proxy方法。
其次在settings.py中启用该中间件:
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'lianjia.middlewares.LianjiaProxyMiddleware': 100,
'lianjia.middlewares.UserAgentMiddleware': 543,
}3. 总结
通过上述两步,我们(1)构造了“正常”的http请求。(2)每隔30秒更换一次“马甲”。可以愉快的绕开链家反爬机制,获取全部小区数据了。在下一篇文章中,我们将把爬取到的数据记录到mysql数据库中。

















 529
529

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









